cuda 学习(2)
Programming Interface
CUDA Runtime
Asynchronous Concurrent Execution
- 可并行的任务
- host 计算
- device 计算
- host -> device 数据传输
- device -> host 数据传输
- device 内部的数据传输
- device 之间的数据传输
Concurrent Execution between Host and Device
- 异步操作
- Kernel 启动
CUDA_LAUNCH_BLOCKING修改为 1,则同步(debug only)
- device 内部数据拷贝
- host -> device 数据拷贝(<=64KB)
Async后缀的数据拷贝函数- Memory set function calls
- Kernel 启动
- 使用 Nsight、Visual Profiler 时,kernel 启动是同步的
- host 不是 page-locked 的时候,
Async变成同步
Concurrent Kernel Execution
- CC>=2.0,某些 device 支持多 kernel
concurrentKernelsdevice property
Overlap of Data Transfer and Kernel Execution
asyncEngineCountdevice property(>0 则支持)
Concurrent Data Transfers
asyncEngineCountdevice property(=2 则支持)- host memory 必须是 page-locked 的
Streams
- commands 序列(可以是多个 host threads)
- stream 内部顺序执行、stream 之间乱序
1 | // 创建 |
- Default Stream
- 不指定 stream(或者参数设置为 0)
1 | 编译参数 |
- nvcc 编译的时候默认 include 了 cuda
的头文件,因此宏可以不一定有效(需要添加在编译选项里面)
- 下面 1、2 有效,3 可能失效
1 | #define CUDA_API_PER_THREAD_DEFAULT_STREAM 1 |
- 显式同步`
1 | cudaDeviceSynchronize(); // device 上所有 stream 结束 |
- 隐式同步
- a page-locked host memory allocation,
- a device memory allocation,
- a device memory set,
- a memory copy between two addresses to the same device memory,
- any CUDA command to the NULL stream,
- a switch between the L1/shared memory configurations described in Compute Capability 7.x.
- 编程指导(提高并发)
- 没有依赖的操作在有依赖的操作之前发出
- 同步操作越晚越好(延迟同步)
- Overlapping Behavior
- overlap between two streams(首先需要硬件支持)
- 需要考虑硬件支持的类别,合理规划代码执行顺序
- Host Functions (Callbacks)
cudaLaunchHostFunc():insert a CPU function call at any point into a stream- 在 host function 执行完之前,之后的 device 代码不会执行
- 函数内部不允许作 cuda 调用,否则会陷入死锁(自己等自己)
- Stream Priorities:
cudaStreamCreateWithPriority()- 哪些优先级:
cudaDeviceGetStreamPriorityRange()
- 哪些优先级:
- Programmatic Dependent Launch
- CC>=9.0
- kernel2 一部分不依赖于 kernel1,一部分依赖于 kernel1,此时有一部分并行

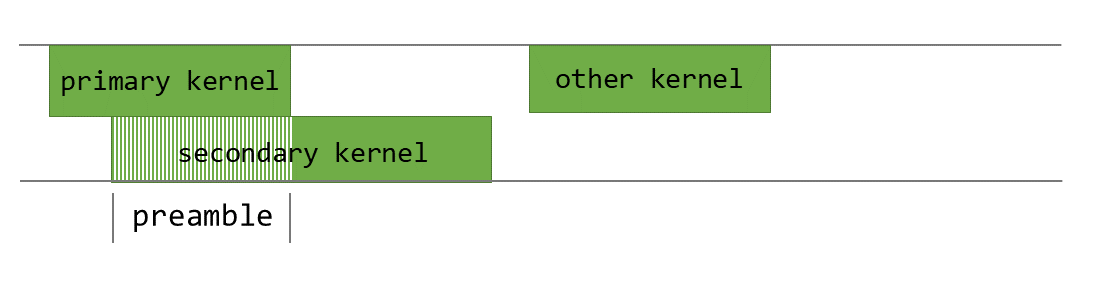
CUDA Graphs
- 依赖图
- defined once,lanched repeatedly
- 和 stream 相比
- CPU 启动开销变小了,预先 setup 了
- 整个工作流提供给 cuda,能够让 cuda 更好的优化
- 工作流:definition, instantiation, execution
- 只有 execution 有多次执行
- Graph Node Types
- kernel
- CPU function call
- memory copy、memset
- empty node
- waiting on an event、recording an event
- signalling an external semaphore、waiting on an external semaphore
- child graph
捕获模式
- Stream capture:可以从 stream 中建立 Graph
1 | cudaGraph_t graph; |
- 此时中间的任务不会被执行
- 除了 NULL stream 之外,都可用
- 可以查询流状态:
cudaStreamIsCapturing() - 通过
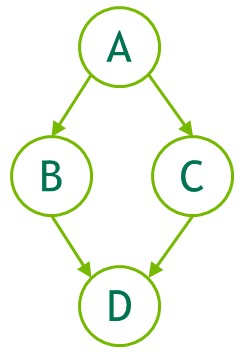
cudaEventRecord()、cudaStreamWaitEvent()实现流之间的依赖关系(如下图)- 当一个流还未完成,如果此时其依赖于一个捕获模式中的事件,则这个时候当前流也进入捕获模式,两个流此时被同一个 graph 捕获
- 当 stream 退出捕获模式时,Stream 中如果有下一个未捕获项,则它将仍依赖最近的先前未捕获项
- 当处于捕获模式的时候,如下状态的查询失效(需要查询每一个操作的返回状态)
- 对捕获流相关异步操作的查询是无效的(并未真正执行)
legacy stream(NULL stream) 会和其他的所有 stream 同步(除了通过cudaStreamWaitEvent()创建的之外),因此对其的查询也失效- Synchronous APIs 查询同样也失效(会被推入
legacy stream),例如cudaMemcpy()
- 当处于捕获模式的时候,如下操作是 invalid 的(看返回值)
- 没太看懂:It is invalid to merge two separate capture graphs by waiting on a captured event from a stream which is being captured and is associated with a different capture graph than the event. It is invalid to wait on a non-captured event from a stream which is being captured without specifying the cudaEventWaitExternal flag.
