0%
Theme NexT works best with JavaScript enabled
cuda
CUDA C++ Programming Guide (Release12.2)
环境:RTX 3080、cuda 11.7
PDF
Introduction
The Benefits of Using GPUs
CUDA: A General-Purpose Parallel Computing Platform and Programming
Model
A Scalable Programming Model
核心
a hierarchy of thread groups
shared memories
barrier synchronization
Programming Model
Kenels
Kernels
__global__、threadIdxCPU 调用,GPU 执行
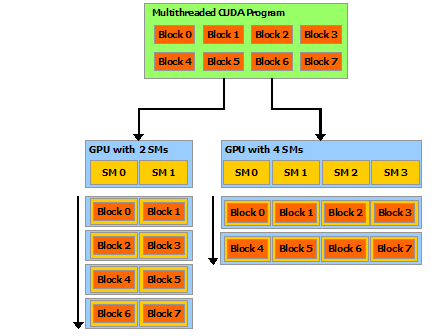
Thread Hierarchy
threadIdx.xyz: (x, y, z)列优先 :idx = x + y Dx + z Dx Dy调用
1 2 MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
含有 cuda 关键字的文件需要后缀名标识为
.cu/.cuh,否则编译可能有问题(不被 nvcc 识别)
Thread Hierarchy
一个 block 里的 thread 在同一个 SM
上运行 (同时调度)
限制为 1024(deviceProp.maxThreadsPerBlock)
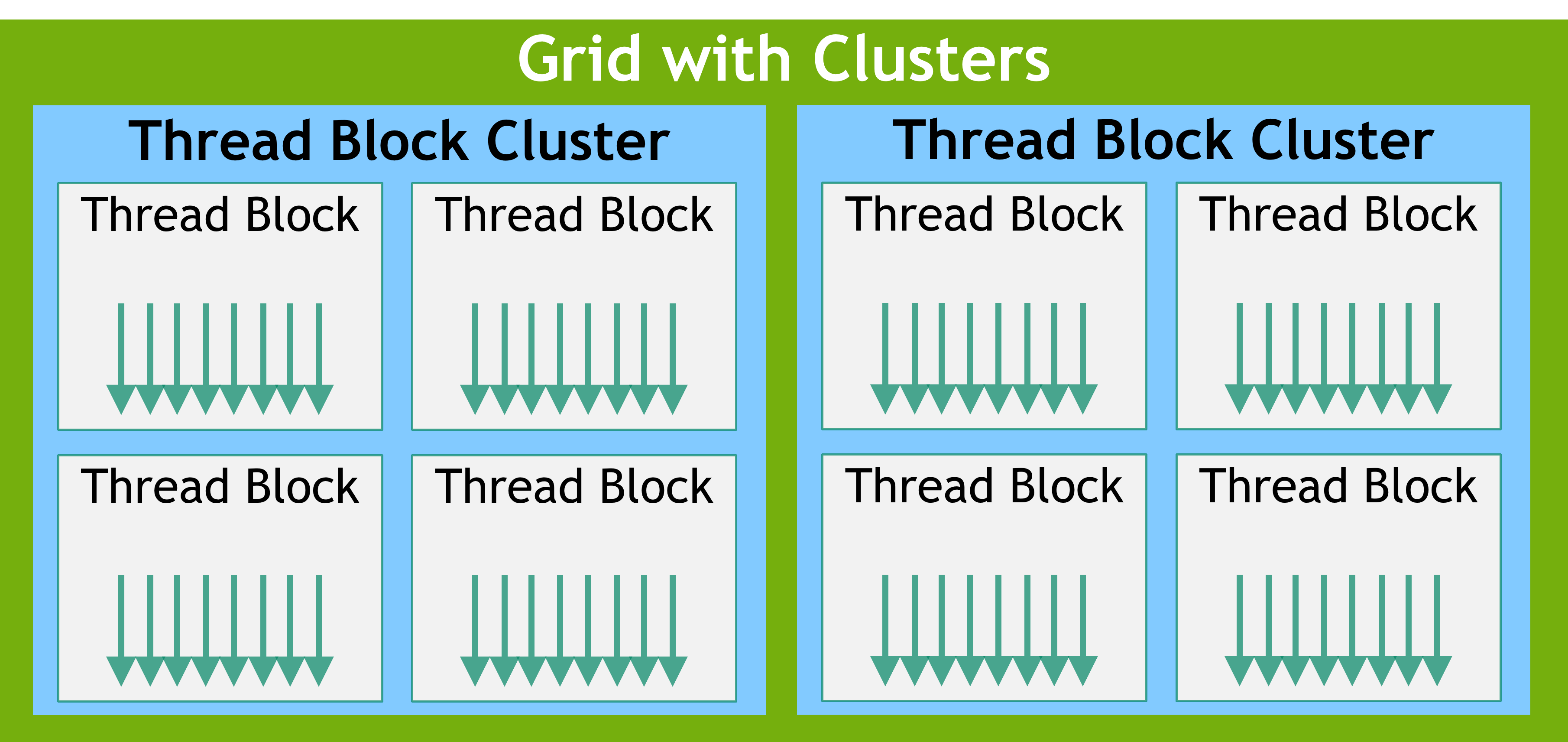
组织层级:Grid > Block > Cluster > Thread
1 2 3 4 5 6 gridDim; blockIdx; blockDim; threadIdx;
block 内 thread
共享 shared memory 内存(类似 L1 Cache)
block 内所有 thread 的同步:__syncthreads()
Cluster:cluster 上的 block 可以被同时调度
硬件级别的同步 要求 Compute Capability >= 9.0(cuda 12.x)
Check Compute Capability
1 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\demo_suite\deviceQuery.exe
在启用 Cluster 之后,Grid 还是表示里面有多少个
Block Cluster 启动,具体再看文档吧,暂时用不到
compiler time:kernel attribute __cluster_dims__(X,Y,Z)
(此时 cluster size 不能修改)
runtime:cudaLaunchKernelEx
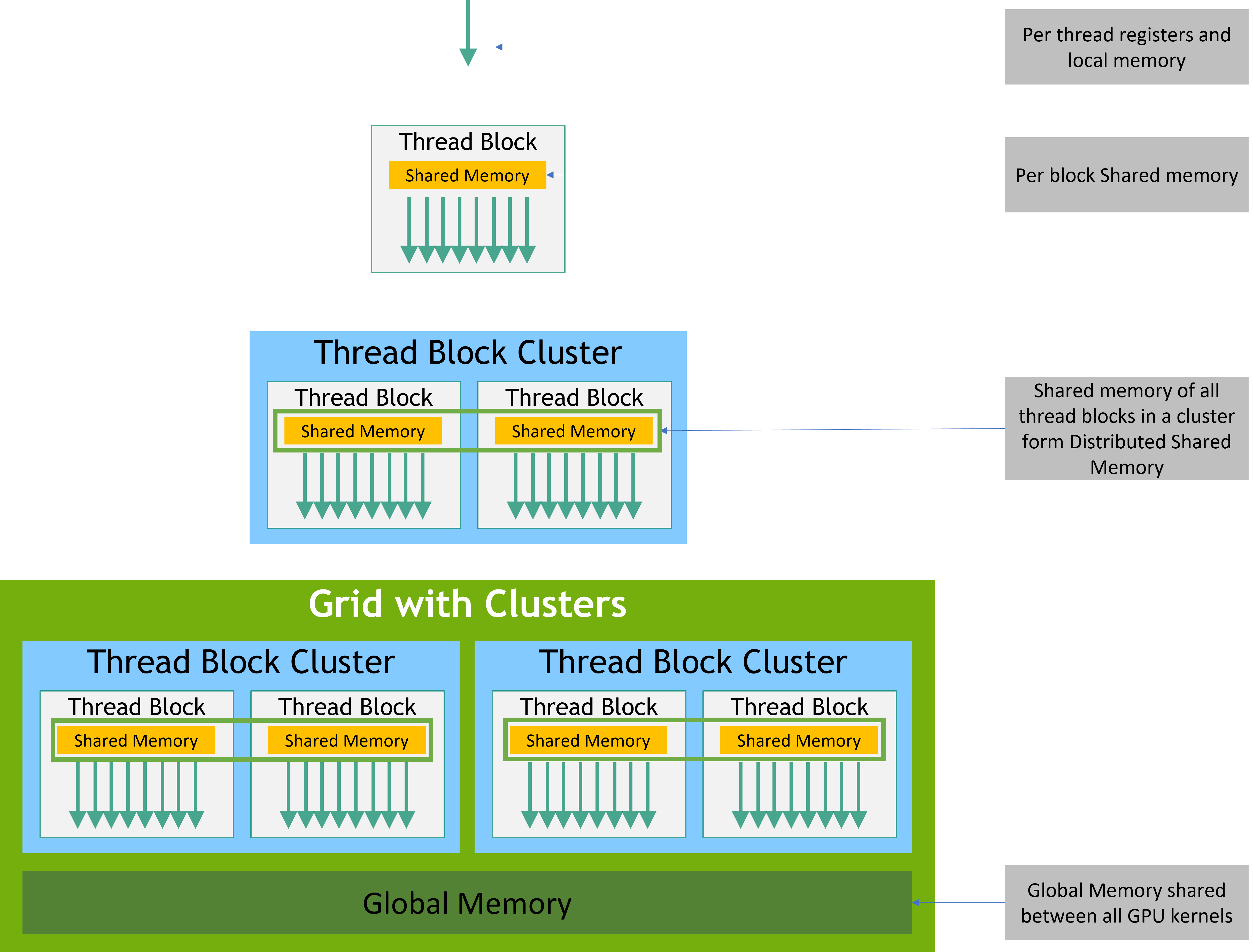
Memory Hierarchy
Thread 有私有的 local memory
