Deep Reinforcement Learning Course(1)
课程
本地环境:py310
- box2d 问题:swig(直接下载 Windows 版本可执行文件),然后之下下面命令
1
2conda install swig
pip install box2d- 默认是 cpu 的 torch 版本,需要自己安装 cuda 版本
- 生成视频出了问题:
pip install decorator==4.4.2 - shimmy 版本问题:
pip install shimmy=1
Unit0
- Unit 0. Welcome To The Course
- 课程与网站介绍
Unit1
- Introduction to Deep Reinforcement Learning
- 目的
- 训练一个模型,a lunar lander to land correctly on the Moon
- 训练一个小狗捡木棍的模型
什么是强化学习
- What is Reinforcement Learning?
RL Framework
- The Reinforcement Learning Framework
- The RL Process
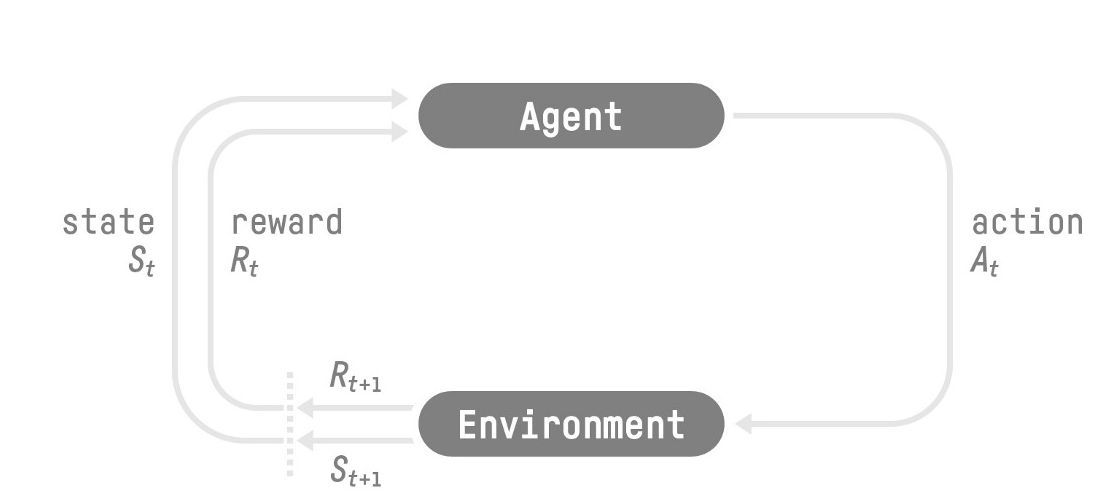
概念
- state \(S_0\):状态
- action \(A_0\):行动
- reward \(R_1\):奖励
- next state \(S_1\)
目标:最大化 cumulative reward(expected return)
Markov Decision Process (MDP)
决策只与当前状态有关(与之前状态无关)
Observations/States Space
- State \(s\):a
complete description of the state of the world
- 国际象棋中的整个棋局
- Observation \(o\):a
