(论文)[2021-SIG] Real-time Neural Radiance Caching for Path Tracing
NRC
- Real-time Neural Radiance Caching for Path Tracing
- 2021 SIGGRAPH
贡献
- radiance cache
摘要
- 网络的好处
- The data-driven nature of our approach sidesteps many difficulties of caching algorithms, such as locating, interpolating, and updating cache points
- 想法
- cache radiance samples for later reuse
- 使用神经网络代替复杂的启发式函数
- 网络原则
- Dynamic content、Robustness、Predictable performance and resource consumption
- 泛用、鲁棒、可控
- generalization via adaptation(预训练+在线更新)
- 更新快,代价低
- 精简的网络架构(收敛快)
相关工作
Radiance caching
- 开创性工作:[SIG-1988] A ray tracing solution for diffuse
interreflection
- 基本假设:irradiance 在场景中变化慢
- irradiance probe volume
- key:插值、摆放位置
- spherical harmonics 处理方向性
- 其他策略
- compression
- sparse interpolation
- pre-convolved environment maps
- spatial hashing
- 开创性工作:[SIG-1988] A ray tracing solution for diffuse
interreflection
Precomputation-based techniques
- 假设光源、场景固定,可以预计算 irradiance
- lightmaps
- light probes
- precomputed radiance transfer/visibility
Fully dynamic techniques
- 跨像素重用
- Photon Mapping
- many-light rendering
- radiosity maps
- 假设场景、光源具有什么样的性质,然后进行渲染
Path Guiding
- 大多数都是只支持静态场景
Neural techniques
- 能够很好的近似视觉现象,
- 屏幕空间、世界空间
- 单场景、多场景
- 能够很好的近似视觉现象,
论文
- online deep learning
- 不需要假设场景不变(static or known)
- 和场景、光源解耦
- 一个网络,在线学习
- 快(几毫秒),self-training
NRC
- 一个网络估计 radiance
- 输入:spatio-directional coordinates
- 实时 \(\to\) 支持动态场景
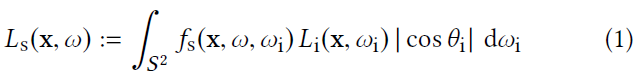
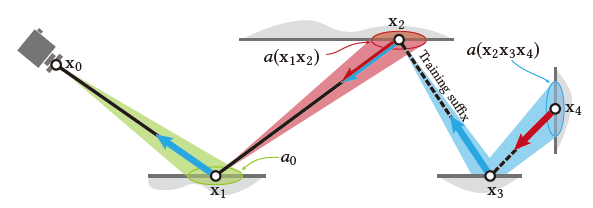
Algorithm Overview
- 渲染一帧包含两步:输出像素颜色、更新网络
输出颜色
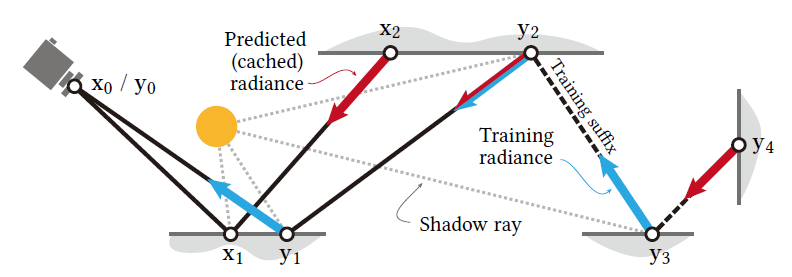
- 对于每一个像素都追一条短路径(\(\mathrm{x}_0\cdots \mathrm{x}_2\))
- 停止条件:网络中获取的值足够接近真实值(启发式)
- 中间节点都加上 NEE(\(\mathrm{x}_1\)),BSDF 和下面的 MIS
- primary hit point:screen-space ReSTIR
- 后继节点:LightBVH
- 终止节点使用网络中估计的 radiance(\(\mathrm{x}_2\)):红色的结果
更新网络
- 扩展少量短路径用于训练(\(3\%\))
- 扩展节点:training suffix(\(\mathrm{y}_1\cdots \mathrm{y}_4\))
- 终止条件:覆盖面积够大(终止节点 \(\mathrm{y}_4\))