Cluster 内部的 Block 能对 Cluster 内部所有 Block 上的 shared memory
进行读、写、原子操作
所有 Thread 都能访问,都是持久化的(persistent)
global memory
只读内存:constant、texture
Heterogeneous Programming
异构编程
separate memory spaces in DRAM
host memory device memory
Unified Memory:managed
memory
Asynchronous SIMT
Programming Model
同步操作(内存拷贝为例)
显式:cuda::memcpy_async
隐式:cooperative_groups::memcpy_async
同步
cuda::barriercuda::pipeline
同步范围(Thread Scope)
扩展实现
libcu++,The C++ Standard Library for Your Entire System
1 2 3 4 cuda::thread_scope::thread_scope_thread; cuda::thread_scope::thread_scope_block; cuda::thread_scope::thread_scope_device; cuda::thread_scope::thread_scope_system;
Compute Capability
also:SM version
RTX 3080:Ampere 架构、8.6
9
Hopper
8
Ampere
7.5
Turing
7
Volta
6
Pascal
5
Maxwell
3
Kepler
Tesla 架构(Cuda 7.0 之后不再支持)Feimi 架构(Cuda 9.0 之后不再支持)
Programming Interface
Compilation with NVCC
cuda kernel
cuda 指令集:The Parallel Thread Execution (PTX)
nvcc 编译
Compilation Workflow
Offline Compilation
nvcc
待编译的代码可以包含 host+device 的代码
工作流
device code:编译成 PTX code(assembly)和/或 cubin
object(binary)
host code:语法替换,加载编译好的 device 代码
JIT Compilation
nvrtc
runtime:device driver 执行(PTX -> binary)
编译了一份之后,会自动缓存避免重复编译
Binary Compatibility
cubin object
architecture-specific
编译选项:-code
-code=sm_80:compute capability 8.0
cubin object:compute capability X.y 的代码只能在
X.z(z>=y)的硬件下运行
只支持 desktop,不支持 Tegra(图睿,ARM 架构,面向手持式设备)
