Deep Reinforcement Learning Course(2)
Unit2
- Introduction to Q-Learning
- value-based methods
value-based methods
- 状态 \(s\) \(\to\) 期望收益(收益 return 表示单步奖励 reward 之和)
\[ v_\pi(s)=\mathbb{E}_\pi\left[R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\ldots\mid S_t=s\right] \]
- 不管是 policy-based 还是 value-based,都是想要找到最优的 policy
- value 和 policy 之间的关系
\[ \pi^{\ast}(s)=\arg\max_{a}Q^{\ast}(s,a) \]
- 从 value-based 构建 policy:Epsilon-Greedy Policy
- 处理 exploration/exploitation trade-off
- 两类 value-based function
- state-value function
- action-value function
- \({\color{red}G_t}\) 表示 return
| state-value function | 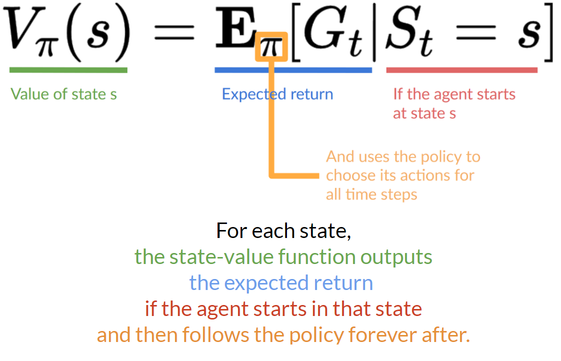 |
|---|---|
| action-value function |  |
- 区别:后者多了 \(a\)
- 共同点:返回值都是一个期望值
- 如何计算?很难!计算期望需要求所有可能的情况
The Bellman Equation
- simplify our value estimation
- 建立相邻状态之间的关系:\(R_{t+1}\) 表示从状态 \(S_t\) 到状态 \(S_{t+1}\) 的奖励

MC vs TDL
- Monte Carlo vs Temporal Difference Learning
- 两种训练 value/policy function 的方式
- 区别
- MC:使用整个 episode 进行学习
- TD:只使用 \((S_t,A_t,R_{t+1},S_{t+1})\) 进行学习
- MC:模拟整个 episode,计算 return 用于更新
- 这里应该是随机均匀采样

- TD:只使用单步数据进行更新
- 不知道收益,使用单步奖励进行更新
- 收益估计:\(R_{t+1}+\gamma
V(S_{t+1})\)
- 这称为:one-step TD、TD(0)
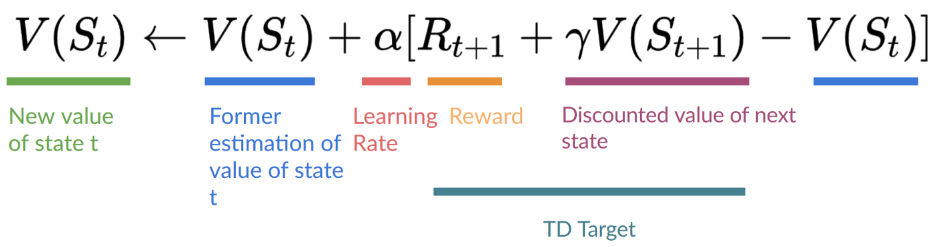
- 总结
\[ \begin{aligned} \text{Monte Carlo: }&V(S_t)\leftarrow V(S_t)+\alpha[G_t-V(S_t)]\\ \text{TD Learning: }&V(S_t)\leftarrow V(S_t)+\alpha[R_{t+1}+\gamma V(S_{t+1})-V(S_t)] \end{aligned} \]
Introducing Q-Learning
- Q-Learning is an off-policy
value-based method that uses a TD
approach to train its action-value function
- Off-policy:using a different policy for acting (inference) and updating (training)
- On-policy:using the same policy for acting and updating
- 训练一个 Q-function(Q:Quality)
- 输入:state、action
- 输出:Q value
- Q function 内部编码为一个 Q-table,每一行记录一组数据 \(\text{state}(,\text{action})\to\text{value}\)
- 概念区分
- value:expected cumulative reward
- reward
- Q-table 示例
- 一般初始化为 0

Q-Learning algorithm

- step 1:初始化
- step 2:\(\epsilon\text{-greedy}\)
策略
- \(\epsilon\) 的概率:exploration,随机选择一个行动
- \(1-\epsilon\) 的概率:exploitation,贪心选择最好的行动
- \(\epsilon\):一开始比较大(多 exploration),然后随着训练进行变小
- step 3:执行行动,更新状态
- step 4:更新 Q 值(查表更新)
- 选择状态 \(t+1\) 的最大行动的 Q 值用于更新状态 \(t\)
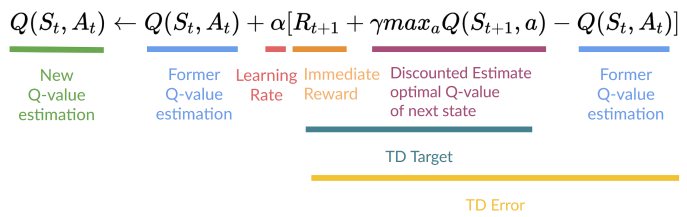
- Q-learning 是 off-policy
- step 2 和 step 4 使用的 policy 不同
- acting:2 是 \(\epsilon\text{-greedy}\)
- updating:4 是直接 \(\text{greedy}\) 选择最大的
- step 2 和 step 4 使用的 policy 不同
例子
- 以老鼠吃奶酪为例子
HW2
- 训练都挺快的
Frozen Lake
- Qtable:16x4
- 16个位置,4个方向的行动

Taxi
- QTable:500x6
- state:25x5x4
- taxi 的位置 25
- 乘客状态:4个颜色位置、taxi 上
- 目标位置:4个颜色位置
- action:4个方向的移动+乘客上下车
- state:25x5x4
其他材料
MC vs TD
Q-Learning