(论文)[2025-SIGC] Kernel Predicting Neural Shadow Maps
Kernel Predicting Neural Shadow Maps
- XUEJUN HU, Tsinghua University, China
- 代码
- 单光源软阴影;神经网络估计一个 kernel 的权重,用权重进行 filter
摘要
- 2022 年的 NSM 直接估计值,泛化性差
- 我们估计权重,在屏幕空间做 filtering
- 能够实现
- 2048x1024 分辨率的阴影 >100 fps
- 泛化性好
- 时间稳定
Introduction
- 阴影算法:启发式容易出问题【漏光等】
- NSM:泛化性差
- 我们:假设软阴影能够被屏幕空间周围的像素加权平均得到
- 估计 weight 而不是 value
- UNet
- 可以结合已有的阴影算法【MSM】进一步加强效果
相关工作
- Shadow Mapping 算法【2 pass】
- 硬阴影;点光源或方向光
- Filtering-based soft-shadow
- 大部分是在 emitter space 做的
- Percentage closer filtering 【PCF】
- 采样阴影图中的周围像素(固定半径)
- Percentage closer soft shadows【PCSS】(搜索半径)
- variance shadow maps【VSM】
- convolution shadow maps【CSM】
- exponential shadow maps【ESM】
- moment shadow maps【MSM】
- Percentage closer filtering 【PCF】
- 大部分是在 emitter space 做的
- 有很多假设,例如 emitter、blocker、receiver 是平行的;失效后容易出问题
- NSM 估计值泛化性差
- 我们估计权重
- 值有界【被周围像素 bound 住】,训练稳定
- 误差小
- 泛化性好
Screen-Space Shadow Filtering
\[ e_i=\sum_{j\in N(i)}w_{ij}e_j \]
\[ \sum_{j\in N(i)}w_{ij}=1 \]
- 选择屏幕空间的原因:卷积操作和屏幕空间更适配
- 之前有人做过 screen-space percentage-closer soft shadows,但是我们使用神经网络自己预测权重,而不是手动设计核函数
- dilated filters(À-trous filters ):空洞卷积,用于减少参数量
- 阴影可能会有很大的半影,因此使用空洞卷积减少参数量
- 论文:使用 4 层 5x5 空洞卷积(空洞 0,1,3,7)
- 感受野 61x61
- 参数量变化:\(61*61=3721\Longrightarrow 4*5*5=100\)
- 看下面 pipeline的 子图 4
- 右向左分析
1 | 空洞 0 1 3 7 |
方法
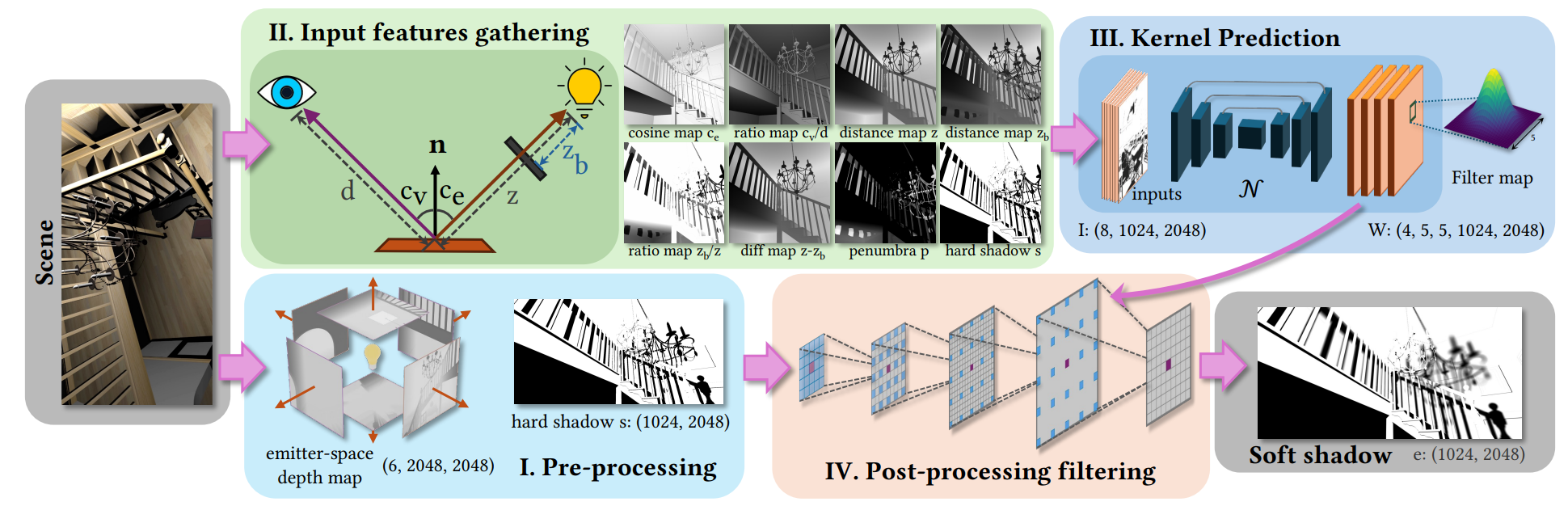
- 步骤:如果有多个光源,每个光源都需要重复着4个步骤
- Pre-processing:2 pass
- Input features gathering:在第 2 个 pass 收集网络输入信息
- Kernel Prediction:UNet 估计权重
- Post-processing filtering:在 base shadow image 上做 filtering
输入特征
8 张图
cosine map \(c_e\)
ratio map \(c_v/d\)