PTX Compatibility
编译选项:-arch
-arch=compute_50:compute capability 5.0
有一些 PTX 指令需要满足 compute capability 限制
PTX code 可以被编译成更高 compute capability 的
cubin,但是这样不能保证使用新的硬件特性
Application Compatibility
1 2 3 4 5 nvcc x.cu -arch=compute_50 -code=sm_50 # or nvcc x.cu -gencode arch=compute_50,code=sm_50 # or nvcc x.cu -arch=sm_50
64-Bit Compatibility
C++ 是 64-bit 时,此时使用 64-bit 的 cuda-toolkit 编译得到的才能支持
64bit
CUDA Runtime
cudart 库
Windows:cudart.lib,cudart.dll
entry point 都是以 cuda 开头的
主要内容
Shared Memory、Page-Locked Host Memory、Asynchronous Concurrent
Execution、Multi-Device System、Error Checking、Call Stack、Texture and
Surface Memory、Graphics Interoperability
Initialization
1 2 3 4 5 6 7 8 cudaInitDevice ();cudaSetDevice (); cudaInitDevice ();cudaSetDevice (); cudaFree (0 );
runtime 为每一个 device 创建一个 context(primary context),context
在第一次被调用的时候初始化
device code JIT 编译是初始化的一部分
cudaDeviceReset():删除当前的 contextcuda 接口的使用:global state,在 host 代码 initialization ~
termination 之间被激活
Device Memory
texture:不透明的优化
device memory:linear memory
single unified address space
地址大小如下
up to compute capability 5.3 (Maxwell)
40bit
40bit
40bit
compute capability 6.0 (Pascal) or newer
up to 47bit
up to 49bit
up to 48bit
1 2 3 4 5 6 cudaMalloc ();cudaFree ();cudaMemcpy ()
其他:alignment 优化
返回的 pitch (or stride) 用于索引
1 2 3 4 5 6 7 cudaMallocPitch (); cudaMalloc3D (); cudaMemcpy2D ();cudaMemcpy3D ();
