(论文)[2022-EGSR] Spatiotemporal Blue Noise Masks
Spatiotemporal Blue Noise Masks
- 蓝噪声:能够降低低频噪声
- 本文:时间、空间上都是蓝噪声【传统时间上不是】
- 扩展到 temporal
- 仓库
Introduction
- 目前一般是空间 Blue Noise + TAA(EMA)
- 两大类蓝噪声方法
- sets of blue noise distributed sample points
- masks containing values in an image【本文是这个】
- 我们支持任意 pdf【也就是说支持重要性采样】
- 针对实时渲染【优先蓝噪声质量,再考率收敛性】
- 蓝噪声 + 降噪效果有提升
- 使用我们的 mask 效果更好
- limitation:收敛性比白噪声差
- 只有在不动的像素好
相关工作
- 生成蓝噪声 mask【不考虑时间轴】
- scaler:void and cluster
- vector:Georgiev and Fajardo
- 蓝噪声的提升会随着样本数、样本维度增加而降低
- 很多工作都是收敛性、质量的 trade off
背景知识
Void and Cluster Algorithm
- scalar
- 算法目的
- 生成一张 mask,对于任意的阈值切割得到的二值图像,都是一张满足蓝噪音分布的图片
- 算法实现,每个像素维护
- 一个布尔变量【表示这个像素是否被 turn on】
- 一个索引 index,表示这个像素被 turn on 的顺序
- 用于生成图片,index 从小到大,对应 black => white
- turn on 像素 \(p\) 的能量辐射
- 总能量(推荐设置:\(\sigma=1.5\)),高斯核函数【这里 \(\in M\) 就表示状态为 on】
\[ F(p) = \sum_{q \in M} E(p, q) = \sum \exp\left(-\frac{\|p - q\|^2}{2\sigma^2}\right) \]
- mask 的总能量
\[ E(M) = \sum_{p,q \in M} E(p, q) = \sum \exp\left(-\frac{\|p - q\|^2}{2\sigma^2}\right) \]
- 总共有 3 ordering phases
Phase 1
- 目的:得到一个高质量的二值蓝噪声 mask
- 随机 turn on 一部分像素【小于一半】
- 反复执行如下操作,直到两者找到的像素相同【收敛】
- 在状态为 on 的像素中找到 \(F(p)\)
最大的像素,turn off
- turn off the tightest cluster pixel,\(\arg\max_{p\in M}F(p)\)
- 在状态为 off 的像素中找到 \(F(p)\)
最小的像素,turn on
- turn on the largest void pixel,\(\arg\min_{p\in M}F(p)\)
- 在状态为 on 的像素中找到 \(F(p)\)
最大的像素,turn off
- 按照 \(F(p)\) 从大到小,逐个 turn
off 像素,并将这些像素的索引设置为状态为 on 的像素个数
- 这个步骤的目的就是建立索引
- 结束之后把刚刚 turn off(即有索引的像素)的像素再 turn on
Phase 2
- 目的:生成较暗部分的 ordering
- 反复执行如下操作,直到状态为 on 的像素数量到达一半
- 在状态为 off 的像素中找到 \(F(p)\) 最小的像素,turn on,并接着上面的索引顺次标号
Phase 3
- 目的:处理较亮部分
