(论文)[2023-HPG] Neural Intersection Function
TLDR
- 任务:估计 shadow ray 的返回值(可见、不可见)
- 传统求交:ray + BVH(TLAS+BLAS)
- NIF:ray+BVH(TLAS+MLP)
- 创新点
- 线程之间不存在 divergence
- 内存时间都可控,网络大小与场景复杂度无关
- 直接光照测试中达到 35% 的提升
- 论文的设置似乎无法求解这样的 shadow
ray,光源在物体内部,即光线和物体有交点,但是在 \(t_{\max}\) 之外
- 可见判定为不可见
Neural Intersection Function
- S. Fujieda C. C. Kao T. Harada
- AMD, Advanced Rendering Research Group (ARR)
- Advanced Micro Devices
- 论文主页
Introduction
- 论文中把 shadow ray 可见性测试称为 Ray casting
- 使用 BVH 进行可见性测试
- BVH traversal
- irregular algorithm
- divergence in memory access and branch execution
- GPU 不友好:Single-Instruction Multiple-Threads (SIMT) architectures
- 线程执行模式:lock-step
- 神经网络:MLP(全连接)
- regular algorithm
- 一致的指令
- predictable memory access pattern
- regular algorithm
- 本文贡献
- 提出 NIF,比 BVH Traversal 快
- ray casting 有效
- 验证了在直接光照中有提升
- NIF 的好处(和 BVH 相比)
- 更快了(没有 divergence)
- 网络占据的显存和场景大小无关
- 执行时间是稳定的
- NIF:位置 \(\to\) 可见性
Related Work
INRs
- 目标:reconstruct the 3D surface
- implicit neural representations (INRs)
- MLP
- 输入:3D position
- 输出
- distance to the surface of the shape
- or the density and emitted radiance
- or occupancy function
- 在训练好的基础上,再通过其他方法提取出表面(等值面)
- 又好又快很难
- 提高质量的方案有很多,可以分为两类
- 把表面分为 small patches(1个网络)
- 把空间划分为小的 region(每个 region 一个网络预测)
- NIF:全都要
- 两个网络:根据光线的起点是否在某一个 AABB 的内部分为 inner/outer
- AABB 具体指的是什么的 AABB:指的是物体的 AABB,也就是 TLAS 的叶子节点
- 每个网络:feature grid
- 注意是所有物体只有两个网络,而不是每个物体都有两个网络
- 两个网络:根据光线的起点是否在某一个 AABB 的内部分为 inner/outer
输入编码
- ray aliasing:沿着光线方向移动,结果不变
- 编码
- Plücker coordinates
- foot notation(垂足),笔记
- NIF:我们要判断出结果一样的 aliased rays(归类)
- 如果光线的起点是在 AABB 外面,那么就把光线起点移动到和 AABB 的交点
- 如果在内部,则反向延长到物体表面的交点上
- 一般来说都在物体表面,除了如下情况
Design
- 输入位置和方向,判断是否被物体挡住
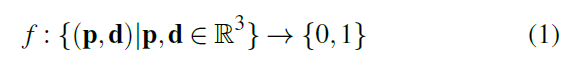
- 思路
- 先输出实数 \(v\in[0,1]\),表示可见的概率
- aliased ray 的处理:inner/outer NN
Outer Network
- 整体流程如下
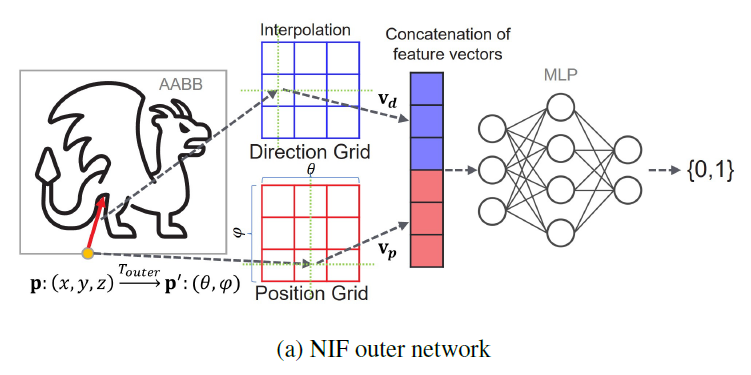
- 输入的参数化:\(\mathrm{p'},\mathrm{d'}\)
- \(\mathrm{p'}\)
- 首先将这个点转化为和 AABB 的交点(解决 aliased rays 的问题)
- 压缩,AABB 和一个球是双射的(concave),从 3D 转化为 2D
- 丢失了具体是哪一个 AABB
的信息?怎么区分是哪一个物体呢?
