0%
Unit3
- Deep Q-learning With Atari Games
Introduction
Q-leaning to Deep Q-learning
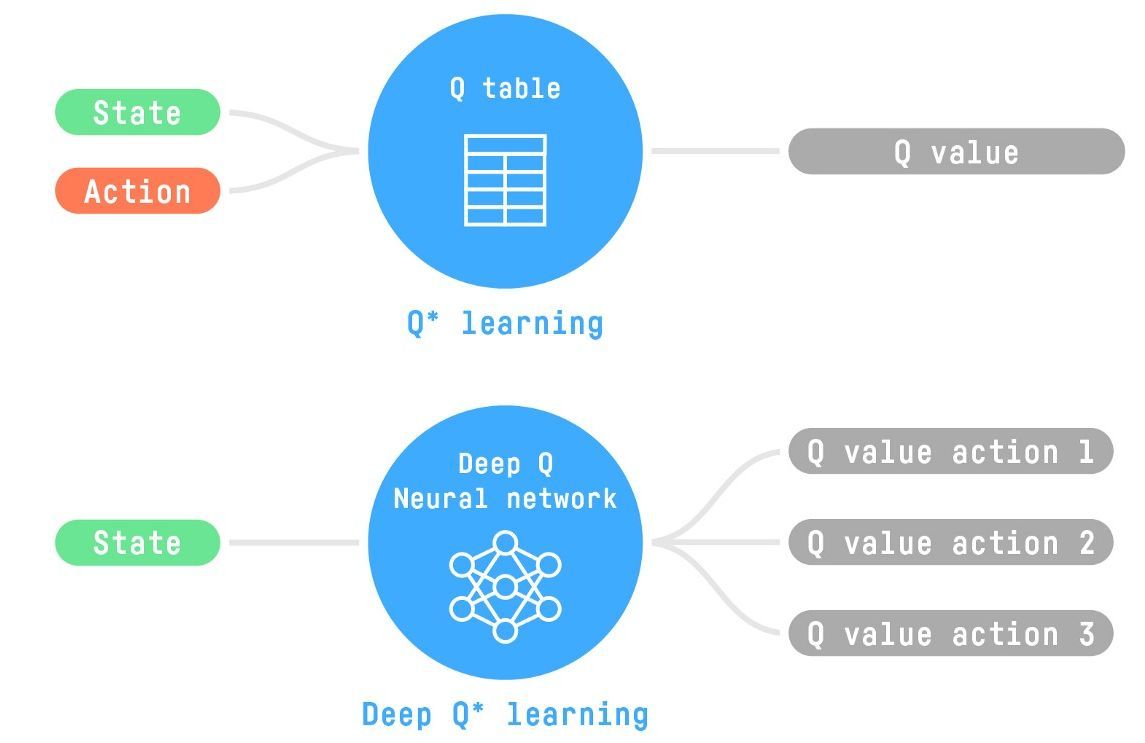
- Q-learning 是一种打表的算法
- Atari 环境
- 输入为图片,有 \(256^{210\times160\times3}\) 种可能性
- 分辨率 \(210\times160\)
- RGB 三通道
- 使用参数化的 \(Q_{\theta}(s,a)\)
进行代替
DQN
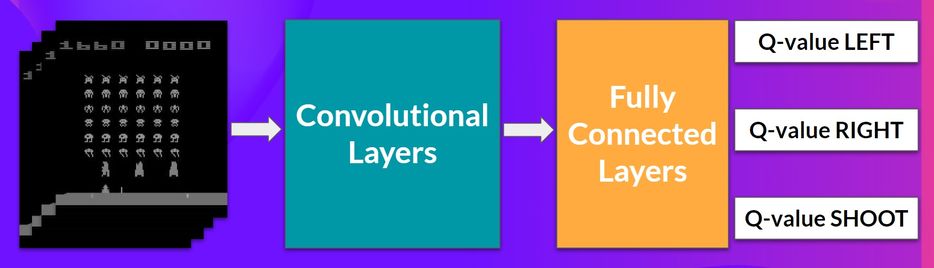
- The Deep Q-Network
- 架构如下
- 输入: 4 帧连续的图片(stack)
- 输出:vector of Q-values for each possible
action at that state
- 预处理输入
- 像素压至:84x84
- 灰度化:RGB -> gray
- 裁剪:有些游戏可以裁剪掉不重要的区域
- stack 的原因:捕获运动信息,抵抗 temporal limitation

Deep Q-Learning
- 和之前相比,将
TD Error 作为训练的 loss
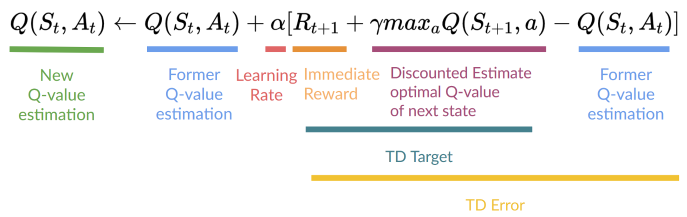
- 算法分为两个步骤:sampling + training
- sampling:使用 \(\epsilon\text{-greedy}\)
策略采样行动,保存状态对
- training:在 sampling 阶段得到的状态对中,采样 minibatch 进行训练
- \(y_j\):Q-Target,我们认为的真值(对真值的估计)

