0%
数据库存储
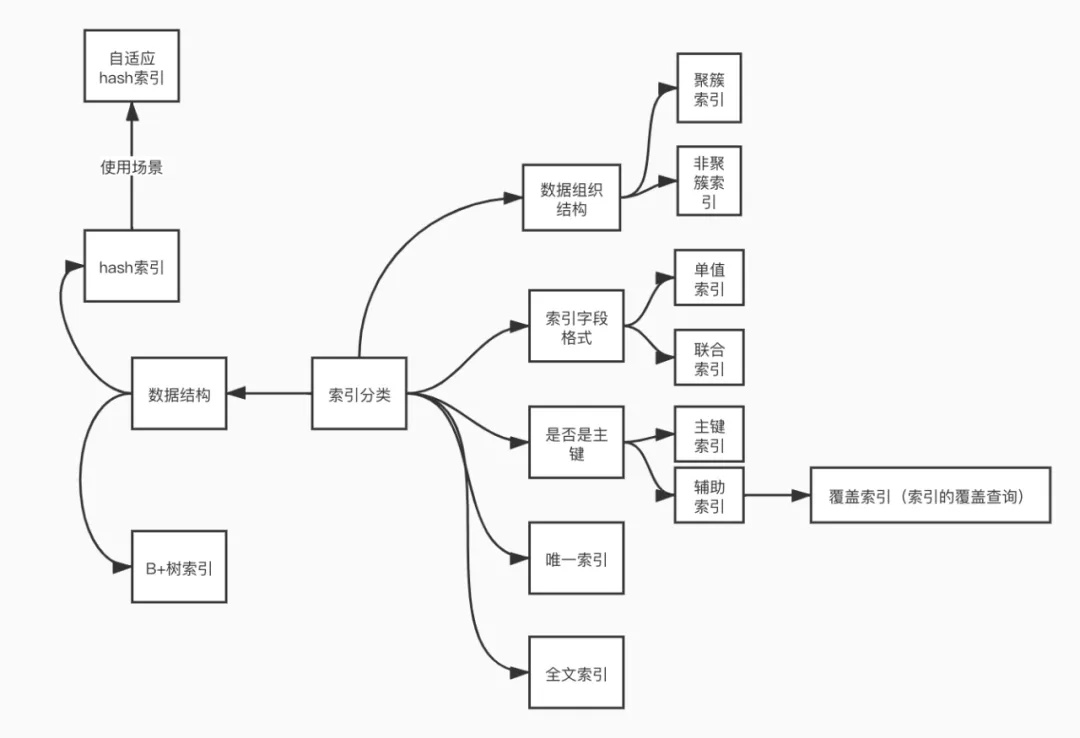
索引
- 索引类型
- 顺序索引:基于值的顺序排序
- 散列索引:基于将值平均分布到若干散列桶中
- 索引评价指标
- MySQL 索引
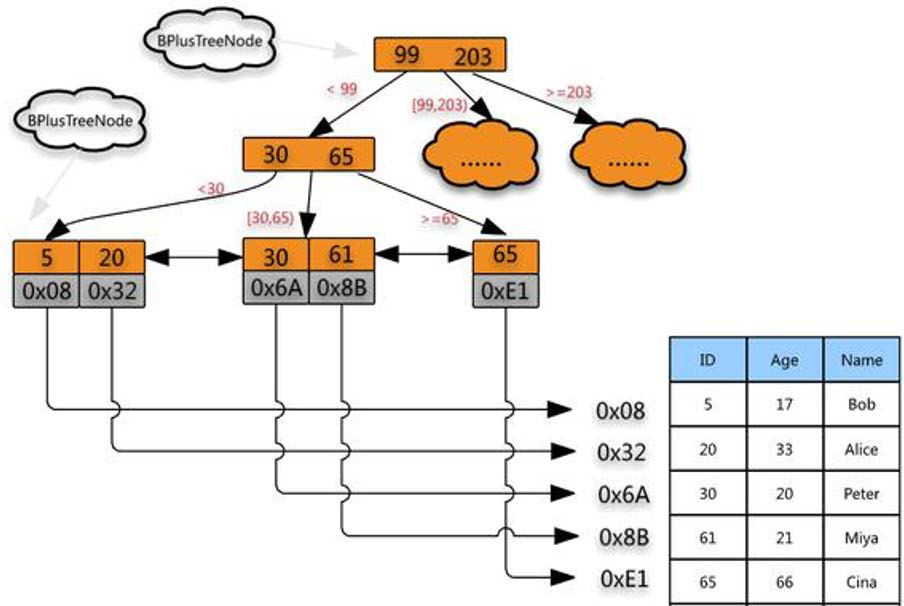
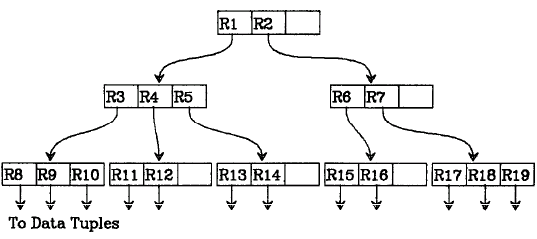
B+树索引

- 每个非叶结点有 \(\lceil\dfrac{n}{2}\rceil\) 到 \(n\) 个子女
- n=3
插入操作
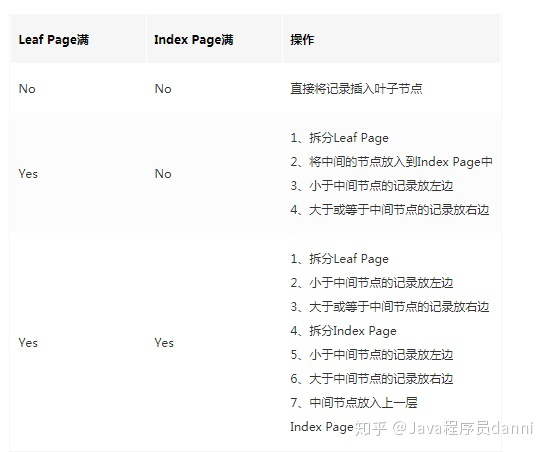
删除操作

B+树 vs 二叉树
- B+ 树胖而矮
- 假定树结点大小与磁盘块大小相等,为4k,n=100,有1百万个搜索码,\(\log_{50}(10^6)=4\),访问 4 个磁盘结点
- 二叉树瘦而高
- 二叉树:内存数据库
- B+树:外存索引
B树 vs B+树
B 树
- 所有的 key 值分布在整个树中
- 所有的 key 值出现在一个结点中
- 搜索可以在非叶结点处结束
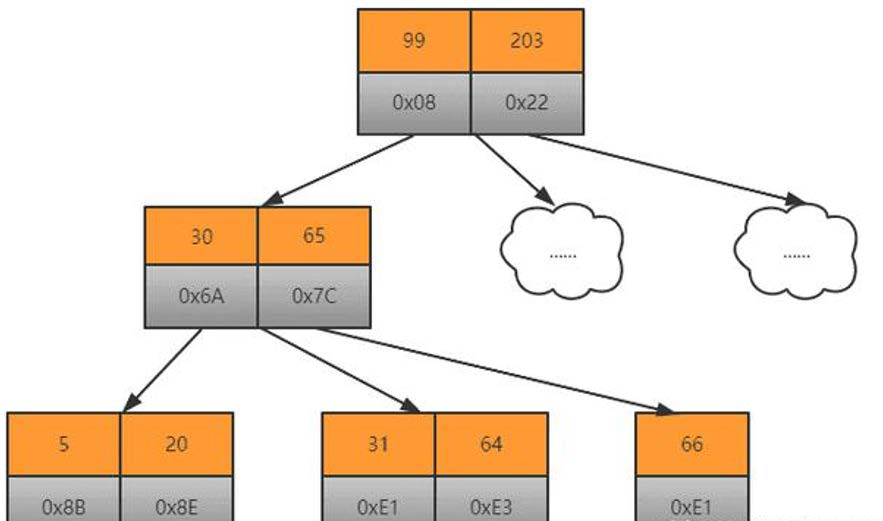
B+ 树
- 叶结点通过两个指针相互链接,顺序查询性能更高
- 叶结点来存储数据,而其他结点用于索引
对比
- B
树不管叶结点还是非叶结点都会保存数据,导致在非叶结点中能保存的指针数量变少(fan
out),要保存大量数据,只能增加树的高度,使得 IO
操作变多,查询性能变低