- 肯定都来自物体的 AABB 表面,可以对物体的 AABB 表面进行 UV 映射
- 论文:不同的物体之间共享网络,但是 Grid 不共享,如此便能区分
- 丢失了具体是哪一个 AABB
的信息?怎么区分是哪一个物体呢?

- \(\mathrm{d'}\):3D \(\to\) 2D
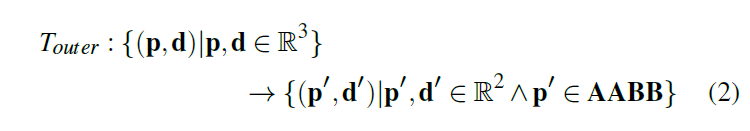
- 只是这样还不够,复杂的几何信息有高频信号
- Grid Encoding:上面的压缩使得只需要两个 2D 的 grid
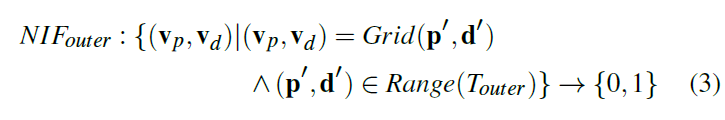
Inner Network
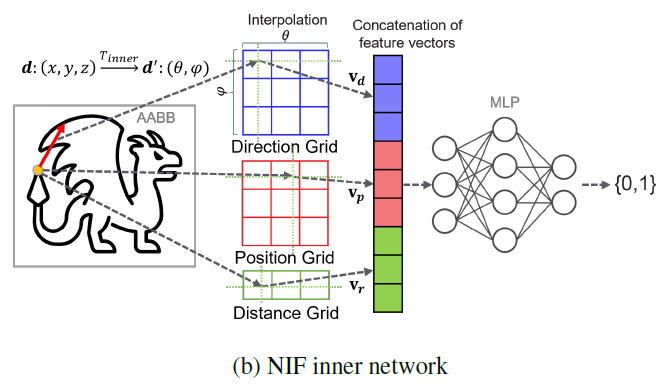
- 位置,方向:3D \(\to\) 2D
- 方向和之前一样
- 位置比较特殊,因为现在不是凸的了,AABB 的中心沿着一个方向可能有多个交点,因此还需要记录下到 AABB 中心的距离 \(\mathrm{r}'\)
- Grid Encoding:2D、2D、1D
- 这里相当于把原来的位置 3d Encoding 变成了 2d + 1d
- 这里的 Grid 和前面的不共享,一个 object 在 outer/inner 网络中各自有一组 Grid
Note
- 在这里例子中,只预测了可见性,但实际上可以预测其他的 surface
properties
- shading normal or texture coordinates
NIF in RT Pipeline
- Neural Intersection Function in Ray Tracing Pipeline
- NIF 用在 primary ray 去估计 shading normal、depth 等效果没有 BVH 好(质量比较差)
- 因此之后的讨论都集中在 secondary ray 做直接光照上
Embedding NIF
Embedding NIF to a Ray-Tracing Pipeline
two levels BVH
- 一个物体占据 TLAS 的一个叶子节点,一个物体的 Mesh 构成叶子节点对应的 BLAS
物体之间的复杂性相差越大,那么 BLAS 求交时 divergence 就越大
NIF 用于替代 BLAS
naive
- TLAS 正常遍历
- 当处理到叶子结点的时候,此时我们不遍历 BLAS,直接查询 NIF 网络获取结果
- 然后继续处理 TLAS 的其他节点,重复上面步骤直到遍历完成
优化,减少 divergence,increase overall GPU utilization
- 2-stage,两个 kernel 执行
- achieve maximum GPU occupancy,而且可以调整 kernel 的配置实现最优
流程如下
- 第一步
- 遍历 TLAS,找到所有相交的叶子节点(物体)
- 很快,TLAS 很小
- 第二步:NN execution
- 先执行 outer Network
- 再执行 inner Network
- 第一步
Training
- 两种模式
- online:当前视角的前几 spp 用于训练
- offline:多视角生成数据,然后预训练
Implementation
- AMD 自己的异构编程模型从底层开始写的
- The NNs in NIF are implemented from scratch using AMD C++ Heterogeneous-Compute Interface for Portability (HIP) in order to train and run inference on GPUs.