- 切换所有像素的 on/off 状态【感觉这个转换是为了降低计算复杂度,\(M\) 越来越小】
- 反复执行如下操作,所有像素状态都为 off
- 在状态为 on 的像素中找到 \(F(p)\) 最大的像素,turn off,并接着上面的索引顺次标号
End
- 此时所有的像素都有一个索引,把这个索引除以总像素数量,便映射到了
\([0,1)\) 的浮点图片蓝噪声 mask
- 对于 k-bit 图,再映射到 \([0, 2^k)\)
Swap Algorithm
- vector
- 定义图片总能量【高斯核函数】
- \(p,q\) 表示坐标位置
- \(V_p,V_q\) 表示保存的 vector 值
\[ E(M) = \sum_{p \neq q} E(p, q) = \sum_{p \neq q} \exp\left( -\frac{\Vert p - q\Vert^2}{\sigma_i^2} - \frac{\Vert V_p - V_q\Vert^{d/2}}{\sigma_s^2} \right) \]
- 参数设置
- \(\sigma_i=2.1,\sigma_s=1.0\)
- \(d/2\)
表示平均空间位置、保存值的权重
- 整理理解就是,想要不同维度中的值更接近、尺度平均
- 系数越大,减轻重要性
- 算法流程
- 使用白噪声初始化整张图片
- 重复操作
- 随机选中两个像素,如果交换两个像素能够让总能量下降,则交换他俩
- 可控参数
- error threshold
- maximum swap count
Spatiotemporal Blue Noise Masks
- STBN
- V&C 快
- swap 慢,但是能够支持 general vector、importance-sampled masks
- STBN 可定制
Scalar Valued Masks
- 一个像素一个随机数
- 重新定义能量函数
- \(p=(p_{xy},p_z)=(p_x,p_y,p_z)\)
\[ E(p, q) = \begin{cases} \exp\left(-\dfrac{\Vert{p-q}\Vert^2}{2\sigma^2}\right), & \text{if } p_{xy} = q_{xy} \text{ or } p_z = q_z \\ 0, & \text{otherwise} \end{cases} \]
- 可视化:STBN 能量函数只考虑当前像素的值在空间上【\(z\) 相同】或者时间上【\(xy\) 相同】是蓝噪声
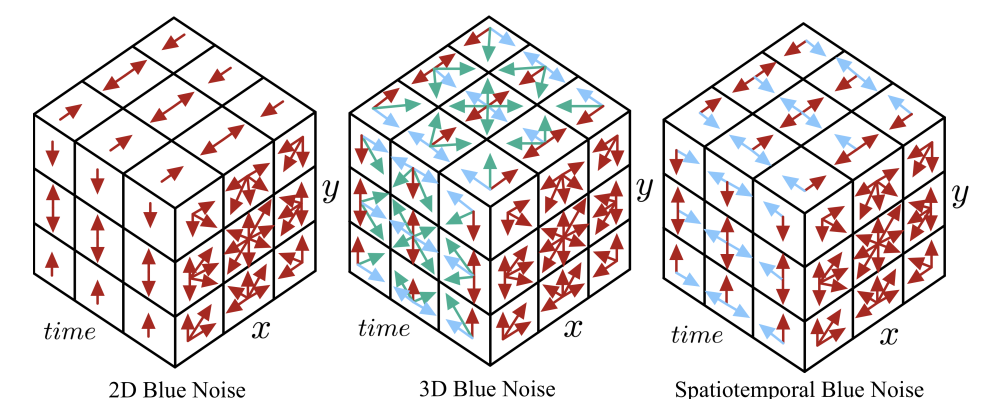
- 参数
- 初始化二值图片的时候,赋值 10% 像素
- \(\sigma=1.9\)
Vector Valued Masks
- 类似的修改能量函数
\[ E(p,q) = \begin{cases} \exp\left( -\dfrac{\Vert p-q\Vert^2}{\sigma_i^2} - \dfrac{\Vert V_p - V_q\Vert^{d/3}}{\sigma_s^2} \right), & \text{if } p_{xy} = q_{xy} \text{ or } p_z = q_z \\[1.5em] 0, & \text{otherwise} \end{cases} \]
- \(d/2\) 变成 \(d/3\):现在 \(p,q\) 是 3d 的
- 思考上,类似于第一项得乘 \(3/2\)
- 这个方法也能生成 scalar mask【但是比 V&C 慢】
结合重要性采样
- 初始纹理可以使用重要性采样生成,可以把 pdf 也保存到其中的 channel 里面【或者推导得到】
- 不太理解,这样经过 swap 之后还能好吗?