- B 树查询代价不固定,适合点查询
- B+
树数据在叶结点上,叶子结点之间通过双向链表连接,有利于数据遍历
性能
- InnoDB 一棵 B+ 树可以存放多少行?
- 假定一个页 16K,一行 1k,一页存放 16 行
- 假定主码为 bigint,长度 8 字节,指针 6 字节,共 14
字节,一个页中能存放 16384/14=1170
- 一棵高度为 2 的 B+ 树,能存放 1170 x 16 = 18720
条这样的数据记录
- 一个高度为 3 的 B+ 树可以存放:1170 x 1170 x 16 = 21902400
条这样的记录
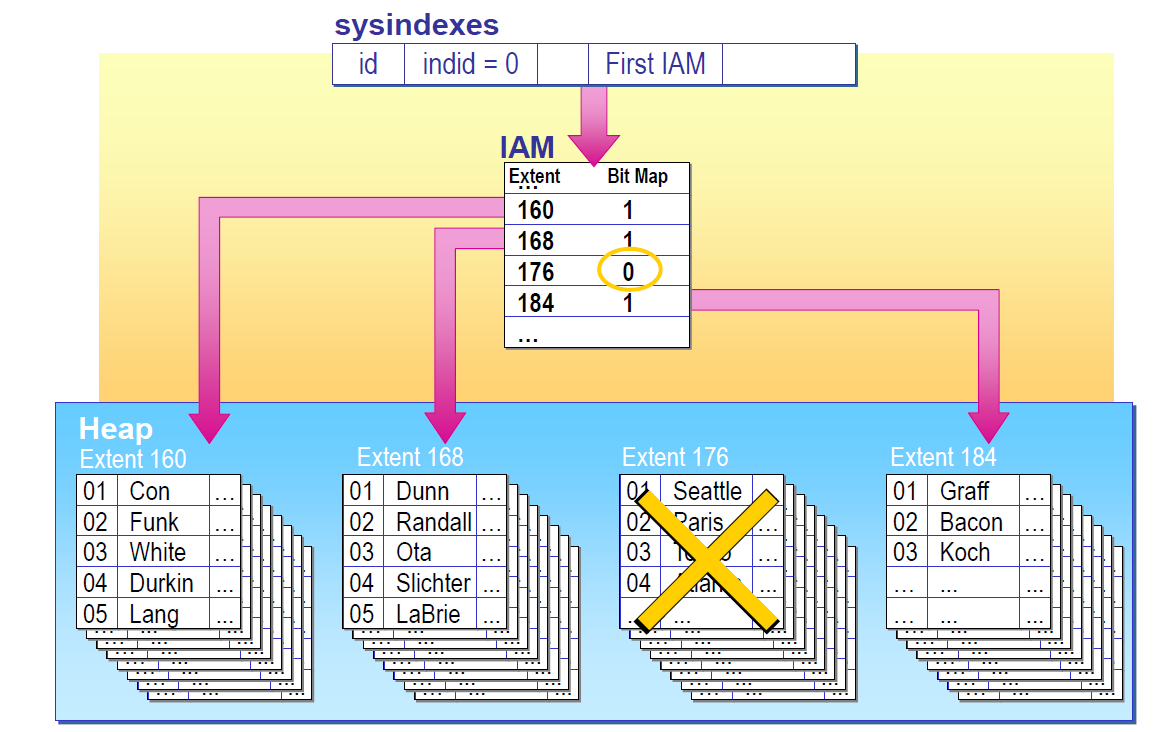
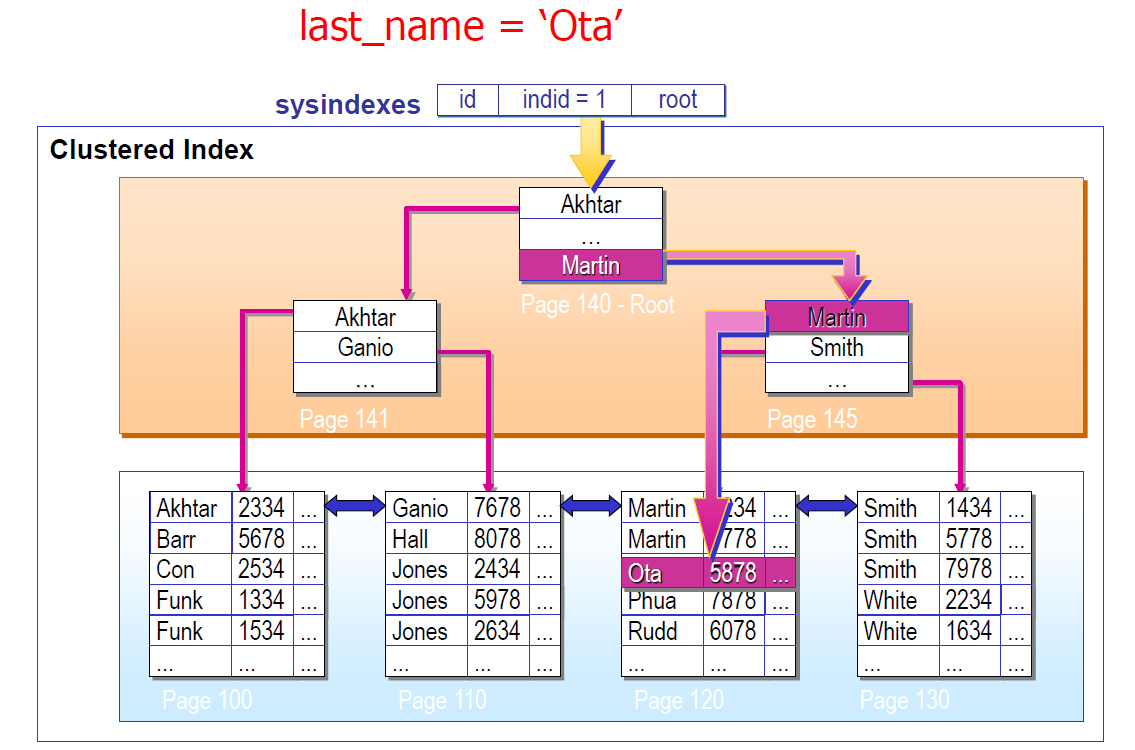
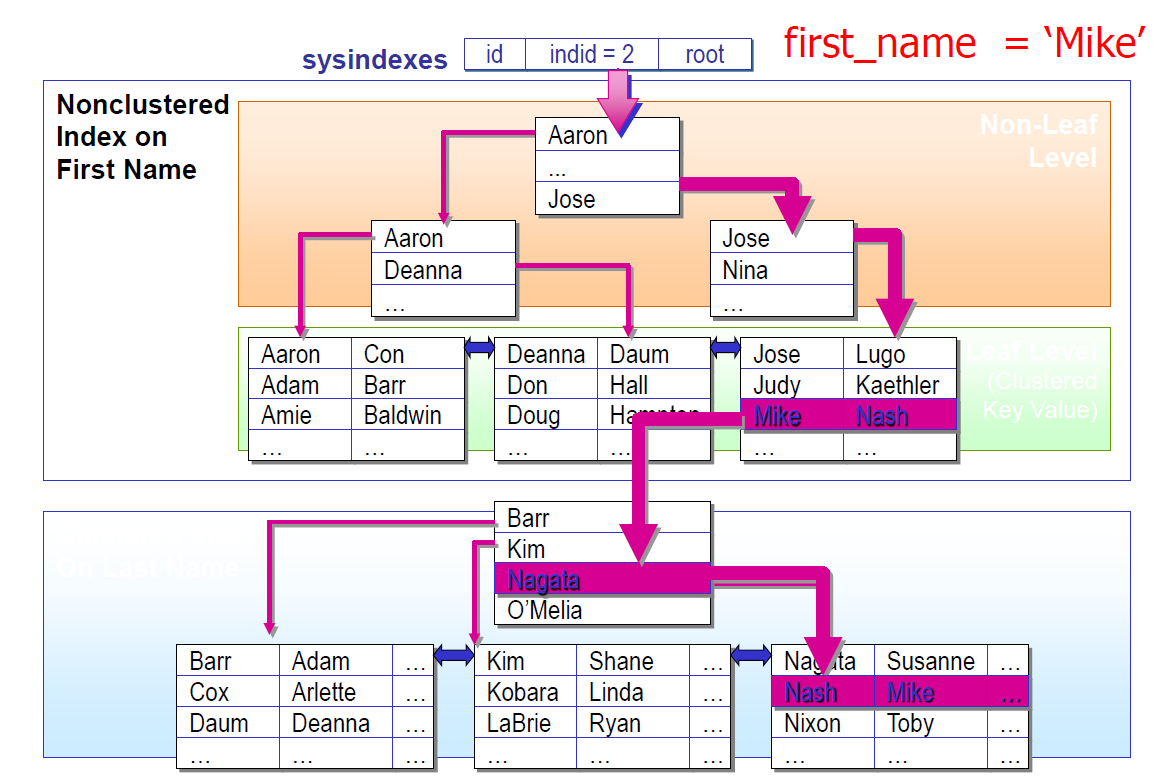
SQL Server 数据查找
堆上的表
聚簇索引
堆上的非聚簇索引
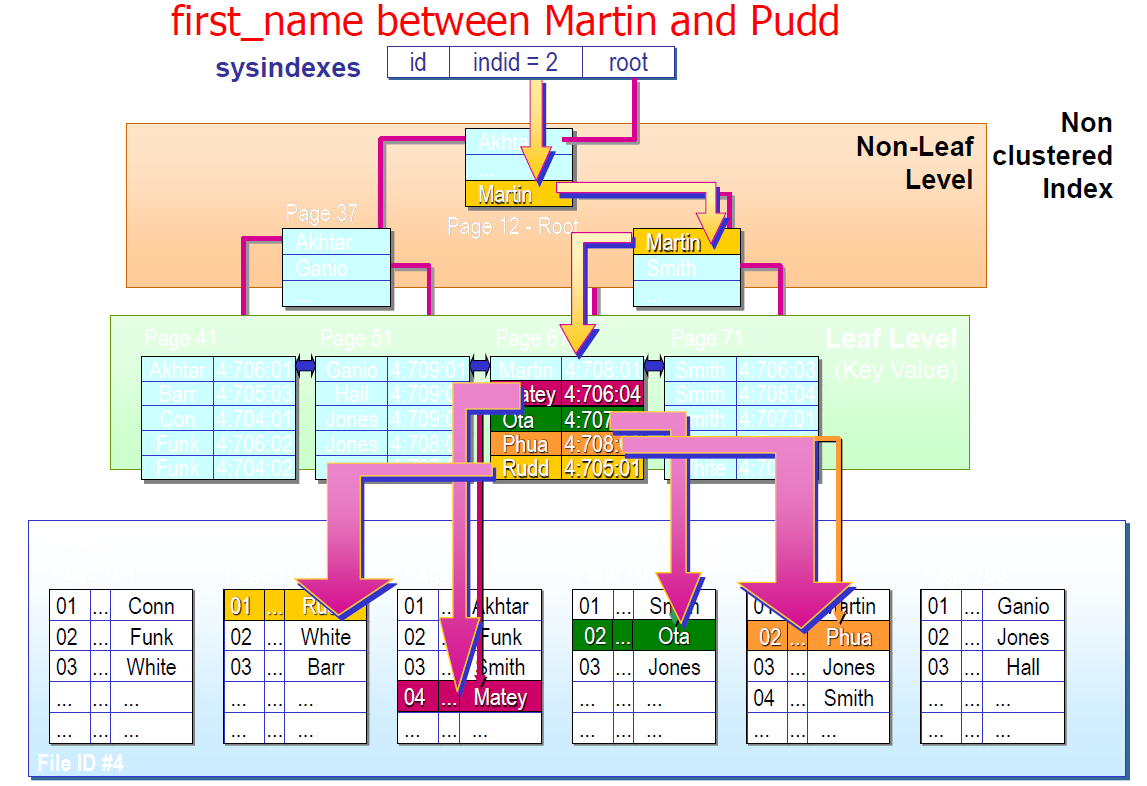
聚簇索引表上的非聚簇索引
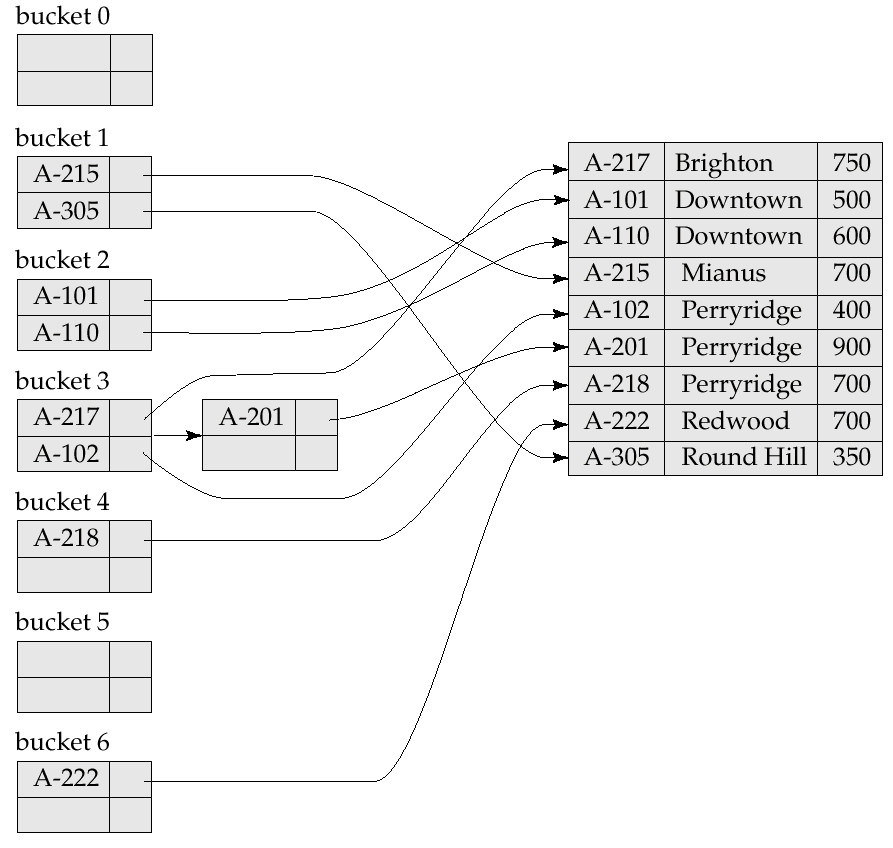
哈希索引
- 散列索引
- 桶(bucket)
- 散列(hash)
- 散列函数 h(K)=B
- K 是搜索码,B 是桶地址
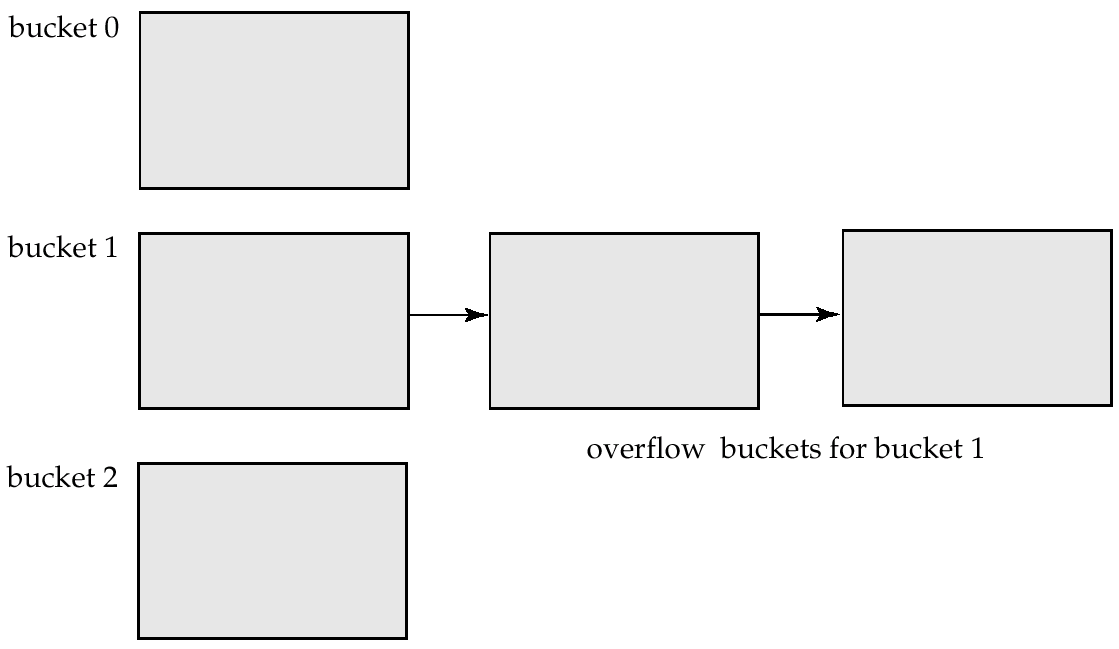
- 桶溢出(bucket overflow)
- 桶不足(insufficient bucket)
- 偏斜(skew)
- 散列函数