partial description of the state
- 游戏里面的观察视野
- State \(s\):a
complete description of the state of the world
Action Space
- all possible actions in an environment
- 可以是离散的、也可以是连续的(discrete or continuous space)
Rewards and the discounting
- reward:the only feedback for the agent
- return(cumulative
reward):收益:\(R(\tau)=r_{t+1}+r_{t+2}+\cdots=\sum_{k=0}^{\infty}r_{t+k+1}\)
- \(\tau\):trajectory(轨迹),一系列 state+action 的集合
- discount rate \(\gamma\in[0,1]\)
- \(R(\tau)=\sum_{k=0}^{\infty}\gamma^{k}r_{t+k+1}\)
- \(\gamma\):越大越在意长期收益(long-term reward),越小越在意短期收益(short term reward)
Type of tasks
- 两类问题:episodic、continuing
- episodic task
- 存在初始状态和结束状态:有一个情节(episode)
- 例如:游戏,进入游戏的初始状态,通关条件(即结束状态)
- continuing tasks
- 没有终止状态,一直持续下去
- 例如:炒股
Exploration/Exploitation trade-off
- exploration:尝试随机策略去获取更多环境信息
- exploitation:利用已有信息最大化收益
- trade off:只使用当前信息可能不是最优的,尝试更多可能带来更高的收益(也有可能没有收益)