- 绝大部分情况下,后缀只会有一个节点
- 后缀节点上得到的 radiance 用于训练网络
Fast Adaptation of the Cache by Self-training
- 为了适应动态场景,我们需要支持快速的 adaption
- 目标值:不是通过 MC 求得,而是通过网络自身更新
- 长训练路径的末端更新,往前传递目标值
- 有点像 Q-learning
- TODO
- self-training 的好处(和 fully path-traced estimates 相比)
- 没有 PT 那么大的噪声(但是引入了 potential bias)
- 随着迭代进行能够捕获 GI
- self-training 的问题
- 如果末端顶点访问网络时,这个位置没有被训练到,则会引入较大误差
- 只会训练到一部分的 light
transport(只有在训练中能够连接到光源的结果会被送入网络训练)
- 访问网络的顶点需要被训练到才能取得好结果
- 问题解决:分配 \(\mu\)
比例的轮次使用真实的 PT 结果
- 论文:\(\mu=\dfrac{1}{16}\)
Temporally Stable Cache Queries
- 适应动态场景的快速 adaption
- 高学习率的梯度下降方法
- 帧内有多个不同学习率的 step(数据不重复使用)
- 问题:时间上不稳定(即使场景、相机不动也会有,估计存在噪声)
- flickering and oscillations(闪烁和抖动)
- exponential moving average (EMA)
- \(W_{t}\) 表示网络权重
- small \(t\)
- \(\alpha\in[0,1]\)(论文 \(\alpha=0.99\))
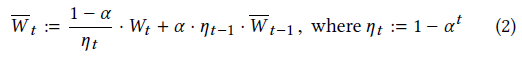
- \(\overline{W}_{t}\) 依赖于 \(W_{t}\),但是不会被用于训练网络【正常训练使用
\(W_t\),但是使用的时候使用 EMA 得到的
\(\overline{W}_t\)】
- EMA 只是用在网络训练的 optimizer 中(tinycudann 中集成了)
- 2018 论文指出:EMA 加权是最优的
- 不同位置的收敛速度差不多,8 帧(70ms)后就能差强人意
Path Termination
- 相机顶点 \(\mathrm{x}_0\)
- 当路径扩展到的面积足够大时,此时可以用模糊的结果替代,此时路径停止
- \(p\):BSDF 采样的 pdf(可以的话,就是 BSDF)
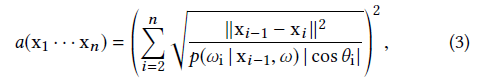
- 解释
- \(\dfrac{\text{d}^2} {\vert{\cos}\vert}\;\mathrm{d}\omega=\;\mathrm{d}A\)
- BSDF 值越大,立体角越小(反相关)
- 单位球面上均匀采样时,\(p\cdot\mathrm{d}\omega=1\)
- camera 到 primary vertex 的扩展面积
- 假定是 spherical image plane,\(p=\dfrac{1}{4\pi}\)
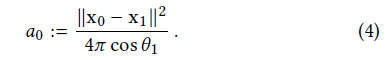
- 停止条件如下,其中 \(c\)
是超参数(\(c=0.01\))
- 启发式
\[ a(\mathrm{x}_1\cdots\mathrm{x}_n)>c\cdot a_0 \]
- 如果被选中作为 training suffix,满足如下条件时停止
- 启发式
\[ a(\mathrm{x}_n\cdots\mathrm{x}_m)>c\cdot a_0 \]
- 示意图,停止位置:\(n=2/4\)
集成
- 60fps(~16.6ms)
- 每一帧:
- tracing of paths
- shading at every vertex
- querying and updating the cache
- 长训练路径指定:屏幕空间做 tiling
- a single random offset,均匀的选取长路径(基本没有开销)
- 当 tracing 结束的时候
- 短路径回传,形成结果图
- 长训练路径,需要记录 rendering + training
radiance(一个用于训练,一个用于渲染结果图)
- TODO:是否可以这一帧都使用短路径的结果,长训练路径中只用于训练?