内存不够
slower memory type:cudaMallocHost(),
cudaHostRegister()
不分配,返回原因;或者使用 cudaMallocManaged()
varables in global/constant memory space
1 2 3 4 5 6 cudaMemcpyToSymbol ();cudaMemcpyFromSymbol ();cudaGetSymbolAddress (); cudaGetSymbolSize ();
Device Memory L2 Access
Management
global 的数据访问方式
多次访问:persisting
只访问一次:streaming
Cuda>11.0+CC>8.0:影响 L2 cache
的持久性,以提高效率(set-aside)
预留一部分 L2 cache
用于持久化(这一部分只有在空闲的时候才会被当作正常 L2 cache)
1 2 3 4 5 cudaGetDeviceProperties (&prop, device_id);size_t size = min (int (prop.l2CacheSize * 0.75 ), prop.persistingL2CacheMaxSize); cudaDeviceSetLimit (cudaLimitPersistingL2CacheSize, size);cudaDeviceSetLimit (&size, cudaLimitPersistingL2CacheSize);
Multi-Instance GPU (MIG) mode:set-aside 失效
Multi-Process Service (MPS) mode:set-aside 无法通过 Set
设置,只能通过环境变量配置
CUDA_DEVICE_DEFAULT_PERSISTING_L2_CACHE_PERCENTAGE_LIMIT
L2 Policy for Persisting Accesses
控制某块区域的内存使用 set-aside 策略的具体细节
更高概率使用 set-aside
1 2 3 4 5 cudaStreamSetAttribute (stream, cudaStreamAttributeAccessPolicyWindow, &stream_attribute);cudaGraphKernelNodeSetAttribute (node, cudaKernelNodeAttributeAccessPolicyWindow, &node_attribute);
L2 Access Properties:数据保留在 set-aside 中的偏好
1 2 3 4 5 6 7 8 enum __device_builtin__ cudaAccessProperty { cudaAccessPropertyNormal = 0 , cudaAccessPropertyStreaming = 1 , cudaAccessPropertyPersisting = 2 };