ratio map \(z_b/z\),difference map \(z-z_b\)
depth map \(z,z_b\)
半影大小 \(p\)【NSM 用的是光源大小】
硬阴影 \(s\)【NSM 没有这个】
NSM 输入是前 4 张图(\(c_e\Leftarrow r_e+c_e\))
这些都可以从第 2 个 pass 中得到
半影大小的计算
- 参考 PCSS:假设 emitter、blocker、receiver 是平行的
- pipeline 图中,相似三角形计算
\[ p_{pcss}=\frac{z-z_b}{z_b}\cdot R_e \]
- 投影到屏幕空间
- 投影到 local tangent plane,再投影到 screen-space
- 【这里的投影说实话我不太理解怎么推导的?不过论文实验结果表示用 \(p_{pcss}\) 效果也差不多】
\[ p = \sqrt{\left| \frac{c_v}{c_e} \right|} \cdot p_{pcss} = \sqrt{\left| \frac{c_v}{c_e} \right|} \cdot \frac{z - z_b}{z_b} \cdot R_e \]
- \(p\) 只有在阴影区域非 0
Kernel predicting networks
- 类似 NSM,使用 modified UNet
compact network structure
这个 NSM 其实也有
4 down-sample layers
channels:64,64,128,256
max pooling(上采样使用 transposed convolutions)
skip connection 使用 addition 而不是 concatenation(进一步减小内存)
支持高分辨率:减小计算量
- 外层的降采样修改为 pixel-shuffling down-sampling
- 直接进行一个重排,将超像素内值展开为通道:\(rW*rH*c\Rightarrow W*H*r^2c\)
torch.nn.PixelUnshuffle(downscale_factor)
- 上采样修改为 bilinear upsampling
- 外层的降采样修改为 pixel-shuffling down-sampling
示意:左到右是
PixelShuffle;右到左是PixelUnshuffle
![]()
- 1.81 M 训练参数
Loss
\[ \mathcal{L}=\mathcal{L}_{1}+\beta_{v}\mathcal{L}_{VGG}+\beta_{t}\mathcal{L}_{t}(V,V') \]
- \(\mathcal{L}_1\):阴影图的 L1 loss
- \(\mathcal{L}_{VGG}\):VGG loss
- \(\mathcal{L}_{t}(V,V')\):重投影后的
temporal loss【对输入进行微扰】
- \(\mathcal{W}\):重投影
- mask 掉重投影失败的 pixel
\[ \mathcal{L}_t(V, V') = \mathcal{L}_1(V, \mathcal{W}(V')) + \beta_{v} \mathcal{L}_{VGG}(V, \mathcal{W}(V')), \]
- NSM 中实现 temporal loss 是对输入进行微扰,但是 GT 不变
MSM 增强
- base shadow generator :从硬阴影 shadow mapping 修改为 MSM
- 效果更好
- 输入网络的特征也都从 MSM 中获取
- 效果提升非常大【基础好了,糊一糊就更好了】