- 训练
- 所有样本使用 LCG 进行打乱,形成 \(s\) 个 batch,每个 batch 中有 \(l\) 个样本
- 打乱取消相关性(image region)
- 每一个 batch 进行一次优化
- \(s\times l=4\times 16384=65536\)
- 有限且差不多的样本数(stable work
load),与分辨率无关
- 帧间根据上一帧样本数调整 tile size,使得总的样本数差不多
- 所有样本使用 LCG 进行打乱,形成 \(s\) 个 batch,每个 batch 中有 \(l\) 个样本
Input Encoding
- 只输入 \((\mathrm{x},\omega)\) 给 NN 效果不好
- 辅助信息
- surface normal \(\mathrm{n}\)
- surface roughness \(r\)
- diffuse reflectance \(\alpha\)
- specular reflectance \(\beta\)
- 当 input 和 radiance 的关系为线性的时候,NN 容易学习到他们之间的关系
- \(\alpha,\beta\) 已经满足
- 其他变量需要编码:kernel trick(变换到高维空间中)
- 性能开销:输入变大,输入层 NN 变大

- \(\omega,\mathrm{n},r\):one-blob
encoding(NIS2019)
- 条件:scale of the nonlinearities is about the same order of magnitude as the size of the blobs
- 相对平滑,小扰动不会对 radiance 产生很大的变化
- \(k=4\)
- \(\mathrm{x}\):frequency
encoding(Attention2017,Nerf2020)
- 微小扰动会发生巨大变化(阴影、几何边界)
- \(12 \sin\)
- 不使用 \(\cos\) 损失不大
- frequency \(2^d,d\in[0,11]\)
- 最终输入维度:\(14\to62\to64\)
- pad 2 位,底层矩阵乘法加速
- pad 值为 1 ,让网络隐式学习 bias(架构中没有 bias vector)
- pad 2 位,底层矩阵乘法加速
Fully Fused NN
- 自己实现,比 TensorFlow (2015-v2.5.0) 快
- 半精度 + tensor core
- batch size
- 训练:\(2^{14}=16384\)
- 推理:\(1920\times1080\approx2^{21}\)
- 加速:\(5\times\sim10\times\)
- 更好的利用 GPU 内存的 hierarchy
- 对于小网络而言,memory traffic 是瓶颈
- The key to improving performance is thus
- to minimize traffic to slow “global” memory (VRAM and high-level caches)
- and to fully utilize fast on-chip memory (low-level caches, “shared” memory, and registers).
- 整个网络在一个 GPU kernel 中实现,global memory 只在网络输入输出中发生
- 从头实现的好处:可以为我们的需求定制网络
整体设计
inference
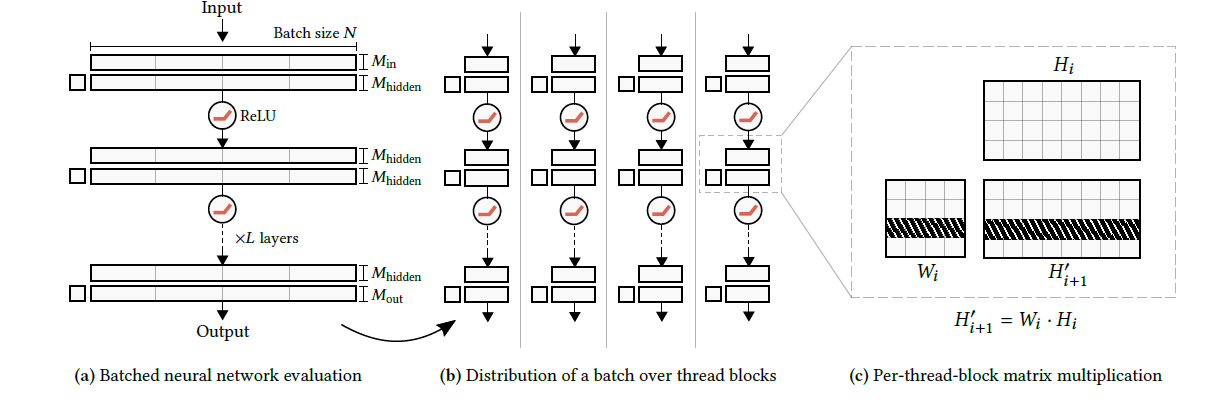
- \(64\times128\) 能放到 shaded
memory 中
- thread block size:128(RTX3090 最合适的数量)
- \(M_{\text{in}}=M_{\text{hidden}}=64\)
- 具体乘法的时候划分为半精度的 \(16\times16\) 的矩阵乘法(适应 TensorCore)
- thread block 内部计算
- 每一个 warp计算 \(16\times128\) block-row 的 \(H'\)
- 对于 warp 内的每一个线程
- 先一起加载 \(W\) 的 \(16\times64\)
- 然后依次加载 \(H\) 的 \(64\) 列,\(W\) 乘上 \(H\) 的 \(64\times16\)
- warp 共享加载 \(W\)
- 不同 warp 加载的行不一样,因此每一个 thread block 中只会从 global memory 中加载一次 NN
- 接下来需要考虑的就是减少 block 的个数,在 RTX3090 上,最合适的 block size 是上面说的 \(128\)
training
- 没加速
- general matrix multiplication (GEMM) routines of the CUTLASS template library (in split-k mode)
实现
Architecture
7 层网络
