(论文)[2024-SIGA-C] Filtering-Based Reconstruction for Gradient-Domain Rendering
Filtering-Based Reconstruction for Gradient-Domain Rendering
- 作者
- DIFEI YAN, SHAOKUN ZHENG, LING-QI YAN, KUN XU
- 1、2、4:Tsinghua University
- 3:UC Santa Barbara
- DIFEI YAN, SHAOKUN ZHENG, LING-QI YAN, KUN XU
- project
- 简单来说就是降噪中,加入梯度信息作为指导
- 怎么用,就是用于来算 \(\mu_p-\mu_q\)?
- 出发点
- 梯度存在噪声,不能直接用
- 和降噪一样建模为 Kernel-Based 方法,将梯度域信息作为 Guidance
- 将 image domain 的信息(over blur 问题)和 gradient domain 的信息(噪声大)结合在一起
- 策略:层级结构,梯度加强
- 流程:如下图
- 优势:非学习方法;渐近无偏
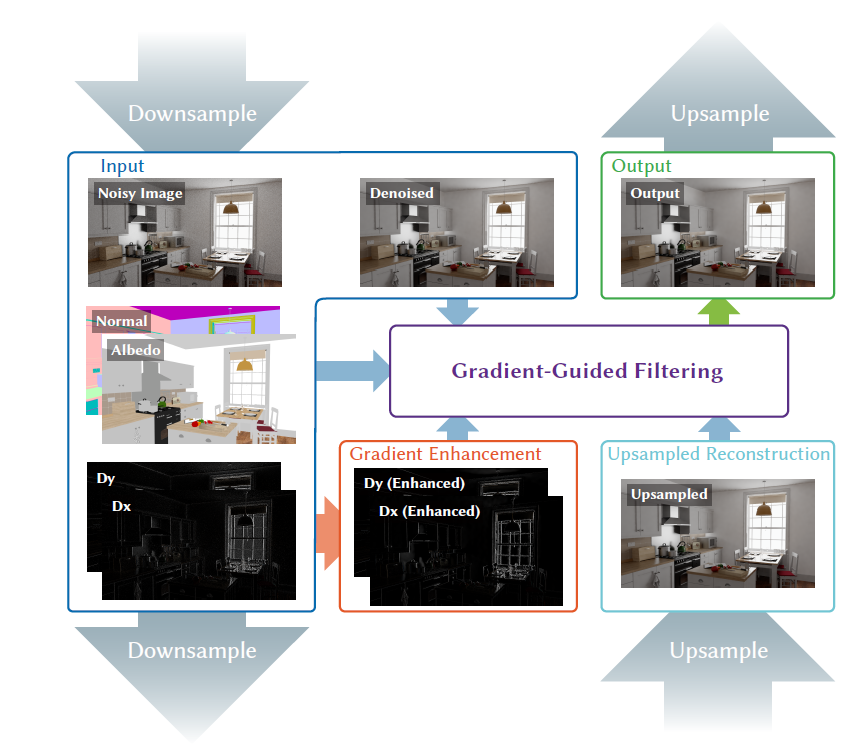
- 整体架构是一个金字塔架构,上下采样的权重通过 GLU【SIG-2023】的方式计算得到
- 在每一层内,进行梯度增强、Filtering 两个操作
- 梯度增强权重通过原始梯度图指导、GBuffer 监督得到
- 保留梯度较大、较小的值(sharp、smooth)
- GBuffer 变化小的地方梯度也要小
- Filtering
的权重通过增强后的梯度、GBuffer、降噪后的图片、上采样的结果监督【优化权重系数
\(w\)】
- MSE 小【降噪的流程,梯度只体现在这里的计算 \(\mu\) 真值?】
- \(w\) 用于重建 GBuffer 也要好
- \(w\) 重建上采样的图片应该和其本身差不多
- \(w\) 重建后的图片更加接近降噪后的图片
- 梯度增强权重通过原始梯度图指导、GBuffer 监督得到
相关工作
- 梯度域渲染:解 Poisson equation
- 梯度:first-order information about an image
- 问题:直接使用噪声很大的梯度信息,spiky artifacts
- Image-Space Reconstruction
- 一些 kernel-based 方法
- over-blurry 问题
- Image Upsampling
方法
- Gradient-PT:一条 base path,加上 deterministic shift mapping 之后的 offset path
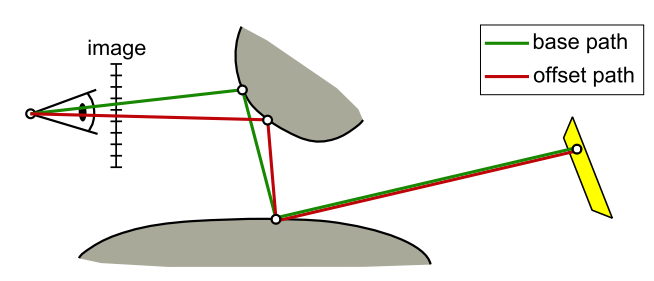
- 流程:PT 输出 noisy color \(\mathrm{I}_\text{b}\)、noisy gradient \(\mathrm{I}_\text{dx},\mathrm{I}_\text{dy}\)(不是简单相加减,需要 shift mapping )、GBuffer
\(\mathrm{F}\)
- 我们的过程:\(\mathrm{I}=G(\mathrm{I}_\text{b},\mathrm{I}_\text{dx},\mathrm{I}_\text{dy},\mathrm{F})\)
- \(\mathrm{G}\) 层级化
- 每一层:Gradient enhancement 、Gradient guided filtering
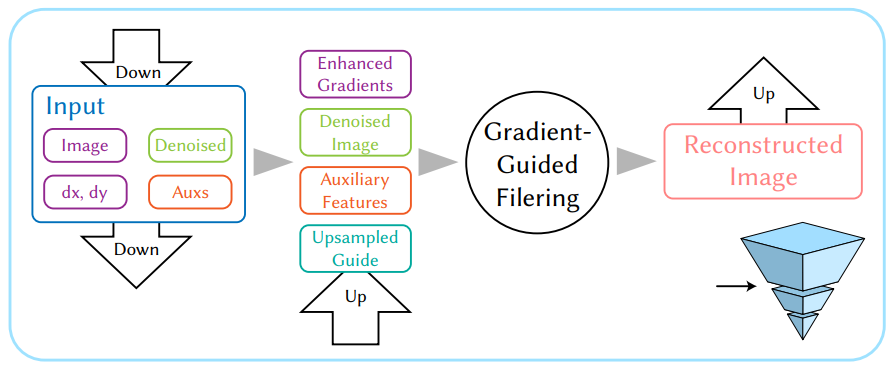
- 上下采样,输入图片 \(\mathrm{J}\),联合优化权重 \(W_d,W_u\)
- 细节见论文 Guided Linear Upsampling 【2023-SIG】
\[ \min_{W_{d},W_{u}}\Vert\mathrm{J}-\text{Up}(\text{Down}(\mathrm{J},W_d),W_u)\Vert \]
- \(\mathrm{J}\):9通道,降噪后的图片【只做一次,然后上下采样】、albedo、normal
