0%
Programming Interface
CUDA Runtime
Graphics Interoperability
- opengl、dx
cudaGraphicsxxx 函数- 需要 register、unregister 的操作
- 操作耗时
- 一般:buffer 创建的时候 register、销毁的时候 unregister
struct cudaGraphicsResource
- register 之后可以多次 map
- 之后可以让 kernel 进行操作
OpenGL
- 可以映射的资源
- OpenGL buffer, texture, and renderbuffer objects
- 有示例代码
Direct3D
- Direct3D 9Ex, Direct3D 10, and Direct3D 11
SLI mode
- Scalable Link Interface(多 GPU)
- 多显卡当作一张
- Nvidia
SLI:5 种模式
- Split Frame Rendering (SFR):每一帧内部的不同任务交给不同 GPU
- Alternate Frame Rendering (AFR):不同帧交给不同 GPU
- Boost Performance Hybrid SLI Rendering:SFR 类似,但是 GPU
之间不平均(有多有少,有主次)
- SLIAA
- Compatibility mode:只使用一个 GPU(默认行为)
External Resource
Interoperability
- 更底层:vulkan、DX12、DX11
- 让 cuda 可以导入被一些 API 隐式导出的 objects
- These objects are typically exported by other APIs using
handles native to the Operating System
- 例如:文件描述符
- 包括:memory objects and synchronization
objects
Vulkan
- vulkan 的 device 和 cuda 的 device 必须一致
Direct3D 12
Direct3D 11
NVSCI
- NVIDIA Software Communication Interface
- 不同库之间的通信问题
- NvSciBuf and NvSciSync are
interfaces developed for serving the following purposes:
- NvSciBuf: Allows applications to allocate and exchange buffers in
memory
- NvSciSync: Allows applications to manage synchronization objects at
operation boundaries
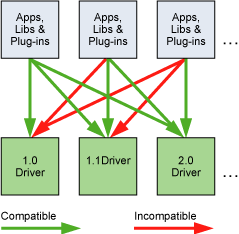
Versioning and Compatibility
- 两个关键的版本
- Compute Capability:硬件信息
- CUDA:驱动信息,(头文件
CUDART_VERSION)
- cuda 版本是向后兼容的(backward
compatible),但不是向前兼容的(forward compatible)
Compute Modes
- device 的 3 种模式:nvidia-smi 设置
- Default compute mode
- Exclusve-process compute mode:只能有 1 个进程创建
- Prohibited compute mode:不允许创建
Mode Switches
- 显示模式的切换(分辨率、位深、……),可能会导致 cuda
运行时函数调用失败,返回无效上下文
Tesla Compute Cluster
Mode for Window
Hardware Implementation
- 一个 SM 上的线程
- SIMT:Single-Instruction, Multiple-Thread
- GPU:没有分支预测、推测执行
- NVIDIA GPU:little-endian
SIMT Architecture
- 32 parallel threads called warps
- warp 里面的线程
- 相同的 program address
- 独立的 instruction address counter、register state
- half-warp、 quarter-warp
- multiprocessor 将分到的 block(s) 里的 thread 划分为 warp,通过
warp scheduler 调度执行
- 一个 warp 里的 thread
- 最高效:所有的线程的 execution path 都相同
- branch divergence
- 如果存在分支,则都会执行一遍(不满足的分支在执行的时候停止)
- 硬件实现
- Volta 之前,warp 只有一个 PC,active mask 标识线程是否活动
- Volta(含)之后
Hardware Multithreading