- 分布是均匀的,桶包含记录的个数是均匀的
- 分布是随机的,散列值不能与搜索码值呈现出相关性
- 示意图
MySQL 中的散列索引
1
2
3
4
5
| create table testtable(
fname varchar(50) not null,
lname varchar(50) not null,
key using hash(fname)
) ENGINE=MEMORY;
|
- AHI:innodb_adaptive_hash_index
- B+ 树索引的索引
- 当对某个页面访问次数满足一定条件时会将页面地址存于 Hash
表,下次查询时不需要 B+
树那样从根结点到叶子结点逐级查找,只需一次哈希算法即可立刻定位到相应的位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| create table user(
id int,
email char(100),
email_hash int
);
create trigger user_hash_insert
before insert on 'user'
for each row
begin
set new.email_hash=crc32(new.email)
end;
select email, email_hash from user
where email_hash=CRC32("F2dgTSWRBXSZ1d3O@gmail.com")
and email="F2dgTSWRBXSZ1d3O@gmail.com"
|
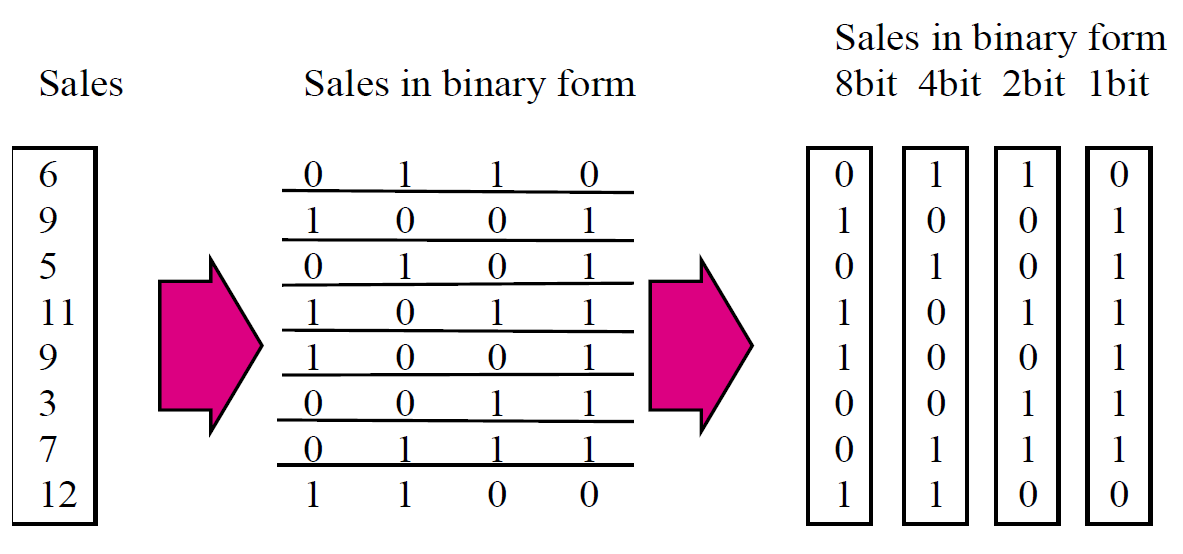
位图索引
- 针对一些特殊的列建立索引
- 列中的每一个值对应一个向量中的一位
- 向量的长度对应与记录的条数
- 不适合列中值的个数太多的情况
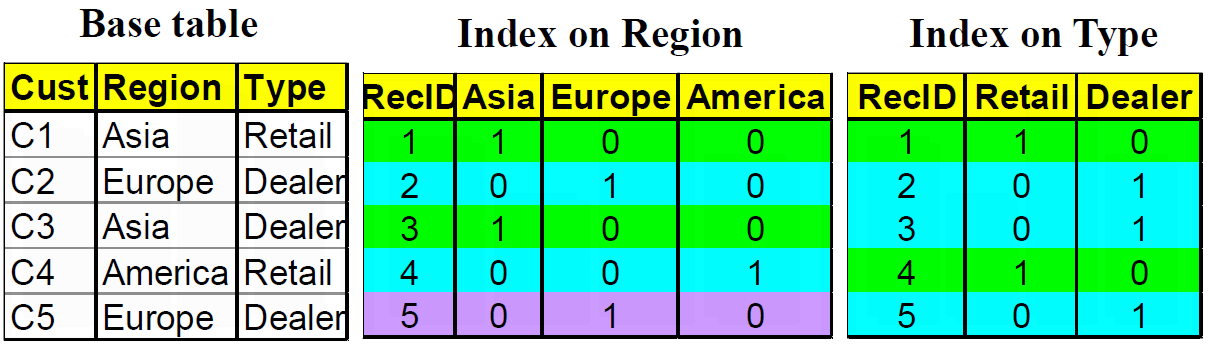
基于位图索引回答查询
1
2
3
| select cust
from BaseTable
Where Region='Asia' and Type='Dealer';
|
- 基于位图索引的话就是向量的与或非操作
- BitMap for Region(Asia):10100
- BitMap for Type(Dealer):01101
- 查询结果:向量与操作:00100
位图索引与 B 树的比较
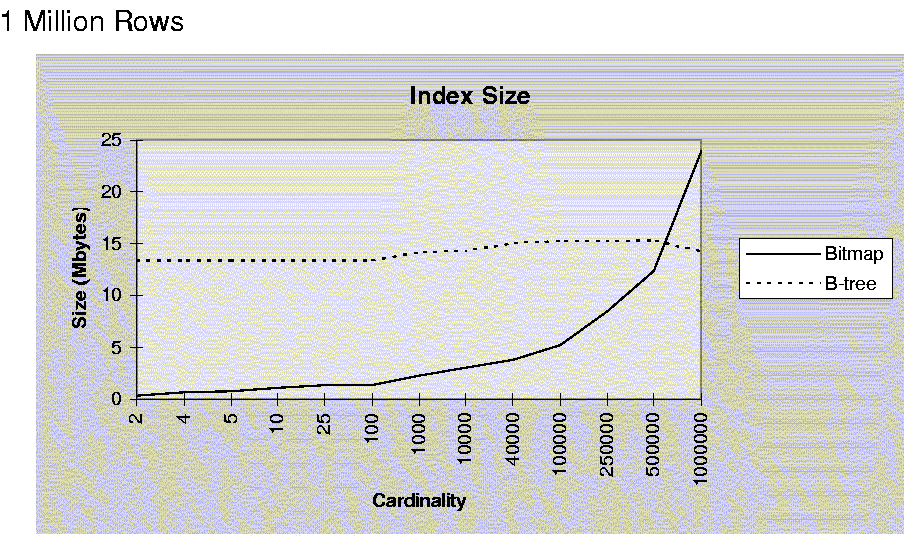
位图索引对分析查询的优势
- 问题:在美国加州有多少男性未申请保险?
- 设表中有 10M 个记录,每个记录长 800 字节,每一页 16K 字节
- 传统全表扫描
- 位图位片索引是将属性列的域值按照某种方式进行垂直分割,然后以二进制位图的形式存储
- 对于 10M 个记录建立三列的位图索引共占(10Mbit*3列/8)
字节的空间,每页 16K,则这些索引仅占 235 页,因此存取这些索引只要 235 次
I/O 操作
位片索引
- Bit-sliced Index
- 位片索引是将属性列的域值按照某种方式进行垂直分割,然后以二进制位图的形式存储
多维索引
多属性查询
- where 10<A<20 and 10<B<20