- 少部分异步操作暂时不支持
- 如下 graph 可以直接创建,也可以通过捕获模式创建(event)
- 时常检查返回值,graph 中存在 error,则整个 graph 也会 error
CUDA User Objects
cudaUserObjectCreate()- 可以维护在 graph 内部的引用计数,当引用计数为 0 的时候,调用回调函数(析构对象)
- 但是无法在 cuda 端等待回调函数完成,可以通过事件手动实现
其他细节
- 暂时用不到,就不看了
- 更新初始化好的 graph
- 启动 graph
- 事件
- 同步调用:
cudaSetDeviceFlags()
Multi-Device System
- 设备信息
1 | cudaGetDeviceCount(); |
- 设置设备:
cudaSetDevice()- 所有操作都基于当前 device:内存分配、kernel 执行、stream 创建
- stream 和 kernel 不在一个 device 上会报错
- 默认 0
- 所有操作都基于当前 device:内存分配、kernel 执行、stream 创建
1 | // 如果注释中的两部分位于不同的 device,如下操作失效 |
- 不同的 device 有不同的 default stream
- Peer-to-Peer Memory Access(PCIe,NVLINK)
cudaDeviceCanAccessPeer()- 可以读取其他 device 上的内存内容
- 条件:64bit app,
cudaDeviceEnablePeerAccess() - linux 上有限制(IOMMU on Linux)
- Peer-to-Peer Memory Copy
- 使用 unified address space 的时候,直接使用普通的
cudaMemcpy() - 否则使用
cudaMemcpyPeer() - device 之间的拷贝,会在两个 device 上任务都完成之后开始,在两个
device 之后的任务启动之前结束
- 和 stream 的并行性质一样,也能并行
cudaDeviceEnablePeerAccess()之后,peer-to-peer 访问不需要通过 host,很快
- 使用 unified address space 的时候,直接使用普通的
Unified Virtual Address Space
- 64 bits + CC>=2.0
- 是否支持:
deviceProp.unifiedAddressing
- 是否支持:
cudaPointerGetAttributes()- 此时不需要指定
cudaMemcpy()的 kind 参数 cudaHostAlloc()默认就是 portable 的(多设备共享)- 地址能够直接使用,不需要使用
cudaHostGetDevicePointer()
Interprocess Communication
- 进程间通信,必须使用 Inter Process Communication API
- IPC API:64 bits + CC>=2.0
- 不支持
cudaMallocManaged()的内存 cudaIpcxxx()
Error Checking
- 异步:检查
cudaDeviceSynchronize()的返回值 - 每一个 host thread 都有一个用于设置 error 的变量
- 初始化为
cudaSuccess cudaPeekAtLastError()返回 error,cudaGetLastError()返回并重置为cudaSuccess
- 初始化为
- kernel 启动是异步的,因此需要在 kernel 启动前将 error 变量重置(用以检查 kernel 的错误)
- 注意:
cudaStreamQuery()、cudaEventQuery()可能会返回cudaErrorNotReady- 但是这个并不被视为错误,所以不能被
get/peek
- 但是这个并不被视为错误,所以不能被
Call Stack
- 调用栈的大小:
cudaDeviceGetLimit()、cudaDeviceSetLimit()
Texture and Surface Memory
Texture Memory
- 支持部分 texturing hardware 的功能
- texture or surface memory instead of global memory 有优势(DMA)
- texture object
1D、2D、3D- texels
1-、2-、4-8-int、16-int、float
- read mode
cudaReadModeNormalizedFloat:解析成[0,1]/[-1,1]之间的 floatcudaReadModeElementType:没有转换
- 索引:float
[0,N-1](未归一化) - addressing mode:越界时候的寻址模式
- filtering mode:插值
- Texture Object API:introduces the texture object API.
- spitch:height 每次增加多少
- 16-Bit Floating-Point Textures:explains how to deal with 16-bit
floating-point textures.
- device:
__float2half_rn(float)and__half2float(unsigned short) - host:openEXR lib
- device:
- Layered Textures
cudaMalloc3DArray()with thecudaArrayLayeredflagtex1DLayered()andtex2DLayered()
- Cubemap Textures、Cubemap Layered Textures
cudaMalloc3DArray()with thecudaArrayCubemapflag (andcudaArrayLayeredflag)- 具体使用见表:
texCubemap()、texCubemapLayered()
- Texture Gather:describes a special texture fetch, texture gather.
- 要求:2d only、
cudaArrayTextureGather、CC>=2.0 tex2Dgather()- 返回用于插值的 4 个 texel 的对应通道的数据(例如 4 个 alpha 值)
- 会有精度问题(8bit):1.9 => 近似成 2.0 => 返回 2+3
- 要求:2d only、
Surface Memory
- surface 可读且可写的,texture 只读
- CC>=2.0
cudaArraySurfaceLoadStoreflag- surface object
- byte addressing:需要乘上每一个元素的大小
sizeof(float) - 和 texture 类似
CUDA Arrays
- 对 texture fetching 做了不透明的优化,只能通过 texture/surface api 使用
Read/Write Coherency
- kernel 内部读写不一致
- 在同一个 kernel 调用中被缓存,因此在同一个 kernel 调用中可能存在不一致