1 2 3 cudaAccessPropertyNormal (); cudaCtxResetPersistingL2Cache ();
L2 Cache 被所有 kernel 共享,应用设计需要考虑如下因素
L2 set-aside cache 大小
并行的 cuda kernel 数量
access policy
何时重置优先级
硬件限制:cudaGetDeviceProperties
当前配置:cudaDeviceGetLimit
Shared Memory
__shared__比 global memory 快很多
scratchpad memory (or software managed cache)
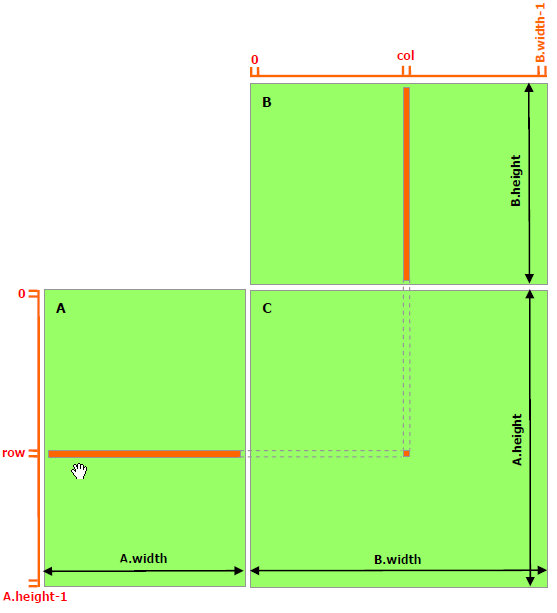
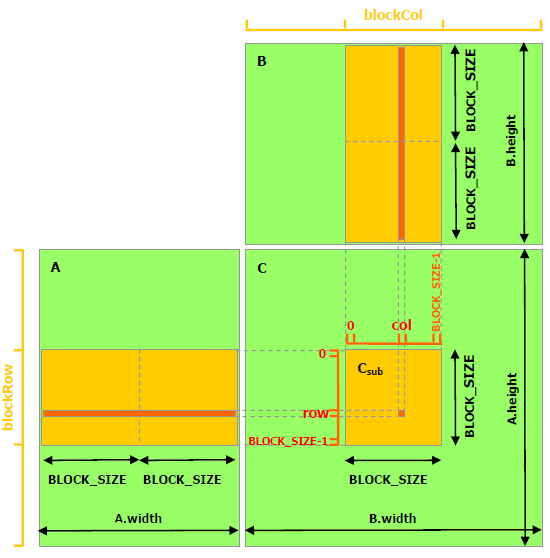
矩阵乘法例子
\(A\times B=C\) 一个 thread 求解一个结果
一个 Block 计算对应一个 block 中的内容
Block 中的一个 Thread 计算其中对应一个元素
缓存到 shared memory 上,降低访问延迟(TODO:测试却更慢了 )
Distributed Shared Memory
CC >= 9.0
就是 Cluster 内所有 shared memory 的总和
可以实现 Cluster 内所有 Thread 的同步
Page-Locked Host Memory
page-locked (also known as pinned ) host
memory
1 2 3 4 5 6 7 8 9 cudaHostAlloc ();cudaFreeHost ();cudaMalloc ();cudaFree ();cudaHostRegister ();
好处
page-locked <-> device,拷贝数据可以和 kernel 的执行并发
某些 device,支持 page-locked 可以直接 map 到 device memory
某些 device,page-locked <-> device 拷贝数据更快
Portable Memory(cudaHostAllocPortable)
Write-Combining Memory(cudaHostAllocWriteCombined)
取消 L1+L2 缓存
PCIE 总线传输的时候不被监听,数据传输效率高
读很慢,一般只用于只写的 host memory
WC memory:CPU atomic 操作不一定有效
Mapped Memory(cudaHostAllocMapped)
直接映射到 device memory(2 address)
cudaHostGetDevicePointer要求
硬件支持
cuda 初始化时候设置 flag:cudaSetDeviceFlags() with
cudaDeviceMapHost
缺点:
优点:
不需要显式的数据传输
不需显式使用 stream 将数据传输与 kernel 执行重合
kernel 的原子操作对 host/其他 device 不是原子的
Memory Synchronization
Domains