稳定性
- Deep QL 带来了不稳定性
- bootstrapping:使用的 return 并不是真实值,而是估计
- 网络本身的不稳定
- 策略:Experience Replay、Fixed
Q-Target、Double Deep Q-Learning
- Experience Replay
- replay memory \(D\)
记录下来,后面可以多次学习
- 降低相关性(只学习最新的,导致振荡或者背离)、避免灾难性遗忘
- Fixed Q-Target
- \(C\)
步之后,更新用于计算真值的网络 \(\hat{Q}\)(网络 \(Q\) 一直被更新)
- \(\hat{Q}\):不是一直更新,\(C\) 步内使用相同的 Q-Target
- 如果真值和 Q-Target 都在变化,比较难学习,导致训练振荡
- Double Deep Q-Learning
- Double DQNs,Double Deep Q-Learning neural networks
- 使用两个神经网络,一个用于选择最优的 action(sampling
phase),一个用于计算 Q-Target(training phase),互相更新

- 其他改进
- Prioritized Experience Replay
- Dueling Deep Q-Learning
HW3
阅读材料
BUnit2
automatic hyperparameter
tuning
- "n VS B/n" trade-off
- n: number of configurations
- B / n: budget per configuration
- 随着时间增加,减少测试的 config 种类
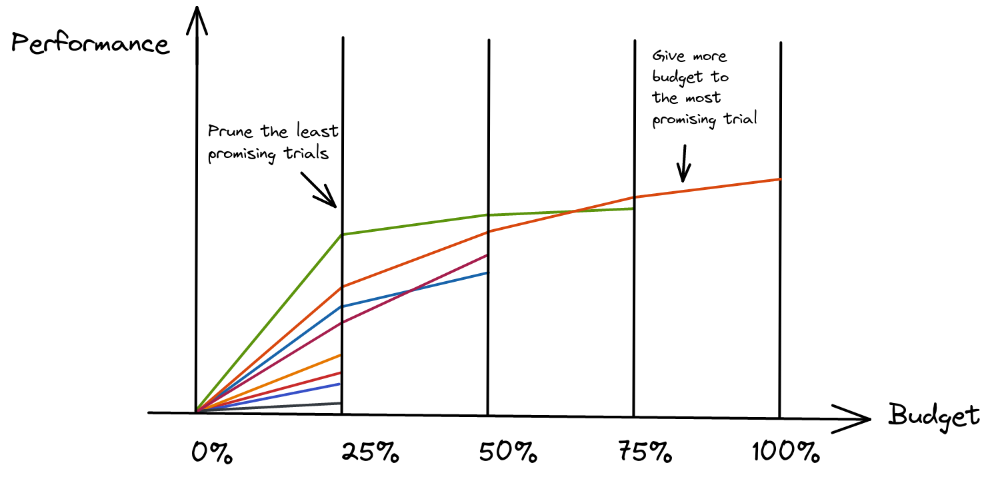
- 寻找最优 config
- sampler(search algo):选取 config
- pruner(scheduler):继续执行这个
config,或者停止执行
sampler
- grid search:可能找不到
- random search:更好
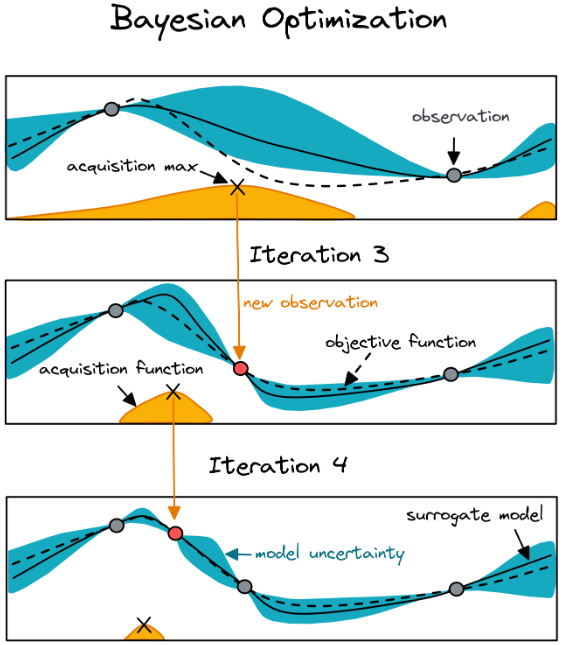
- 贝叶斯优化
- 虚线:真实值
- 每次试图优化最坏的地方(图上:acquisition max 处)
- Black Box Optimization
- Evolution Strategies(ES,CMA-ES)
- Particle Swarm Optimization(PSO)
scheduler
- Median Pruner:最好的结果差于中位数,则舍弃
- Prune if the trial’s best intermediate result is worse than median
of intermediate results of previous trials at the same step
- Successive Halving
Optuna
- Optuna:库,自动选取最优的超参
- 教程
- 步骤
- Define the search space
- Define the objective function
- Choose sampler and pruner
- Get a coffee/Take a nap
- 科研陷阱
- HP(Hyper Parameters) optimization not needed (train longer
first)
- Noisy evaluation: multiple eval
- Search space too small/wide
- Slow optimization: smaller budget
- Training not stable: manual tweaks