(论文)[2020-EG] Neural Temporal Adaptive Sampling and Denoising
Neural Temporal Adaptive Sampling and Denoising
- 主页
- Jon Hasselgren, Jacob Munkberg, Marco Salvi, Anjul Patney, Aaron
Lefohn
- NVIDIA
- We propose a novel method for temporal adaptive sampling and denoising of sparse Monte Carlo path traced animations at interactive rate
- 降噪 + 适应性采样,学习 spatial-temporal 联合分布,低样本下保持时间稳定性、提高出图质量
Intro
- 离线降噪
- CNN 为每个像素生成一个 filter kernel
- temporal:每一帧过一遍
- Adaptive sampling
- 【2018-ESGR】Deep Adaptive Sampling for Low Sample Count
Rendering,记作 DASR
- CNNx2:预测 sample density map、降噪采样图片
- 端到端联合优化,两个 CNN 相互辅助(eg. 降噪较弱的地方,多采样光线)
- 我们的方法基于此,将其扩展到时域上,实现 temporal stable
- 【2018-ESGR】Deep Adaptive Sampling for Low Sample Count
Rendering,记作 DASR
- interactive rates
- U-Net + recurrent convolutional blocks at each encoder level(慢)
- Spatiotemporal variance-guided filtering:效果和学习方法差不多,但是很快【启发式】
- 我们:interactive, temporally stable, adaptive sampling and
denoising
- 时域稳定性:只在降噪输出上坐做分辨率的 recurrence(而不是每层 encoder 都做)
- 使用 motion vector(视频领域用 optical flow)【效率关键】
- 问题转换:learn to track the motion of noisy image features \(\Rightarrow\) learn to detect where temporal reuse is appropriate
- 更容易了:10x 小的网络效果就不错
- interactive rates at 1080P
- 贡献:
- Temporally stable adaptive sampling at low sample counts.
- Adaptive sampling driven by warped temporal feedback instead of an initial sampling pass.
- An interactive, temporally-stable denoiser network based on hierarchical kernel prediction and warped temporal feedback, which is substantially faster and generates higher image quality than previous hierarchical recurrent denoisers.
- A scalable architecture with high image quality for larger networks, that still outperforms previous work while scaled down to real-time performance.

Our Approach
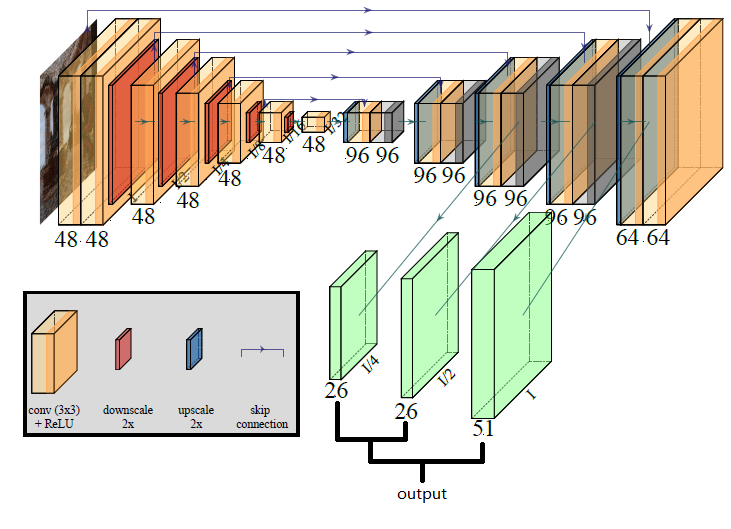
Networks
- sample map estimator、denoiser networks 都是 U-Net
- 绿色的 denoiser net 独有的
temporal reprojection
- primary intersection point 的 motion
vector,变换到上一帧之后,使用双线性插值(pytorch
grid_sample()方便实现)
Adaptive Sampler
- 输入:feature buffers + 重投影的结果(重投影到上一帧降噪后的结果)
- normals, depth, motion vectors and albedo at first hit
- 输出:softmax 归一化
- \(n\):spp,\(M\):像素数量
\[ \hat{s}(p)=\mathrm{round}\left(\frac{M\cdot e^{s(p)}}{\sum_{i=1}^{M}e^{s(i)}}\cdot n\right) \]
renderer 梯度传播
- 参考 DASR(数值计算)
Denoiser
- 输入:adaptively sampled noisy image + all inputs of the sampler network
- 输出:multi-scale kernel predicting network
- 每一层输出一个 5x5 的 kernel(25 通道)以及混合权重(1 通道);最细的部分额外输出一个 5x5 kernel(temporal)
- kernel 用法:应用到对应分辨率的 noisy image 上,作用后得到 \(\mathbf{i}\)
- \(\mathrm{\bf{i}}^c\):coarse 粗粒度图片
- \(\mathrm{\bf{i}}^f\):fine 细粒度图片
- \(\mathrm{\bf{D,U}}\):2x2-downsampling,nearest-neighbor upsampling
- 从粗到细递归调用(上图中有描述,右下角黑色部分【原图没有,我补的】)
\[ \mathrm{\bf{o}}_{p}={\bf{i}}_{p}^{f}-\alpha_{p}\left[\mathrm{\bf{UDi}}^{f}\right]_{p}+\alpha_{p}\left[\mathrm{\bf{Ui}}^{c}\right]_{p} \]
- temporal 5x5 应用到上一帧降噪后重投影的结果上
- 预测 kernel 比直接预测更加准确
Training
- 端到端:loss 只在最后计算
- recurrent term:5 帧
- 第一帧初始化:noisy uniformly sampled image at our target sample count.