- 受到了 Muller 的 NRC(笔记) 论文的启发
- 网络只需要加载一次,保存到 shared memory 里
- 32/16-bit 浮点数
- Architecture
- outer network:2 hidden layers with 64 nodes each
- inner network:3 hidden layers with 48 nodes each
- 激活函数
- hidden:leaky ReLU activation
- last layer:sigmoid(visibility:0-1,<0.5即为可见)
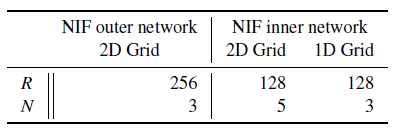
- grid:每个维度分辨率 \(R\),feature
vector(latent vector)长度 \(N\)
- 具体数值如下,是做实验得到的
- Initialization
- 网络参数:Xavier initialization procedure
- feature vector:\(\mathcal{U}(-10^{-4},10^{-4})\) 均匀分布
- Training:下面的超参是实验得到的
- 样本:ray-AABB intersection information
- 样本生成:light importance sampling according to radiant flux
- Adam:\(\beta_1=0.9,\beta_2=0.999,\epsilon=10^{-15}\)
- \(\mathcal{L}^2\) loss
- batch size:\(2^{11}\)(outer),\(2^{12}\)(inner)
- lr:\(0.005\)
- Memory Footprint
- 尽可能使用 half-precision floating points
- 单个物体一共 321KB 左右(输入 10M 个三角形)
- 物体多了 Grid 的大小上去了
- Primary Visibility Computation(第一个交点)
- 论文使用 ray tracing,使用光栅化也 ok
Results
- 1920x1080
- AMD Radeon™ RX 7900 XTX GPU
- measurement:AMD Radeon™ GPU Profiler
- image error:PSNR
- 现在都是静态场景,但是容易扩展到动态场景
Hyperparameters on Grids
- 对比的时候,inner 参数调整,则 outer 直接使用 BVH traversal,outer
参数调整同理
- 只有一个网络
- balance quality and performance
outer network
- Grid 分辨率 \(R\)
越高(训练相同的128 spp,更多就不适合 online-training + rendering了)
- 计算开销越大
- PSNR 在 \(R=256\) 时最大
- 更大之后,物体边缘出样本少,但是高分辨率需要更多的样本,训练不充分
- primary ray casting 测试:直接输出 shading normal and depth
- 训练样本充足的时候,\(R\) 越大,结果质量越好