- 组合索引 idx1 on R(A, B) 或 idx2 on R(B, A)
- 单列索引 idx1 on R(A),idx2 on R(B)
- AB 存在相关性的时候,使用单列估计存在偏差
- 问题:对于查询结果的 Cardinality 估计偏差
k-d 树
- 树顶层结点按一维划分,下一层按另一维划分,保持每侧各落入一半数据,直至结点数小于指定值
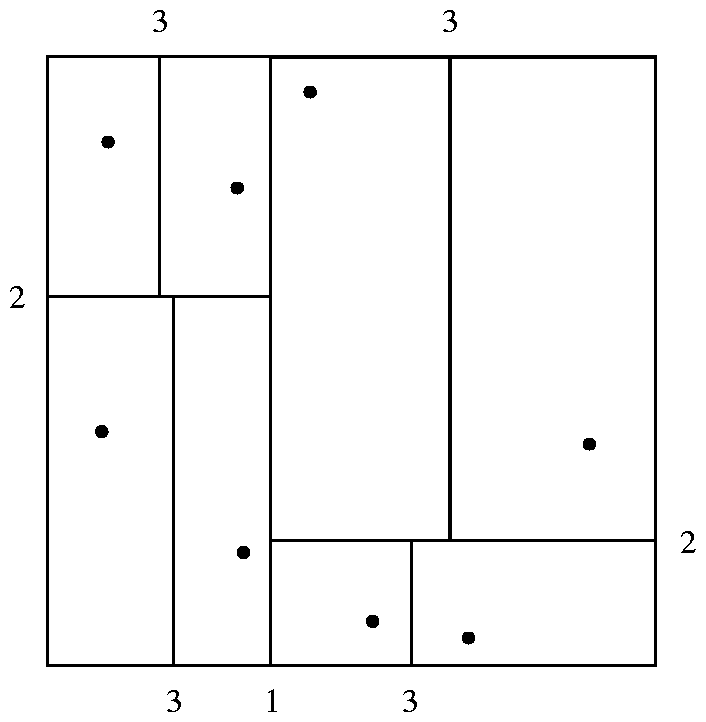
四叉树
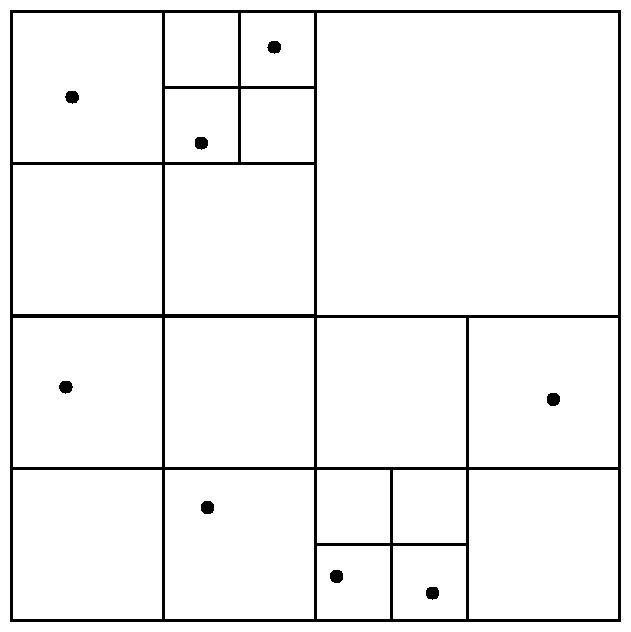
R 树
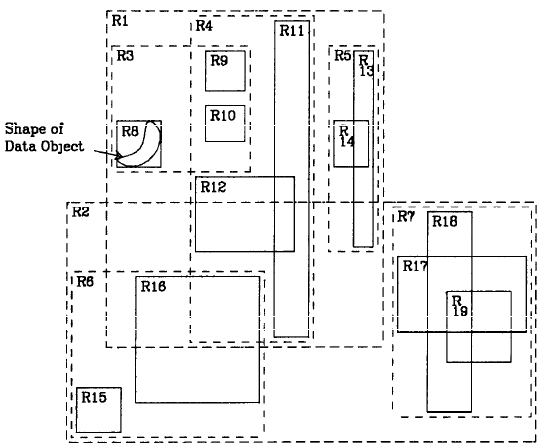
大数据存储
表分区
数据分区

- 使用分区的优点
- 增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用
- 维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可
- 均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能
- 改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度
Oracle
- Oracle 提供三种分区方法
- 范围分区
- 根据某个属性值的范围,决定将该数据存储在哪个分区上
- 散列分区
- 通过分区编号将数据均匀散列到 I/O 设备上,使得这些分区大小一致
- 复合分区
SQL Server