- Loss:空间 L1、时间 L1;等权重
- \(x_i\):denoised;\(y_i\):ref
- \(\Delta y_{i}=y_i-y_{i-1}\)
\[ {\cal L}={\cal L}_{1}\,(x_{i},y_{i})+{\cal L}_{1}\,(\Delta x_{i},\Delta y_{i}) \]
实现
- PyTorch + Falcor
- 参数初始化:Xavier initialization
- Adam:0.001
- 1000 epoch
- 输入:clamp [0, 65535] \(\to\) \(x'=\log(x+1)^{1/2.2}\)
- adaptive sampling net:所有输入转成灰度(\(v=0.2989r+0.587g+0.114b\))
- adaptive sampling 应该与色度无关,只与噪声、几何、动画、遮挡等有关
- 训练
- 预先独立渲染 \(2^n,n\in[0,5]\) spp
的图片,然后组合使用(参考 DASR)
- 13 = 1 + 4 + 8
- 数据增强:裁剪、翻转、旋转90;随机打乱
- 直接预测的网络同时加上 hue permutations、grayscale augmentation
- 数据集
- 9 个场景 x 16-25 个动画(8 帧)
- ref:1k spp
- 预先独立渲染 \(2^n,n\in[0,5]\) spp
的图片,然后组合使用(参考 DASR)
- 测试:longer video clips and references with 4k spp
Results
- 最大贡献:temporal stable denoising
- metric:在 tonemap 之后计算 PSNR、tPSNR
- 从差到好,依次加入
- three-level hierarchical kernel prediction (KPN)
- temporal recurrence (Our uniform)
- adaptive sampling (Our adaptive)
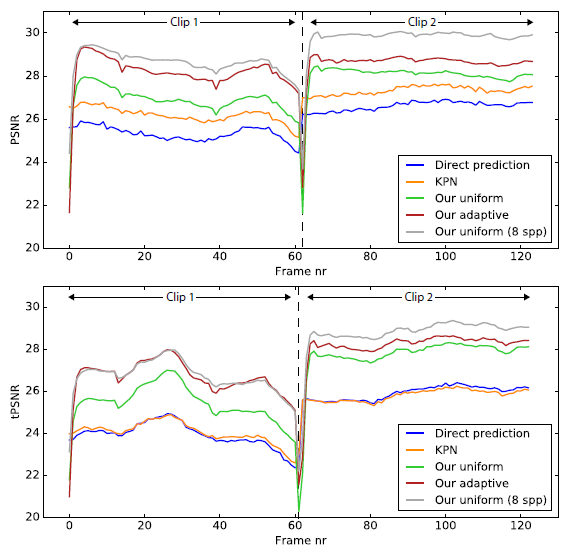
- 切换的过程中,存在不稳定(合理的)
- 对比算法
- recursive denoising autoencoders (RAE)
- deep adaptive sampling and reconstruction (DASR)
- 大光源、环境光泛化性问题,去掉了 visibility guide buffer
- spatiotemporal variance-guided filtering (SVGF)
- 我们训练过程中加入了重投影,因此就不需要额外 TAA 了(RAE 需要)
- rMSE
- 镜子问题:motion vector 失效,算的是镜子的而不是镜子中反射的
- 泛化性好
- 测试:只针对某个场景训练 vs 训练集中去除这个场景
- Performance and Scaling
- DASR 之外的负担:temporal recurrence loop and hierarchical kernel evaluation(<1ms)、重投影快(GPU texture lookup)
- trade off:质量与效率,网络模块大小
- 问题
- ghosting and the network tends to error on the side of aggressive temporal reuse
- View dependent shading effects, such as reflections, remain an open issue