分析
- 分析:频域特征、误差、收敛性
Scalar
- 1d 函数积分:ramp(斜坡函数)、sine、step
- 实验:EMA;累计
- spatial error 低的同时,收敛性也好
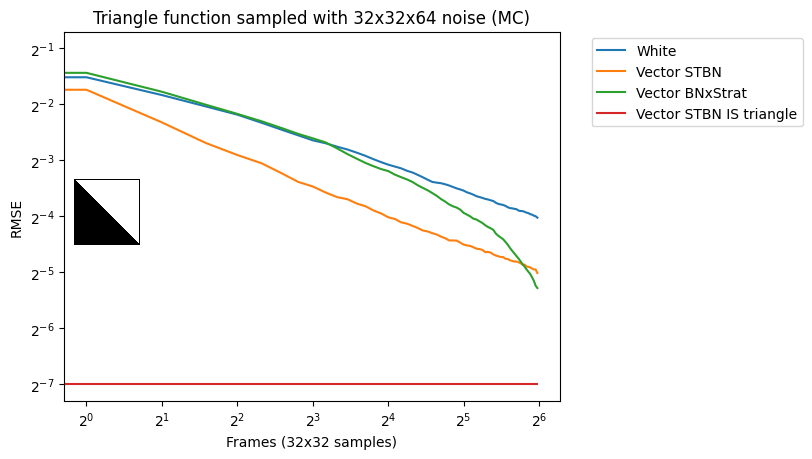
Vector
- 测试了多种 Vector、同时测试了重要性采样【Cosine-Weighted、skybox image】
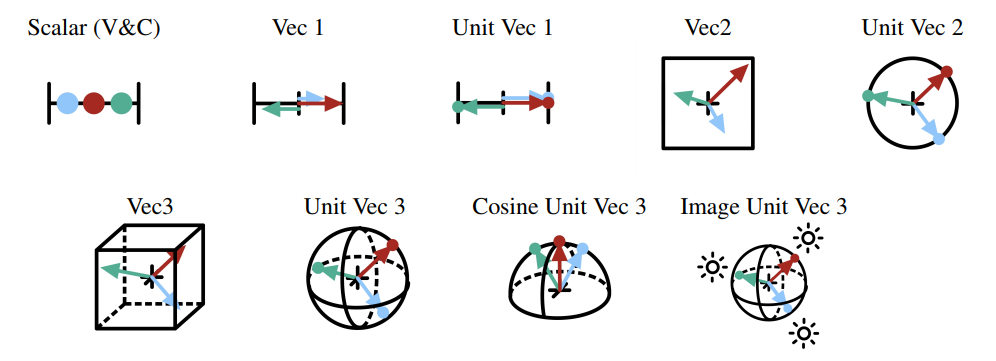
- V&C 生成 scalar 质量高,但是只能生成 scalar,而且不能结合重要性采样
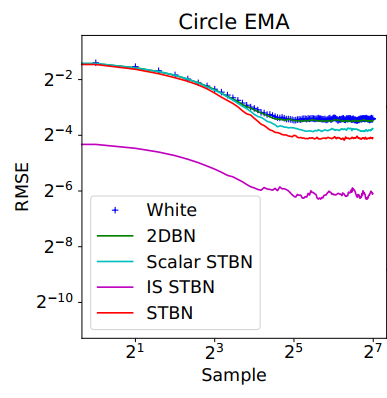
- 收敛速度:2d 函数积分(circle、gauss、step)
- EMA;累计
- 这个重要性采样效果感觉有点猛【但是没有跟白噪的重要性采样比?】
TAA
- 对于低差异序列,大部分好的随机数都在开头;STBN
任意张蓝噪声贴图开始都好【toroidally progressive】
- 在 TAA 失败的时候,STBN 效果好
- STBN 序列是绑定在像素上的,在像素移动的时候,STBN
没有跟着移动,因此会丢失时间上的蓝噪属性
- STBN 没有迁移序列
- 累计收敛测试:White×Sobol 最好
- TAA + EMA
- 静态像素 STBN 效果都是最好的
- 动态和 Vec2 Blue2D x White 差不多
Properties After Spatiotemporal Filtering
- STBN 收敛比 spatial blue2d 快
结果
Scalar Masks-Volumetric Rendering
- 各向异性体渲染,单次散射
- STBN,RMSE 降低 36%
Vector Masks: Ambient Occlusion
- three-dimensional unit vector
- 他的 AO 计算方式
- AO 的值插值得到【ray hit length = \(t\),AO 值为 \(t/t_{\max}\)】
- 另外再乘上 cosine weight
- STBN:质量、收敛性都更好
- 感觉这个加上 cosine-weighted 重要性采样会更好
Importance Sampled Vector Masks: StochasticConvolution
- 多个卷积核,采样卷积核
Denoising
补充材料
Masks vs. Samples
- blue noise samples
- 输入是整数下标【表示需要第几个点】,返回点的坐标
- 所有的点画在二值图像上,做 DFT,展现出来的结果是蓝噪声
- blue noise masks
- 输入是整数坐标,返回 N 维向量
- 对于所有的坐标,返回的 N 维向量构成蓝噪声
- 【应用:需要给每一个像素提供一个随机数;samples 做不到】

Rendering 应用