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
create partition function customer_partfunc(int)
as range right
for values(250000,500000,750000)
create partition scheme customer_partscheme
as partition customer_partfunc
to(fg1,fg2,fg3,fg4)
create table customers(
FirstName nvarchar(40),
LastName nvarchar(40),
CustomerNumber int)
on customer_partscheme(CustomerNumber)
|
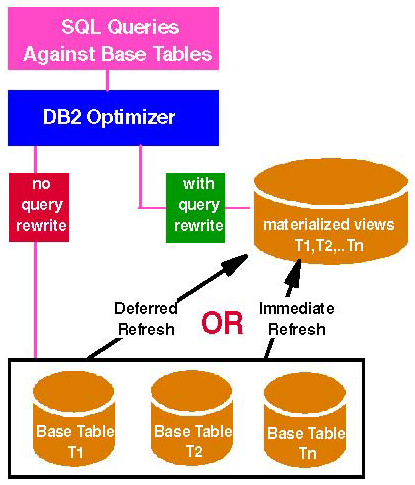
物化视图
- 视图的计算结果被实际存储起来
- 物化视图可以看成是数据库的 cache
- 查询物化视图比重新计算视图要快许多
- 需要进行物化视图与基本表之间的一致性维护
- 应用场合
- 任何需要快速访问派生数据、或视图的重新计算非常昂贵、或查询需要耗费非常高的
CPU 和磁盘吞吐量的应用场合,都可以使用物化视图来提高效率
- 引入物化视图后的体系结构
SQL Server
1
2
3
4
5
6
7
8
9
10
11
|
create view iv_avg_grade(s#,avg_grade,cnts)
with schemabinding