- 利用了更多 emitter space 的信息
- MSM 输入 artifacts 更少,更平滑
- 这也是我们估计 kernel
权重对比估计值的好处:能够结合传统的阴影算法
- 感觉 NSM 也 ok,把 \(d\) 换成 MSM 就好了
- MSM 实现:4 order depth moments + bilinear 插值
数据集与实现
- 5 个场景,每个场景 6000 个配置
- 随机:相机位置、光源位置、光源半径
- GT:硬件光追 + MSAA
- 网络输入不用 MSAA;这样能让网络学习到 AA【NSM 一样】
- 实现
- Falcor 渲染
- Pytorch 训练:Adam,lr=\(10^{-3}\)【每 20000 iters,lr 除以 10】
- TensorRT 加速推理:将训练好的 pytorch 模型导入 TensorRT 进行推理
- 空洞卷积:训练使用 pytorch 的 unfold;推理在 compute shader 中实现
实验
- RTX 4090 GPU
- 渲染:2048x1024
- cube sahdow maps:6x2048x2048
- 我们
- our-basic:使用 shadow map 作为 base shadow generator
- our-enhanced:使用 MSM 作为 base shadow generator
- 对比算法:NSM【复现】、MSM、PCSS、
- NSM 泛化性差,用了两版
- NSM-joint 表示所有场景训练
- NSM-single 表示只在测试场景中训练
- MSM:4 阶,15x15 filter window,\(\sigma=3.0\)
- 作为 base shadow generator 则更加简单
- PCSS:64 样本用于 blocker search;128 样本用于估计阴影
- NSM 泛化性差,用了两版
主实验
- 耗时:8.9 ms【our-enhanced】
- 0.9 光栅化;6.4 网络推理;1.6 后处理
- 训练集中的 5 个场景
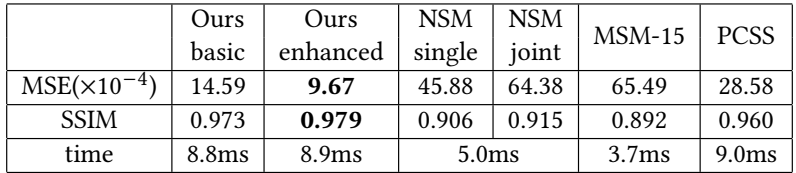
- 泛化性测试:在另外 5 个 unseen 场景测试
- 和硬件光追比【同时间】
- 数值上光追好,但是光追有肉眼可见的明显噪声

消融实验
- Varying sizes of light sources:我们软硬都好
- Base shadow generator:试了 SM、PCF【alias 多,不如 MSM】、MSM
- Network structure:网络层数、感受野大小
- Temporal Loss:视频所有像素所有帧计算 loss
- 这一帧投影到上一帧,计算重投影成功的像素值误差
\[ E_{temporal} = \sqrt{\frac{1}{(T - 1)HW} \sum_{t=1}^{T-1} \sum_{i=0}^{H-1} \sum_{j=0}^{W-1} \left( e^t_{i,j} - \mathcal{W}(e^{t-1})_{i,j} \right)^2} \]
- Penumbra width as an input feature
- 使用不同的光源大小编码方式
- 光源大小 \(R_e\);NSM 的编码方式 \(c_e+R_e\);使用 \(p_{pcss}\)【emitter space】
- 【实验结果表示用 \(p_{pcss}\) 效果也差不多】【这合理吗?是不是投影真算错了】

总结
- 后续
- 阴影复杂度和光源数量无关
- 引入显式的各向异性阴影核函数
- 其他应用:real-time indirect illumination