数据库概论.陈立军.10.数据库存储(2)
数据库存储
缓冲区
缓冲区管理
- 为快速找到页面,内存页面地址被散列
- dbid-fileno-pageno 标识(数据库ID, 文件号、页面号)的 hash 地址
- 当需要访问一个磁盘块时
- 如果该块已在缓冲区中,返回块在内存中的地址
- 如果块不在缓冲区中
- 缓冲区管理器为该块在缓冲区中分配空间,如果有必要,替换缓冲区中的其他块
- 如果被替换的块被修改过,则将其写回磁盘
- 将所需块调入缓冲区,返回其在缓冲区的地址
被钉住的块
- pinned blocks
- 不允许写回磁盘的块
- 当一个块上的更新正在进行时,不允许写回磁盘
- 可以钉住被频繁访问的小表
块的强制刷出
- forced output of blocks
- 先写日志原则,被更新的数据页刷出时,对应的日志记录被强制刷出
- 生成检查点时,日志和数据缓冲区被强制刷出
- 提交事务时,其日志记录被强制刷出
替换策略
- LRU
- 最近最少使用
- 如果必须替换一个块,则替换最近最少使用的块
- MRU
- 最近最常使用
- 如果必须替换一个块,则替换最近最常使用的块
- 适用于每个数据块只会被操作一次
MRU 在数据库缓冲区管理中的应用场景
- \(R\bowtie S\)