5 层 hidder layers:64 neurons each
ReLU
输出:\(64\to3\)(RGB 值)
所有层都不带 bias vector(加了没有提升,而且不加实现更简单)
网络很浅,不会出现梯度消失的问题
Reflectance factorization
- diffuse albedo and specular reflectance
- \(\alpha(\mathrm{x},\omega)+\beta(\mathrm{x},\omega)\)
- 让带有纹理的结果表现更好
- diffuse albedo and specular reflectance

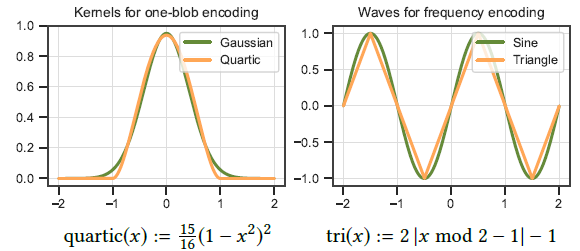
- High-performance primitives for encoding
- 在肉眼观察差不多的情况下,每帧减少 0.25ms
- 原始的 one-blob and frequency encoding 依赖于难计算的函数
- Gaussian kernels, trigonometric function
- 使用如下函数代替
- quartic kernel, triangle wave
- Relative loss
- \(L_{\text{s}}\) 存在噪声,估计残差(admits unbiased gradient estimates?)(2018Noise2Noise),分母归一化
- \(\epsilon=0.01\)
- \(\text{sg}(\cdot)\):梯度反传时作为常数(stop gradient)
- 每个通道使用如下变量归一化:squared luminance across the spectrum
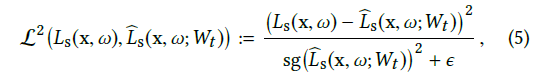
- Optimizer:Adam
- first-order optimizers:Adam 收敛最快(需要帧数少)(SGD、Novograd 相比)
- second order optimizer:Shampoo(需要帧数少,但是每帧开销 + 0.3ms)
结果分析
- perceptually based metric
- 对比算法
- PT(light BVH+NEE)
- PT+ReSTIR
- PT+ReSTIR+NRC
- Self-training
- 和只用 PT 的结果作为真实值进行对比
- PT:如果路径被我们启发式的终止,则返回 0
- self-training 只多了一次查询网络的开销,但是捕获了 multi-bounce 的光照
- 和只用 PT 的结果作为真实值进行对比
- cache 质量很高
- heuristic hit 查询(NRC 本身)质量很好
- first no-specular 就查询,质量还行
- 问题
- 缺失 sharp detail
- axis-aligned stripes(频率编码问题)(其他编码更差)
- 根据我们启发式的规则,停止的时候 path 的覆盖范围大,bias 全被平均掉了,同时 AO 不需要特殊处理(本身就是一种平均)
- DDGI
- DDGI is a modern extension of irradiance probes, relying on modulation by the surface normal and albedo to approximate the scattered radiance.
- DDGI 在 Lambert 材质表现最好
- DDGI 在第一次遇到 diffuse(not specular/glossy)表面的时候就进行 probe 的查询(激进)
- DDGI 快、噪声少(1spp噪声小),但是 bias 大
- NRC 训练比 DDGI 快,每帧样本数少,trace rays 少
- NRC:\(2^{16}=65536\)
- DDGI:\(16^3\) grid,\(16^3\cdot256=1048576=16\times\)
讨论
- 预计算:好的初始化
- 效果有限,现在收敛很快
- cache 的bias
- 频率编码、EMA 不能解决低频的闪烁问题
- 更多输入:shadows、caustics
- 对离线渲染产生帮助
- 体渲染
- Path guiding
- Improved path termination
- covariance tracing
- bundle coherence
- our cache currently provides little benefit when transport is dominated by dielectric materials such as glass


- NRC 可以认为是一种 denoise
简单实现
- 图片对比链接
- 参数
- max-bounce=6(中间结点数)
- RRS=1.0
- 1spp
- 开 NEE
- NRC 实现
- training suffix 不终止
- 屏幕空间 ReSTIR 未实现
- 没有实现纹理(albedo)的分离
{kind=link}