- color 降噪:bilateral weights + non-local means (NLM) weights
- 3 组超参,然后使用 SURE 选出最优的一组结果
- color 降噪:bilateral weights + non-local means (NLM) weights
梯度增强
- \(\mathrm{I}_{\text{dx}}\to\hat{\mathrm I}_{\text{dx}}\)
- 梯度的两个问题:Invalid gradients、Spikes from outliers
- 需求:Valid、Extreme value preserving、Feature-aware
- valid
\[ \begin{array}{rl} \hat{\mathrm I}(i+1,j+1)-\hat{\mathrm{I}}(i,j)&=\hat{\mathrm{I}}_{\text{dx}}(i,j)+\hat{\mathrm{I}}_{\text{dy}}(i,j+1)\\ &=\hat{\mathrm{I}}_{\text{dy}}(i,j)+\hat{\mathrm{I}}_{\text{dx}}(i+1,j) \end{array} \]
- Color-guided regularization
- \(t=0.09\),控制最小权重
- 对勾,保留较小较大值(对应 smooth/sharp)
- \(\epsilon=0.01\)
- \(t=0.09\),控制最小权重
\[ \mathcal{L}_g=\sum_{\rho}\left(m_{x}(p)(\hat{\mathrm{I}}_{\mathrm{dx}}(p)-\mathrm{I}_{\mathrm{dx}}(p))^{2}+m_{y}(p)(\hat{\mathrm{I}}_{\mathrm{dy}}(p)-\mathrm{I}_{\mathrm{dy}}(p))^{2}\right) \]
\[ m_{x}(p)=\frac{|\mathrm{I}_{\mathrm{dx}}(p)|}{t}+\frac{1}{|\mathrm{I_{\mathrm{dx}}}(p)|+\epsilon}, m_{y}(p)=\frac{|\mathrm{I}_{\mathrm{dy}}(p)|}{t}+\frac{1}{|\mathrm{I_{\mathrm{dy}}}(p)|+\epsilon}, \]
- Feature-guided smoothing:希望 flat 的地方更加 smooth
- \(\mathrm{F}_{\mathrm{dx}}\):screen-space gradients of the feature maps,\(j\) 通道
- Gbuffer 梯度小的地方,希望实际梯度也小
- \(\epsilon=0.01\)
\[ \mathcal{L}_{f}=\sum_{p}\left(a_{x}(p)|\hat{\mathrm I}_{\mathrm{dx}}(p)|^{2}+a_{y}(p)|\hat{\mathrm I}_{\mathrm{dy}}(p)|^{2}\right)\! \]
\[ a_{x}(p)=\frac{1}{\sum_{j}|\mathrm{F}_{\mathrm{dx}}^{(j)}(p)|+\epsilon}, a_{y}(p)=\frac{1}{\sum_{j}|\mathrm{F}_{\mathrm{dy}}^{(j)}(p)|+\epsilon} \]
- 最终 loss
- \(\lambda_f=8/\sqrt{N}\)
- \(N\) spp,因为只有 \(\mathcal{L}_f\) 引入 bias,这样的表示能够渐近无偏
- \(\lambda_f=8/\sqrt{N}\)
\[ \min\mathcal{L}_{grad}=\mathcal{L}_g+\lambda_f\mathcal{L}_f \]
- 求解:convex,可以梯度下降
Gradient-Guided Filtering
- 建模为 kernel-based
- \(w_{q}\geq0,\sum_{q\in{\cal{N}}(p)}w_{q}=1\)
\[ \mathrm{I}(\rho)=\sum_{q\in{\cal{N}}(p)}w_{q}\mathrm{I}_{\mathrm{b}}(q) \]