- 蓝噪图片比白噪看着更舒服
- 加上 Gaussian Blur 之后变得平滑,蓝噪更好了
更多结果
- Stochastic Transparency
- 4 帧累计 / 64 帧 EMA 后,STBN 效果显著好
- Dithering
- 把量化误差转化为噪声
- Volumetric Rendering
- Preserving Blue Noise Over Time
扩展
Getting Multiple Values Per Pixel
- 例如每帧多个样本
- 简单处理:随着样本数 advance z 轴,而不是随着 frame index
- 相邻像素具有相关性【差别很大】,但是随着距离增大,相关性消失
- 读取多个 offset 的样本
Higher Dimensional STBN
- 这里的指的 Dimension 就是纹理尺寸【例如 128x128x64,大小为 128x128 的纹理,64 帧】
- D 的一个划分为 \(G\),那么 STBN 只需要在任意的 \(g\in G\) 中保持蓝噪声即可
- 定义 \(h\) 为不在 \(g\) 中的其他维度
- 那么能量函数如下
\[ E_g(p,q) = \begin{cases} \exp\left(-\dfrac{\Vert p_g - q_g\|^2}{2\sigma_g^2}\right), & \text{if } p_h = q_h \\ 0, & \text{otherwise} \end{cases} \]
\[ E(p,q) = \sum_{g \in G} E_g(p,q) \]
\[ F(p) = \sum_{q \in M} E(p,q) \]
- 不同的 group 可以有不一样的 \(\sigma_g\)
- 其实距离的幂次也不一样
- 例如 128x128x64 的 STBN
- \(G=\{xy,z\}\)
- \(g=xy\) 时,\(h=z\)
- \(g=z\) 时,\(h=xy\)
- \(G=\{xy,z\}\)
- 耗时:8 bit 纹理
- 分辨率 \(O(n^2)\)

- 实时渲染 64x64x16 就够用了
Spatial BN Stratification Over Time
- 分层采样
- 例如原来是在 \([0,1]\) 均匀采样两个样本,分层采样则是子啊 \([0,0.5],[0.5,1]\) 中各采样一个样本
- 目的也是让样本分得开一点
- 分层采样的问题:需要所有样本都用上效果才好
- 不适配 TAA 中可能中断与重启的情形
Spatiotemporal Point Sets
- 给定一个阈值,我们的 STBN 可以生成 blue noise 点集
- 仅考虑 spatial,我们不是最好的【例如更好的 blue noise through optimal transport】
- 但是我们是第一个考虑 Spatial-Temporal 的