1 | 对于 R 中的每条元组 tr |
- 一旦 R 中的一个元组处理完,就不会再使用它了,应该立即丢弃(toss immediate)
- 当 S 中的一个元组被处理完,只有其他 S 中的元组都被处理完后才会再用到它,应该采用 MRU
- 例子:\(R\bowtie S\)
- R 两条记录 r1、r2,S 两条记录 s1、s2,缓存大小 3
- 使用 MRU,当读入 r2 的时候淘汰 r1
- 实际数据库中使用的都是类似 LRU 的算法
SQL Server 缓冲区
- Lazywriter(缓冲池管理器)
- 使用时钟算法
- 每个缓冲池有一个计数器,当有进程访问该缓冲池时,计数器加一
- 淘汰页面时,Lazywriter 扫描每个缓冲池
- 如果其计数器为 0,则释放该空间(如果发生修改,则写回磁盘)
- 如果计数器不为 0,则计数器减一
MySQL 缓冲区管理
- 链表组织
- \(\dfrac{3}{8}\) 存储老的数据(old),\(\dfrac{5}{8}\) 存储新的数据(young)
- 读进来的新页面放在分界的地方
- 自然按照链表的顺序淘汰页面
- 如果页面被访问到了,则将其放到新数据链表的头部
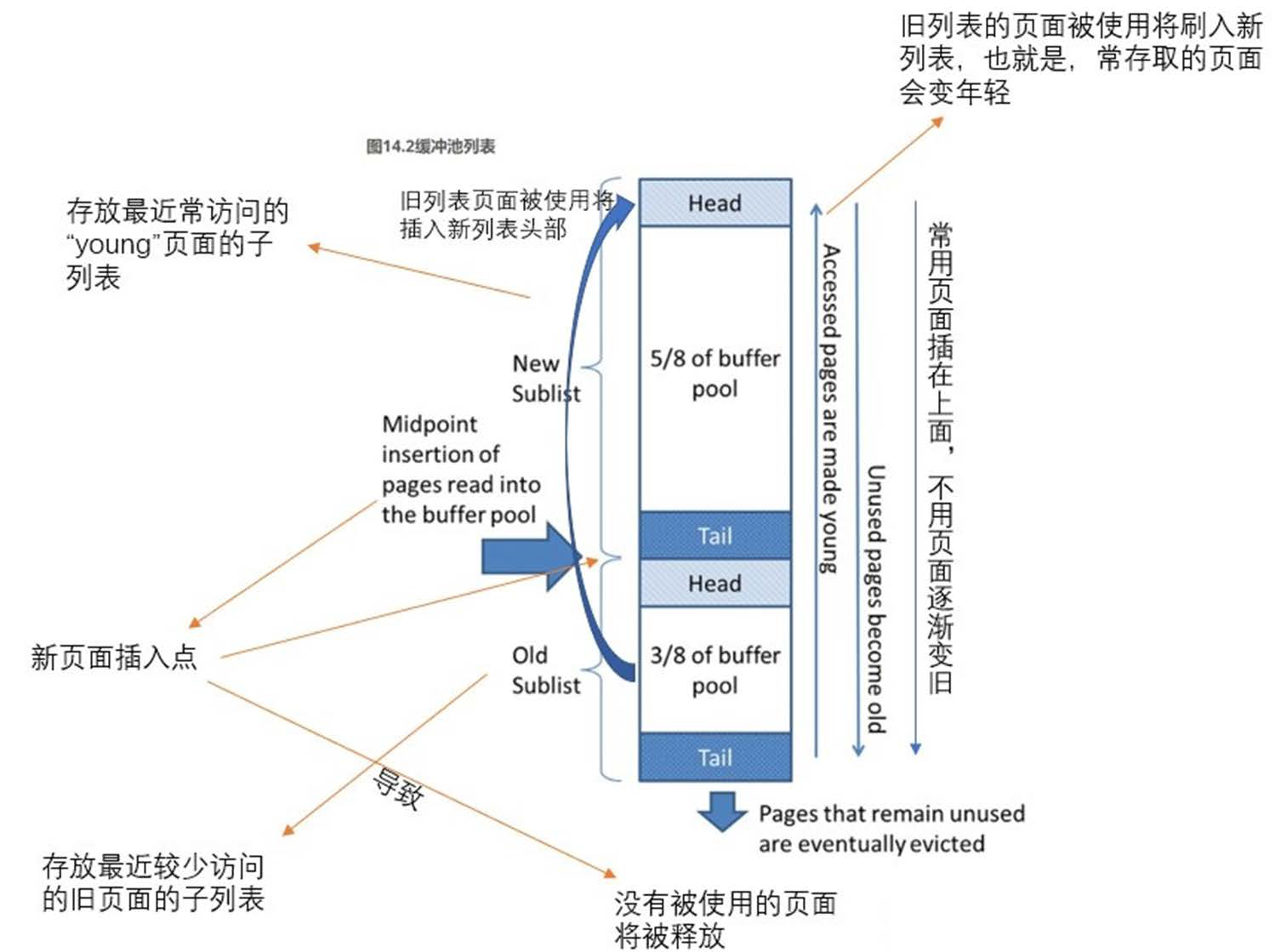