- Gradient-guided loss:\(\text{MSE}=\text{Bias}^2+\text{Var}\)
- 无偏:\(\mu,v\)(但是实际上只能获取带噪声的估计)
- \(\mu_q-\mu_p\) 可以使用增强后的梯度计算,根据式子
\[ \begin{aligned} \mathcal{L}_{\text{opt}}&=\mathbb{E}\left[(\mathrm{I}(p)-\mu_p)^2\right]=\mathbb{E}\left[(\mathrm{I}(p)-\mu_p)\right]^2+\text{Var}\left[\mathrm{I}(p)-\mu_p\right]\\ &=\left(\sum_{q\in{\cal{N}}(p)}w_q(\mu_q-\mu_p)\right)^2+\sum_{q\in{\cal{N}}(p)}w_q^2v_q \end{aligned} \]
- Auxiliary self-regression loss: 减小噪声+保留边界,使用 GBuffer 自监督 \(w_q\)
\[ {\mathcal{L}}_{x}=\Biggl(\mathrm{F}_{x}(p)-\sum_{q\in N(p)}w_{q}\mathrm{F}_{x}(q)\Biggr)^{2},\quad x\in\{\mathrm{albedo,normal}\} \]
- 上采样自监督 \(w_q\)(上采样得到的 color 图片)
\[ \mathcal{L}_{\text{up}}=\Biggl(\mathrm{I}_{\text{up}}(p)-\sum_{q\in N(p)}w_{q}\mathrm{I}_{\text{up}}(q)\Biggr)^{2} \]
- 降噪监督(把降噪作为真值)
\[ \mathcal{L}_{\text{d}}=\Biggl(\mathrm{I}_{\text{d}}(p)-\sum_{q\in N(p)}w_{q}\mathrm{I}_{\text{b}}(q)\Biggr)^{2} \]
- 总 loss
- 二次凸函数,梯度下降求解
- 收敛性:\(\lambda_{\text{a}}=16/\sqrt{N},\lambda_{\text{n}}=0.16/\sqrt{N},\lambda_{\text{u}}=\lambda_{\text{d}}=8/\sqrt{N}\)
\[ \mathcal{L}= \lambda_{\text{a}}\mathcal{L}_{\text{opt}} +\lambda_{\text{a}}\mathcal{L}_{\text{albedo}} +\lambda_{\text{n}}\mathcal{L}_{\text{normal}} +\lambda_{\text{u}}\mathcal{L}_{\text{up}} +\lambda_{\text{d}}\mathcal{L}_{\text{d}} \]
实验
- AMD Ryzen 9 7950X CPU and an NVIDIA 3080Ti GPU
- 【2015】Gradient-PT
- LuisaRender 实现
- 1280 × 720
- 整个过程:5s
- 消融实验
- 金字塔层级:不同场景最优层级不一样,复杂的需要更多(2 - 4)
- 对比的时候,都用 2
- Guided Linear Upsampling (GLU) 策略:学习 vs 简单插值
- Gradient-Guided Filtering 中的每一个 loss 的重要性
- 金字塔层级:不同场景最优层级不一样,复杂的需要更多(2 - 4)
- 收敛性:比 NN 好
- 对比试验
- 梯度域:同 spp 效果好
- GradNet(800ms),如果 color、gradient 同时存在 outlier,那么除不掉
- NGPT (600ms),wave-like artifacts
- 降噪:同时间比较,因为输出梯度需要时间,对比算法获取的 spp 更多
- NFOR(filter-based,400ms)、AFGSA (learning-based,5s)、NPPD(吃内存多)
- 梯度域:同 spp 效果好