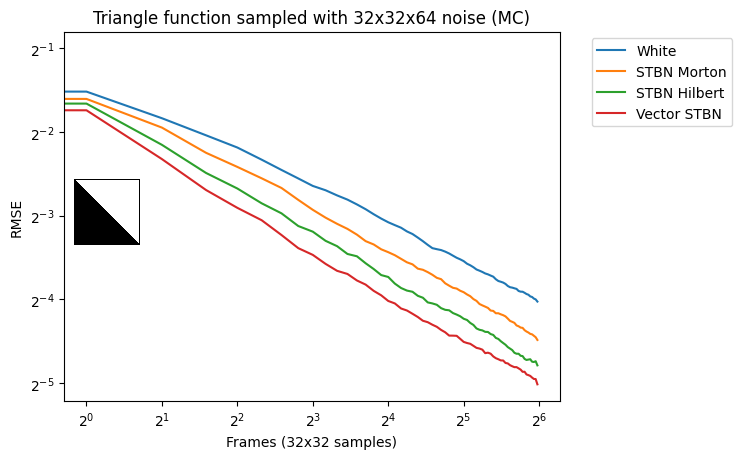
Curve Inversion
- 从 scalar 随机数生成 vector
- scalar spatiotemporal blue noise value + a spacefilling curve
- 生成很快,但是使用效果不如 STBN
- 正向:坐标 => Hilbert curves / Morton curves 坐标
- 归一化反向变换得到 vector
频谱分析
- 考虑一个具体像素的 1D 积分 \(f(y)\),N 样本 MC 估计如下
- \(s(\cdot)\) 是 sample pattern
\[ I_N=\frac{1}{N}\sum_{i=1}^{N}f(y_i)=\int s(y)f(y)\;\mathrm{d}y,\quad s(y)=\frac{1}{N}\sum_{i=1}^{N}\delta(y-y_i) \]
- 频域变换
\[ F(\omega)=\mathcal{F}\{f\}(\omega)=\int_{-\infty}^{\infty}f(y)e^{-i\omega y}\;\mathrm{d}y \]
\[ S(\omega)=\int_{-\infty}^{\infty}s(y)e^{-i\omega y}\;\mathrm{d}y \]
- 逆变换
\[ f(y) =\mathcal{F}^{-1}\{F\}(y) =\frac{1}{2\pi}\int_{-\infty}^{\infty}F(\omega)e^{i\omega y}\;\mathrm{d}\omega \]
- 对于任意函数 \(h(y)\),\(w=0\) 处的傅里叶变换
\[ H(0) = \int_{-\infty}^{\infty} h(y)e^{-i\cdot 0\cdot y}\;\mathrm{d}y = \int_{-\infty}^{\infty} h(y)\;\mathrm{d}y \]
- 令 \(h(x)=s(x)y(x)\)
\[ I_N=\mathcal{F}\{s(y)f(y)\}(0) \]
- Fourier transform 的乘积——卷积定理
- 时域中的乘积对应于频域中的卷积:\(\dfrac{1}{2\pi}\) 系数
- 时域中的卷积对应于频域中的乘积
\[ \mathcal{F}\{s(y)f(y)\}(\omega) =\frac{1}{2\pi}(S*F)(\omega) =\frac{1}{2\pi}\int_{-\infty}^{\infty}S(\xi)F(\omega-\xi)\;\mathrm{d}\xi \]
- 令 \(\omega=0\)
- 共轭对称性
- 后面的 \(\omega\) 是积分变量,不是原始的频域
\[ I_N =\frac{1}{2\pi}\int_{-\infty}^{\infty}S(\omega)F(-\omega)\;\mathrm{d}\omega =\frac{1}{2\pi}\int_{-\infty}^{\infty}S(\omega)F^{\ast}(\omega)\;\mathrm{d}\omega \]