as
select s#,avg(grade),number=count_big(*)
from dbo.SC
group by s#
create unique clustered index idx_avg_grade
on iv_avg_grade(s#)
|
Oracle
1
2
3
4
5
6
7
8
| create materialized view my_grade_aggs
bulid immediate
refresh on commit
enable query rewrite
as
select s#, avg(grade)
from SC
group by s#
|
按列存储
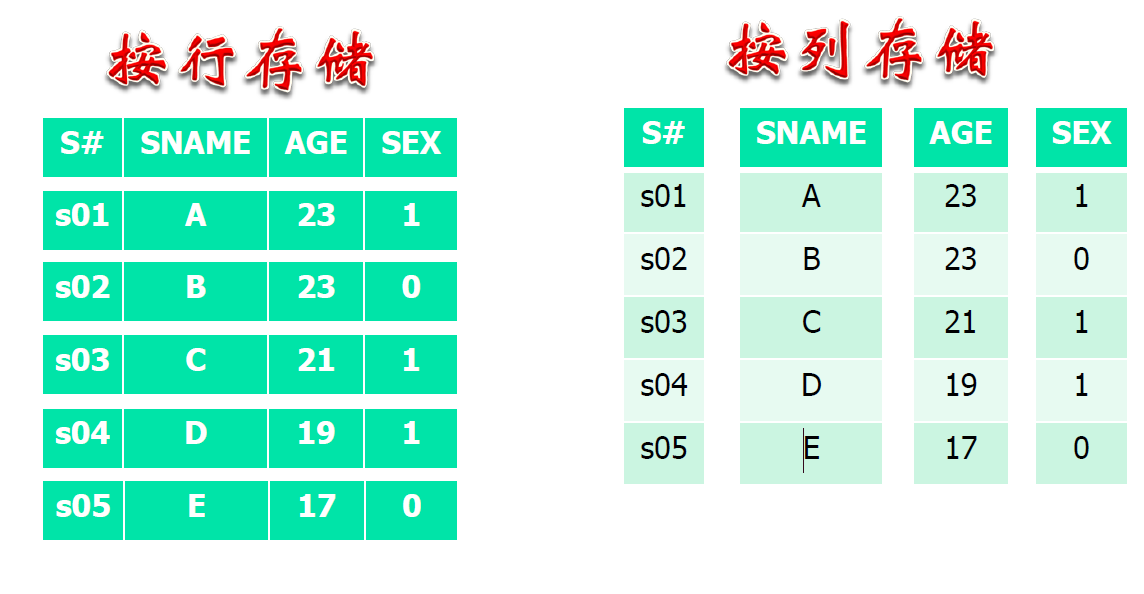
- 按行:访问单条纪录块
- 按列:大规模处理数据快
- 按列存储适合数据仓库、大规模数据分析的场合
按列存储的优点
- 提高带宽利用率
- 按列存储时,只有那些被查询访问的属性才会从磁盘读出;按行存储时,周围属性也被一并读出
- 提高数据压缩率
- 将同一个属性域的数据存储在一起,提高了局部性以及压缩比率
- 传输压缩数据同样减少了带宽
- 提高了 cache 局部性
- cacheline 比一个元组属性要大,因此按行存储时 cacheline
可能会包含不相关的周边属性,浪费 cache 的空间,减少命中率
按列存储的缺点
- 增加了磁盘寻道时间
- 如果需要并行读取多个列,在各个块读之间需要进行磁盘寻道
- 增加插入操作的代价
- 对于插入操作,按列存储的性能很差,因为对每条插入的元组都需要在磁盘的多个不同位置更新