solving RL problems
- 两种解决 RL 问题的思路:Policy-Based Methods、Value-Based Methods
- policy-based:\(\text{state}\to\pi(\text{state})\to\text{action}\)
- 直接学习最优的 policy
- RL 就是为了求解最优的 \(\pi^{\ast}\)
- 对 policy 分类
- 确定性的(deterministic):\(a=\pi(s)\)
- 每一个状态确定唯一的行动
- 随机性的(stochastic):\(\pi(a\mid s)=P\left[A\mid s\right]\)
- 确定性的(deterministic):\(a=\pi(s)\)
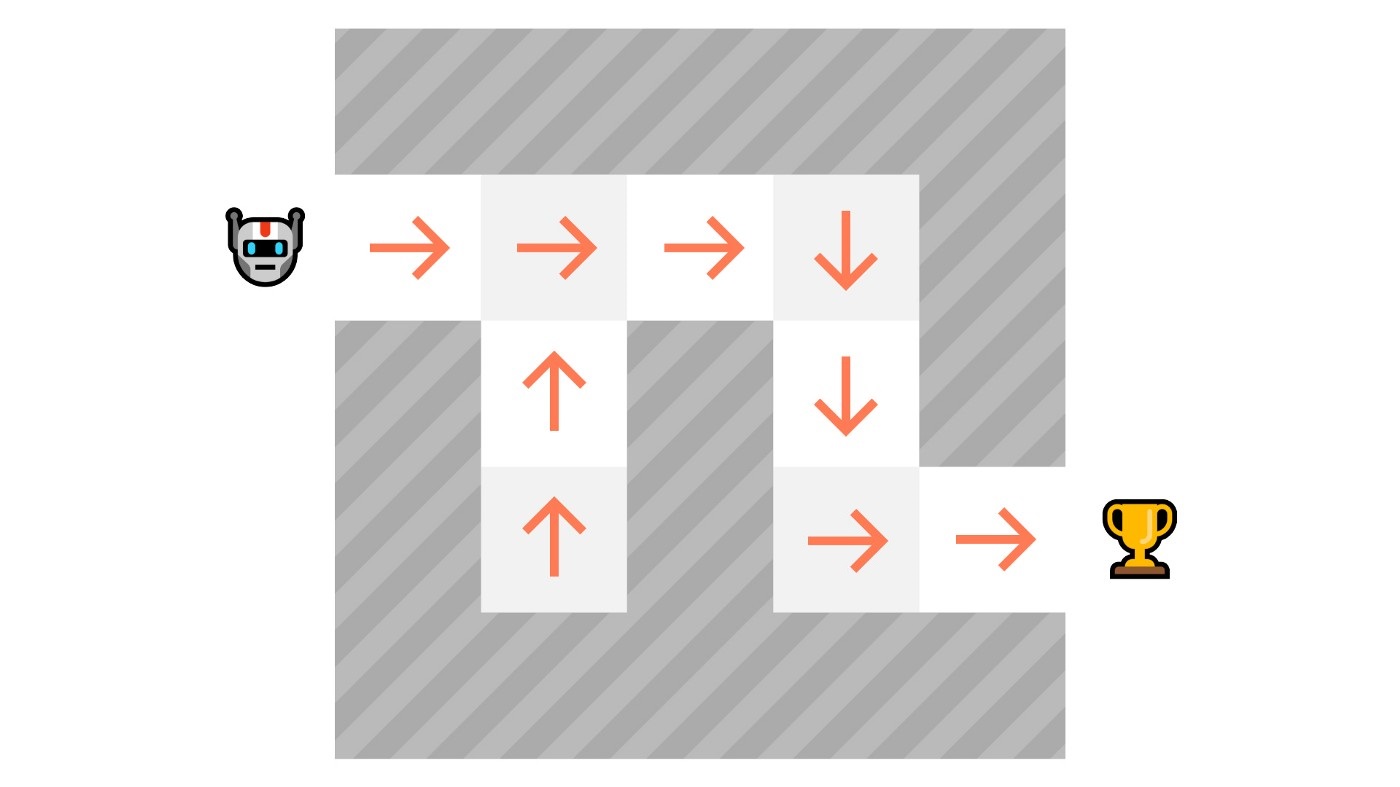
- value-based
- 学习什么状态是最优的,然后找到走向最优状态的行动
- 价值定义:从这一点出发,能够获得的收益越大,则越有价值
- \(v_\pi(s)=\mathbb{E}_\pi\left[R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\ldots\mid S_t=s\right]\)
| policy-based | value-based |
|---|---|
 |
 |
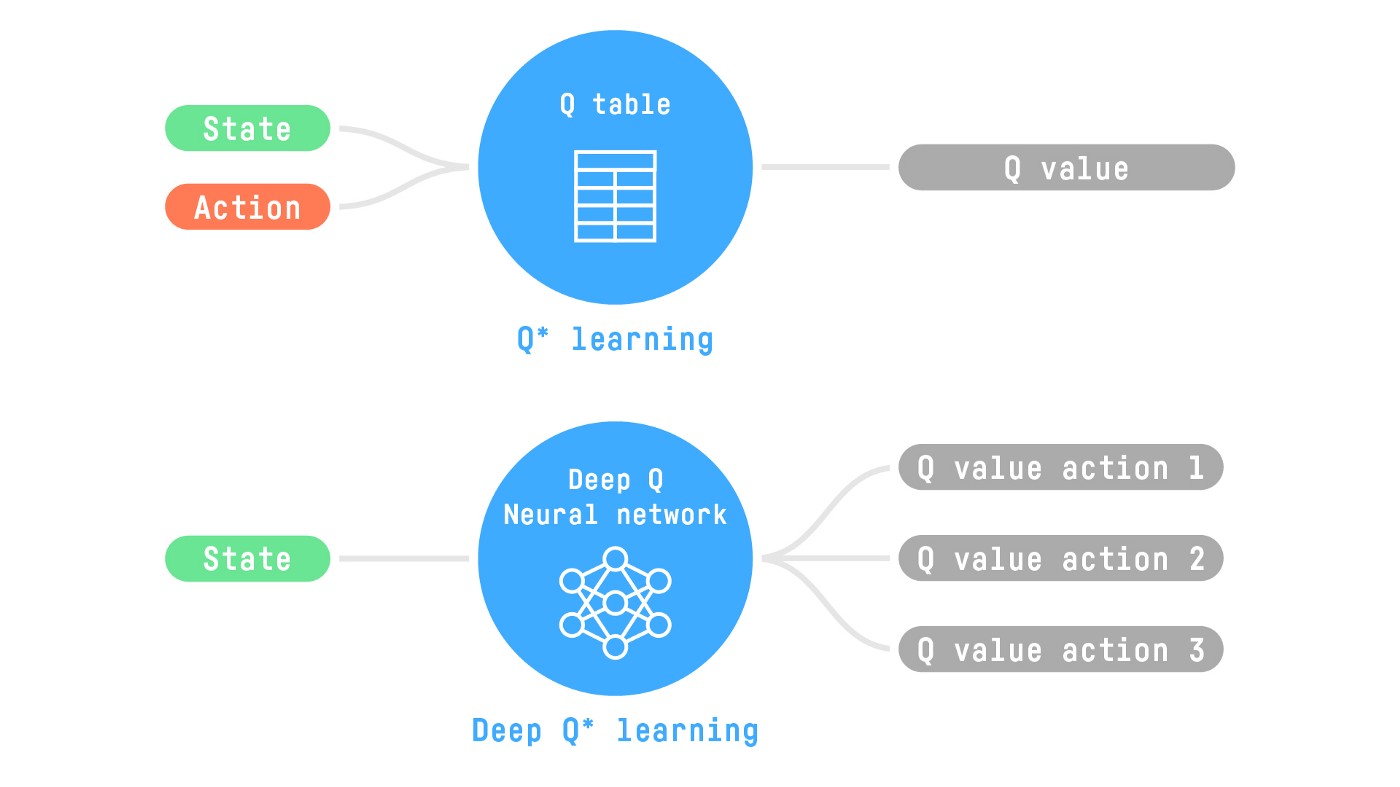
Deep RL
- 引入神经网络:deep neural network
- 一个示例,具体之后讲解
HW1
- TLDR:跑别人的环境,跑别人的算法,20 分钟
- 准备
- 环境:
gymnasium[box2d] - DeepRL 库:
stable-baselines3[extra]
- 环境:
- 做一个月球降落器:Lunar Lander
- 行动:不动,左喷,中间喷,右喷