- 之后讨论,和论文一致,忽略 \(\dfrac{1}{2\pi}\)
- 对 \(y_i\) 进行常数扰动 \(y_i+\gamma\)【应用里面,像素间的 \(\gamma\) 不同,例如蓝噪声扰动】
- 时域平移只改变频域相位【或者直接代进去算】
\[ s(y;\gamma) = s(y-\gamma) \]
\[ S(\omega;\gamma) = e^{-i\omega\gamma}S(\omega) \]
- 此时
- 【记号 \(G\)】
\[ I_N = \int S(\omega)F^*(\omega)e^{-i\omega\gamma}\;\mathrm{d}\omega = \int G(\omega)e^{-i\omega\gamma}\;\mathrm{d}\omega \]
- 这可以看成是一个傅里叶变换,那么对应的 \(g\) 就是逆变换结果【忽略常数】
\[ g(x) = \int G(\omega)e^{i\omega x}\;\mathrm{d}\omega = \int S(\omega)F^*(\omega)e^{i\omega x}\;\mathrm{d}\omega = s\otimes f \]
\[ I_N = g(-\gamma) \]
- 这个函数不仅分析了 \(I_N\) 的值,同时反应了他的误差
- 和之前工作一样,假定 \(f\)【因此 \(g\)】 在小 patch 里面是 constant
\[ I_N(x) = g\bigl(-\gamma(x)\bigr) \]
- 期望 \(I_N(x)\)
分布是蓝噪;因此使用蓝噪的 \(\gamma\)
- 这并不一定成立【因为经过了 \(g\) 变换】
- 理想情况,反解 \(g\)
- 期望目标蓝噪
\[ I_N(x) = g\bigl(-\gamma(x)\bigr) = \alpha(x) \]
- 输入噪声【省略负号】
\[ \gamma(x) = g^{-1}\bigl(\alpha(x)\bigr) \]
- 实际不可行,\(g\) 依赖于 \(f\)
- 使用 Heitz
and Belcour[2019] 的做法
- 只做排序意义上的逆函数求解【基于一个小的 block 实现,上面的 block 内部 \(f,g\) constant 假设】
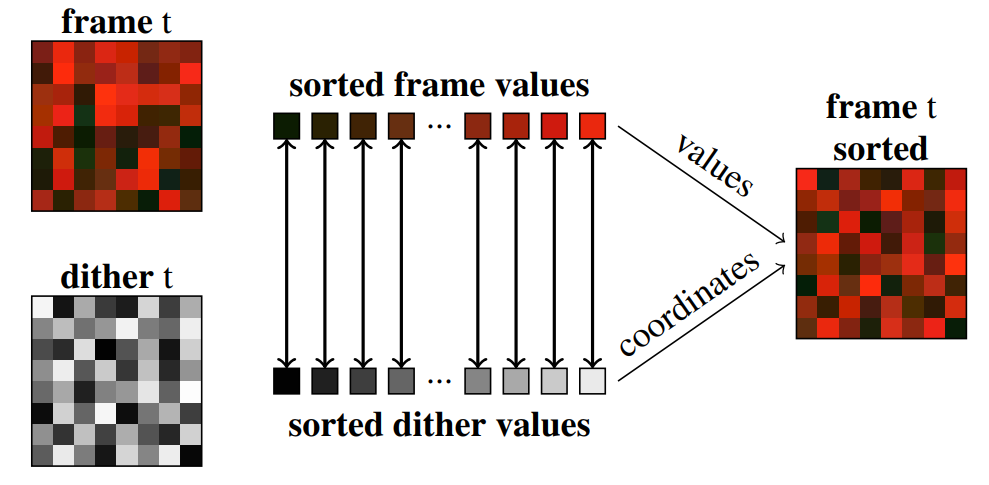
- dither:蓝噪声分布;frame t:原始结果
- 二者各自排序,使用 dither 的坐标对应 frame 的值,这样 frame
的结果就符合蓝噪声分布
- 假设:block 内部的 frame 值相同【实际没这么简单,论文中还有 retarget pass,用于解决帧间抖动问题;感觉 STBN 不需要这一步了】