- 增加重构元组的代价
- 按列存储如果想支持标准的关系数据库接口,就必须将多个列拼合起来,构成一条元组输出
按列存储适合的场合
- 数据仓库
- Semantic Web
- 宽表
- 电子商务目录:包含2百万个零件,分成500个目录,每个目录包含4000个属性
- 稀疏列
RDF
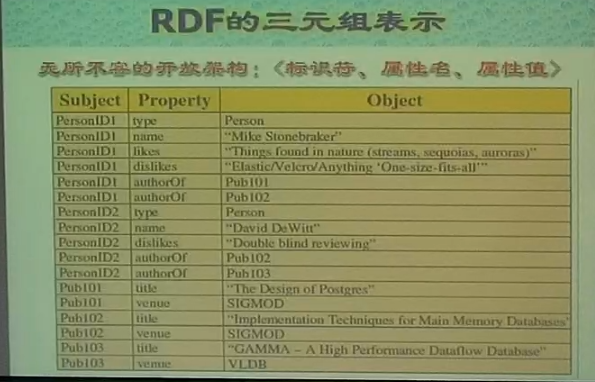

稀疏属性的存储
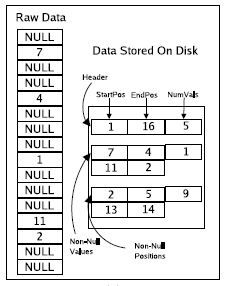
位置列表
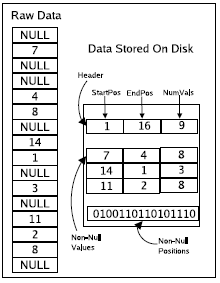
位串
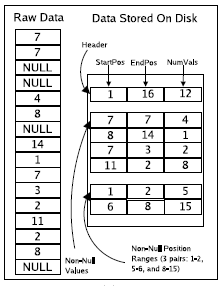
位置范围
比较
- 对于位置列表方式,代价是每个非空值的 32
位额外开销。如果一个列的稀疏度是98%,每个空值的开销是0.65位
- 对于位串方式,位置表示的开销是列中的每个值(不管是否为空)都占用一个位。因此如果一个列的稀疏度是50%,每个空值的开销是
2 个位
- 对于位置范围方式,每个非连续非空值的位置表示开销是
64 位
BLOB 存储
- 直接存储在数据库内
- varchar(max), varbinary(max)
- 存储在文件系统中
- FileStream
- 逻辑上 BLOB 对象与结构化数据是一体的,物理上是分离的
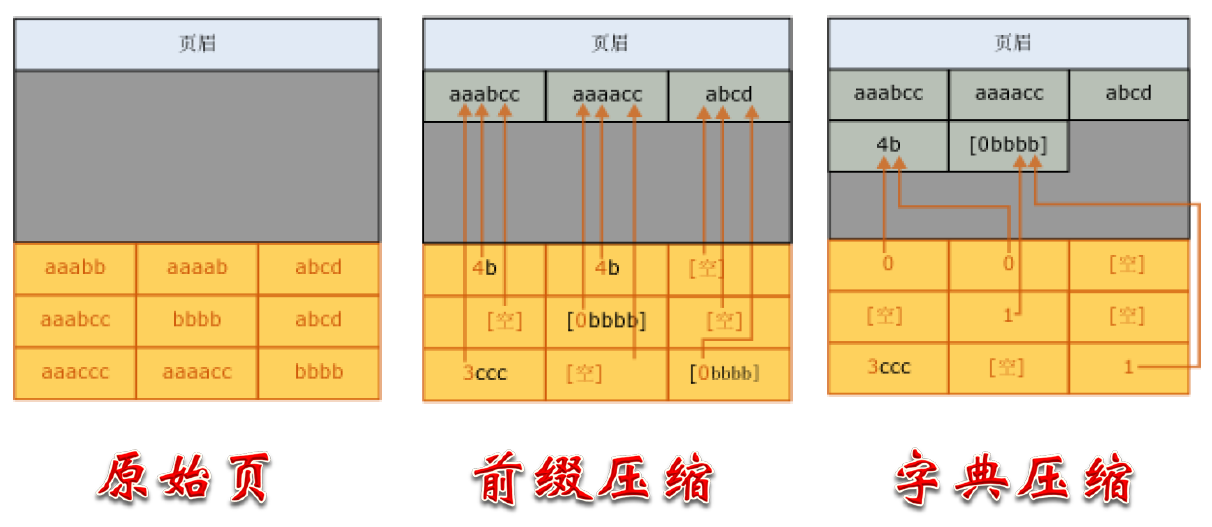
数据压缩
- MySQL 的 compressed 行结构,采用 zlib 压缩算法