- latent vector:\(N\) fine-tune from
3-7(\(R\) 固定为 256)
- \(N\) 越大,结果越好,但是推理时间越长
inner netwrk
- \(R\) 影响不像 outer 那么大
- \(N\) fine-tune from 2-5(1D),3-6(2D)
Sampling Method
- 对比实验
- light importance sampling(实现),更好
- uniform sampling
Single NN per Object
- 对比实验
- Single Shared NN(SSN):高效,省空间,快
- Single NN per object(SNPO)
- 总的 PSNR 差不多
- SSN 远处好,SNPO 近处好
- 训练样本正比于屏幕中占据的面积,SNPO 远处物体训练样本少了,效果就差了
Overlapping Objects
- Handling Scenes with Overlapping Objects
- 如果 shadow ray 的起点在重叠的 AABB 内部,会生成两个训练样本用于训练
- 例如 X 和 Y 的 AABB 内部,而且在 X 物体上的光线
- 对于 X,光线直接用于训练
- 对于 Y ,则只需要判断和 Y 的可见性
- 例如 X 和 Y 的 AABB 内部,而且在 X 物体上的光线
- 示例:torus+torus+猴子

不同光源
- Extension for Various Types of Light Sources
- not only IBL
- 点光源、面光源也 OK
- 多光源也 OK
Performance Evaluation
- NIF(TLAS + MLP) vs BVH(TLAS + MLP)
- BVH:sota SAH BVH builder
- AMD 硬件加速
- NN:wave matrix multiply accumulate (WMMA) instruction
- 示例:1.0x-1.53x speedup
- Dragon A(环境光的中国龙)、Dragon B(点光源的中国龙)
- 参数
- shadow ray 数量
- outer network 处理光线数量
- inner network 处理光线数量
- 下面的都是 ms 时间:感觉好慢?可能是 Mesh 比较多吧,AMD 就是比较慢
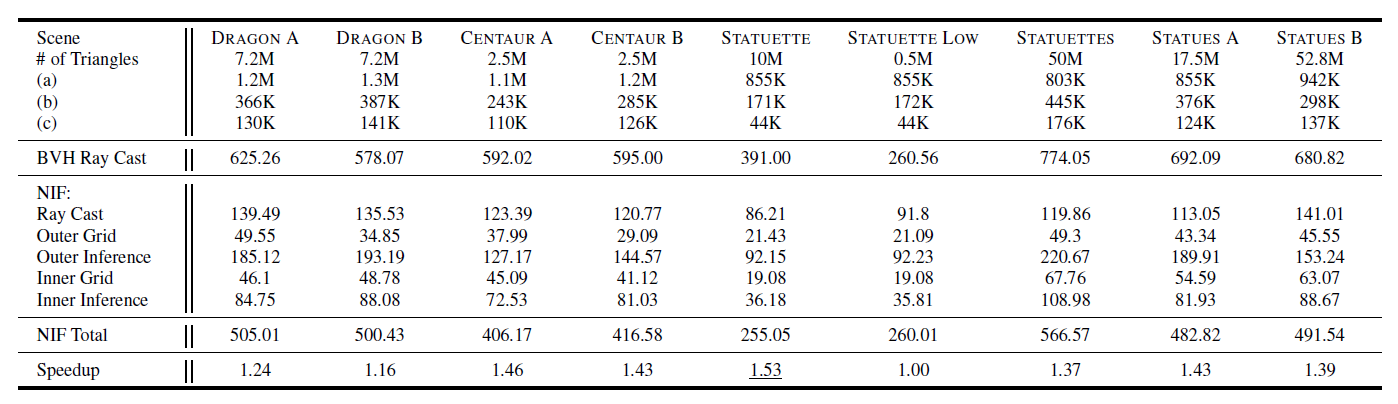
- NIF 而言,大 Mesh 效果好,不遍历 BVH(BLAS),divergence 小
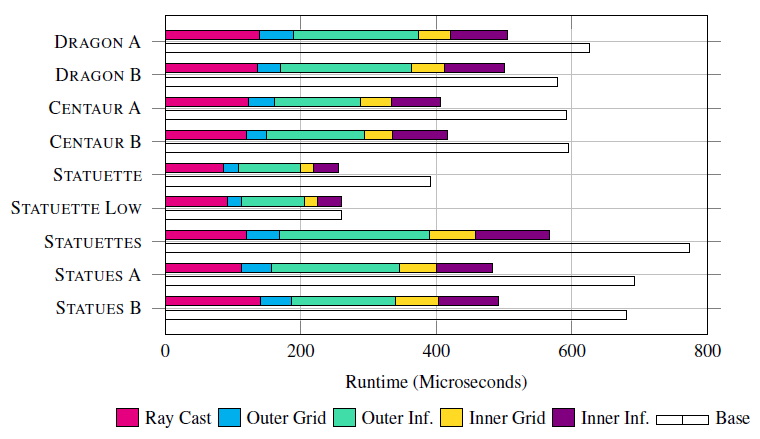
- NIF 执行时间
- 和 Mesh 数量无关,和 NIF 处理的光线数(过网络)近似成正比
- STATUETTE、STATUETTE LOW:一个高模,一个低模,NIF 时间差不多
- NIF 训练时间:1spp
- 0.1s - 1s
Future Work
- 动态场景
- ray query 优化(如果是同样的光线,不需要再经过 NIF 多次查询)
- 不太现实
- 其他的任务
- 编码其他信息:shading normal and depth than visibility
- deeper paths of shadow rays