0%
Theme NexT works best with JavaScript enabled
连接运算
嵌套循环连接
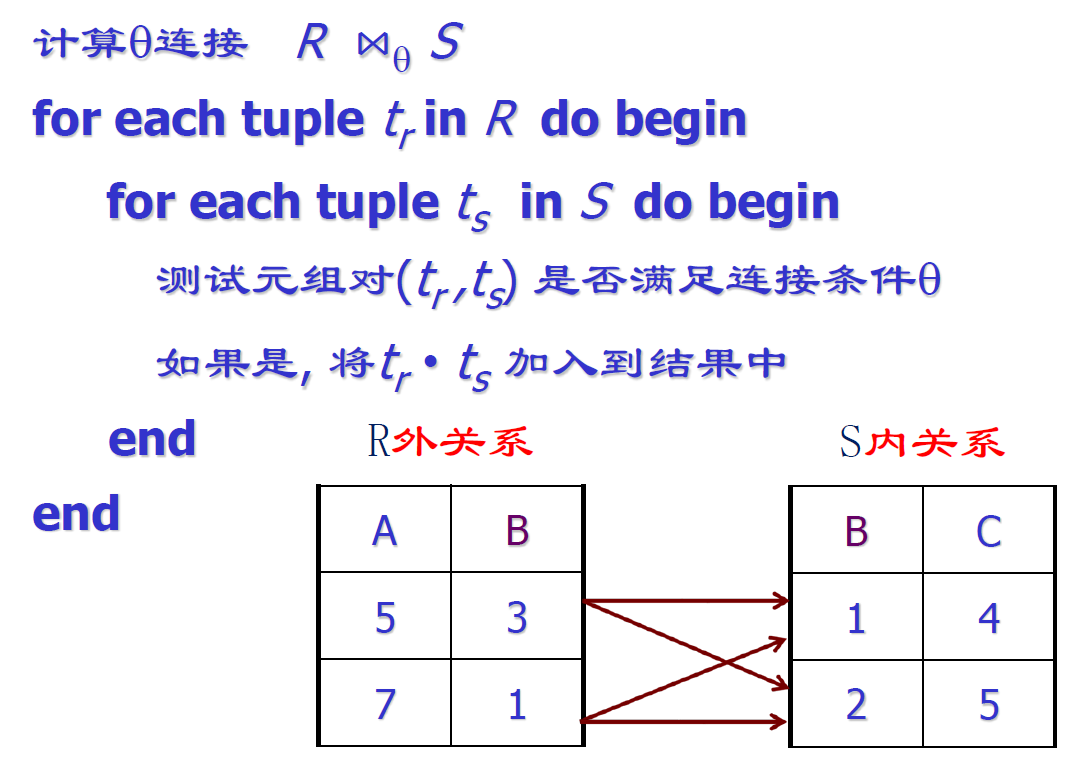
外关系、内关系
嵌套循环连接无需索引,可用于任何连接条件
两个规模不一的关系,谁作为外关系?
如果其中一个关系的连接属性上存在索引,并且执行的是等值连接,则可以利用索引查找代替文件扫描
存在索引的关系是作为外关系还是内关系?
嵌套循环连接
1 2 3 4 5 6 7 8 for each tuple tr in r do begin for each tuple ts in s do begin test pair(tr,ts) to see if they satisfy the join condition theta if they do, add trxts to the result end end
优点
对参加运算的关系没有要求,甚至于一个关系的各个元组可以物理上不是相邻存储的
适合于任何连接条件
代价分析
来源 假设我们有 s 和 t 两张表,现在要做 JOIN
s 表的记录数设为 5000,占据的块数设为 100
t 表的记录数设为 10000,占据的块数设为 400
嵌套循环连接
以一张表的每一行记录,与另一张表的每一行记录比较
两层 for 循环
若从 s 表的每行记录出发,最坏情况下
块传输次数是 5000×400+100=2000100,搜索次数是 5000+100=5100
若从 t 表的每行记录出发,最坏情况下
块传输次数是 10000×100+400=1000400,搜索次数是 10000+400=10400
块嵌套循环连接
一个小小的优化思路:每次以块的方式处理关系
若从 s 表的每块出发,最坏情况下
块传输次数是 100×400+100=40100,搜索次数是 2×100=200
若从 t 表的每块出发,最坏情况下
块传输次数是 400×100+400=40400,搜索次数是 2×400=800
索引嵌套循环连接
如果连接的字段上有 B+ 树索引,设每个节点有 20 个索引项,t 表记录数为
10000,那么树的高度就是4,回表假设再加一次磁盘IO,此时访问次数为100+5000×5=25100,每次访问都有一次搜索和一次块传输
咦,怎么用了索引反而代价更高了?大家注意下,这里只说了 t
表上有索引,如果 s
表上也有索引且有个选择操作的话,行数会大大减少。使用索引会比块嵌套要快得多得多
归并连接
在当前 R 和 S 的前端查找连接属性的最小值
如果这个值在另一个关系的前部没有出现,那么就删除具有这个值的元组
否则,找出两个关系中的这个值的所有元组,进行连接,输出和这个值相关的所有得到的结果元组
如果一个关系在内存中已经没有要考虑的元组了,那么就重新装载为这个关系而设定的缓冲区
散列连接
适用于自然连接 和等值连接
基本思想
将两个关系按连接属性值划分成有相同散列函数值 的元组集合
关系 r 在一个散列划分中的元组只需要与关系 s
在对应的划分中的元组相比较
在 r 和 s 的每一对划分中进行索引嵌套循环连接(散列索引)
各种连接策略比较
如果一个连接输入很小(比如不到10行),而另一个连接输入很大而且已在其连接列上创建索引,则索引嵌套循环是最快的连接操作
如果两个连接输入很大,并已在二者连接列上排序(连接列上有索引),则合并连接是最快的连接操作
哈希连接可以处理很大的、未排序的非索引输入
如果两个连接输入都很大,而且这两个输入的大小差不多,则预先排序的合并连接提供的性能与哈希连接相似。然而,如果两个输入的大小相差很大,则哈希连接操作通常快得多
合并连接和哈希连接只能用于等值连接 ,对于非等值连接,只能用嵌套循环连接