- 如果页面是被 SQL 语句读取的,它会马上访问旧列表并将其推入新列表头部
- 如果是预读读取的页面,则不会发生对旧列表的访问
MySQL double write
- 操作系统往磁盘写,最基本的单位是一个扇区
- 数据库页面可能由多个扇区构成,怎么保证操作系统把这些山区都写入磁盘?
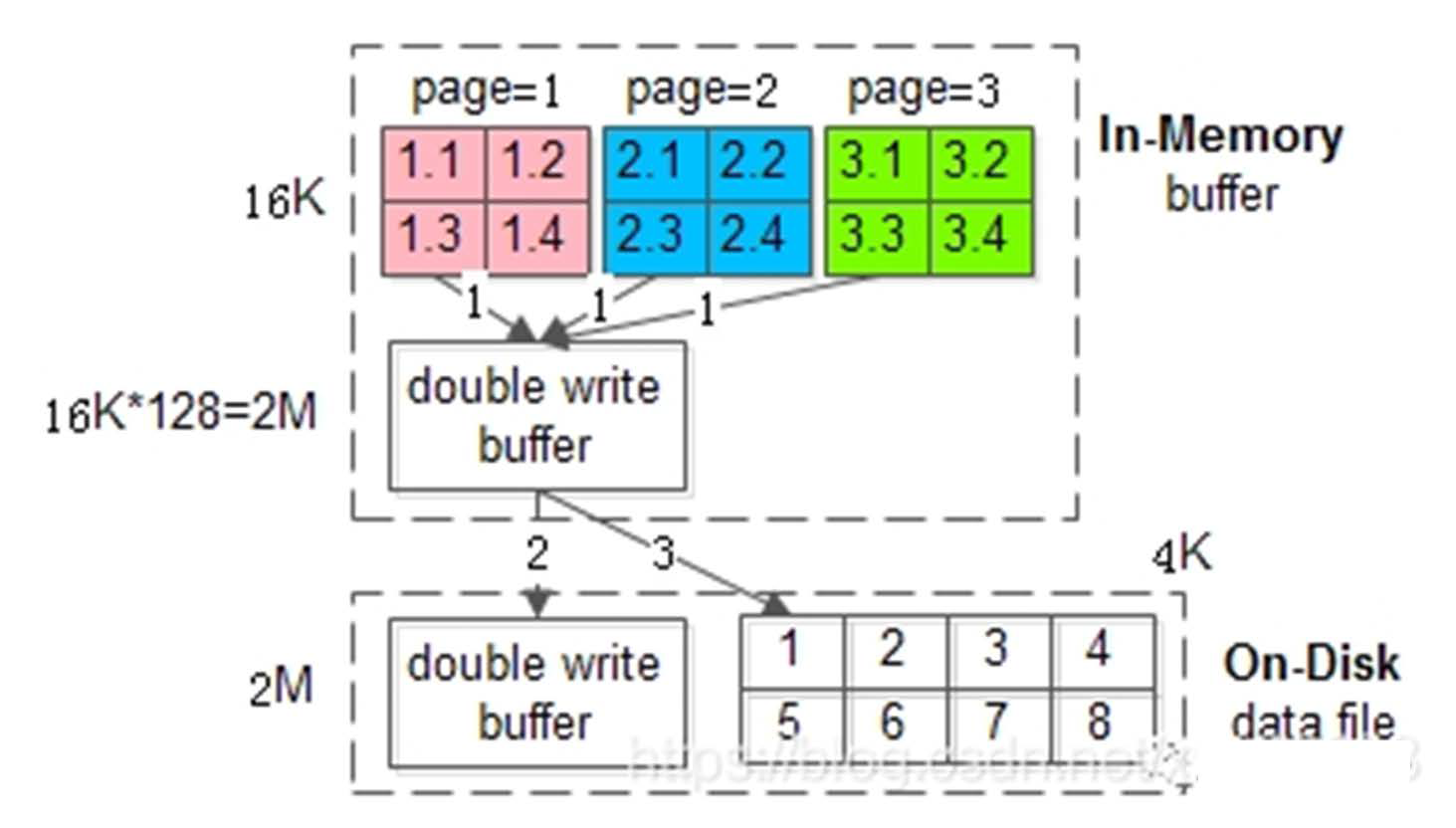
- 步骤
- 1:页数据先 memcopy 到 DWB 内存
- 2:DWB 内存先刷到 DWB 磁盘
- 3:DWB 内存再刷到数据磁盘
- 实现全或无
- 一旦开始写磁盘,说明这些数据都已经写入到 DWB 中
- 如果写到 DWB 的过程中挂了的话,就全不写
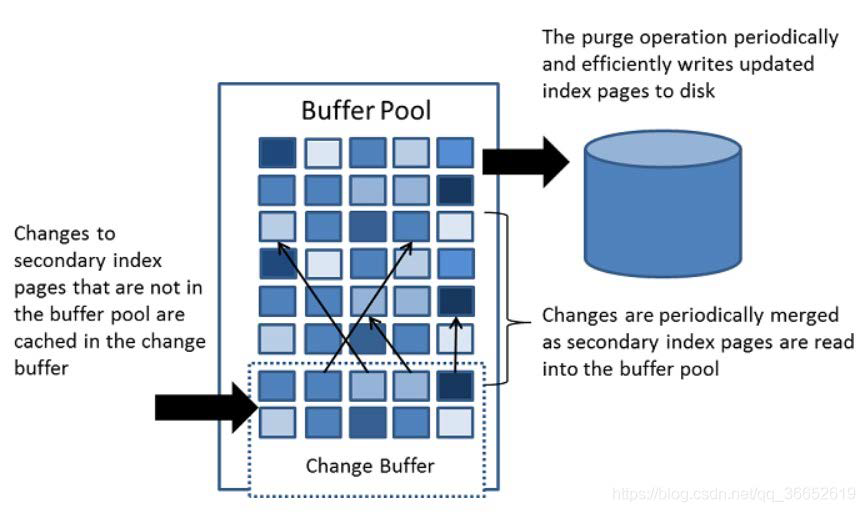
MySQL change buffer
- 如何把对二级索引的随机写改成批量写?
- 非聚簇索引在物理上是不连续的
- 聚簇索引在物理上是连续的
- 这样对索引的连续写可能是对物理页的非连续写
- 先把对二级索引的更新缓存起来,凑齐到一部分之后一起更新(减少随机写)
- 无 change buffer
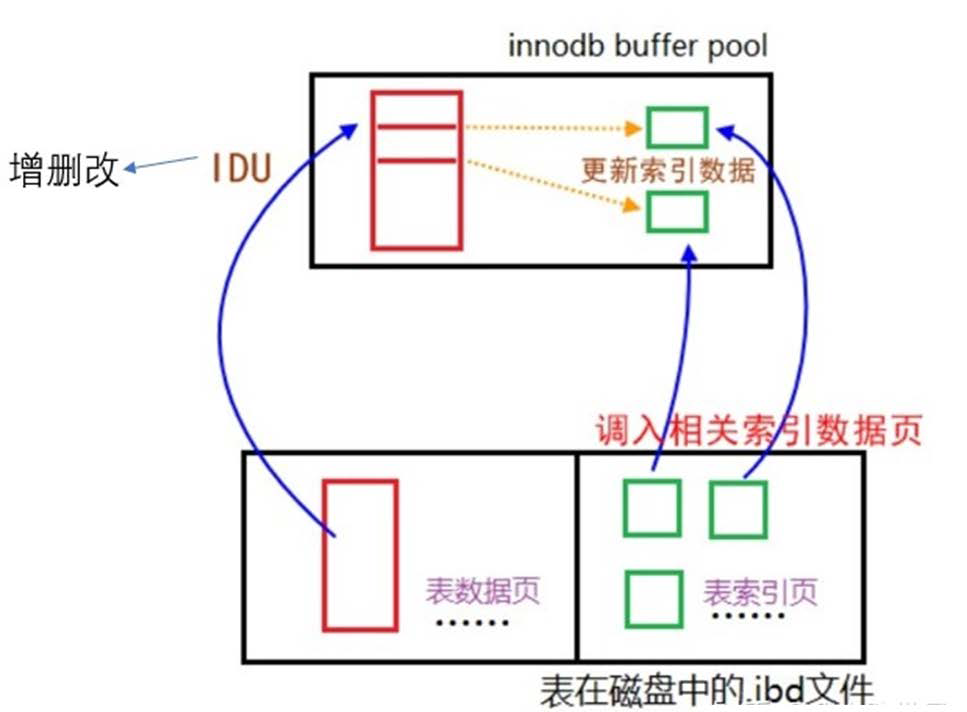
- 有 change buffer
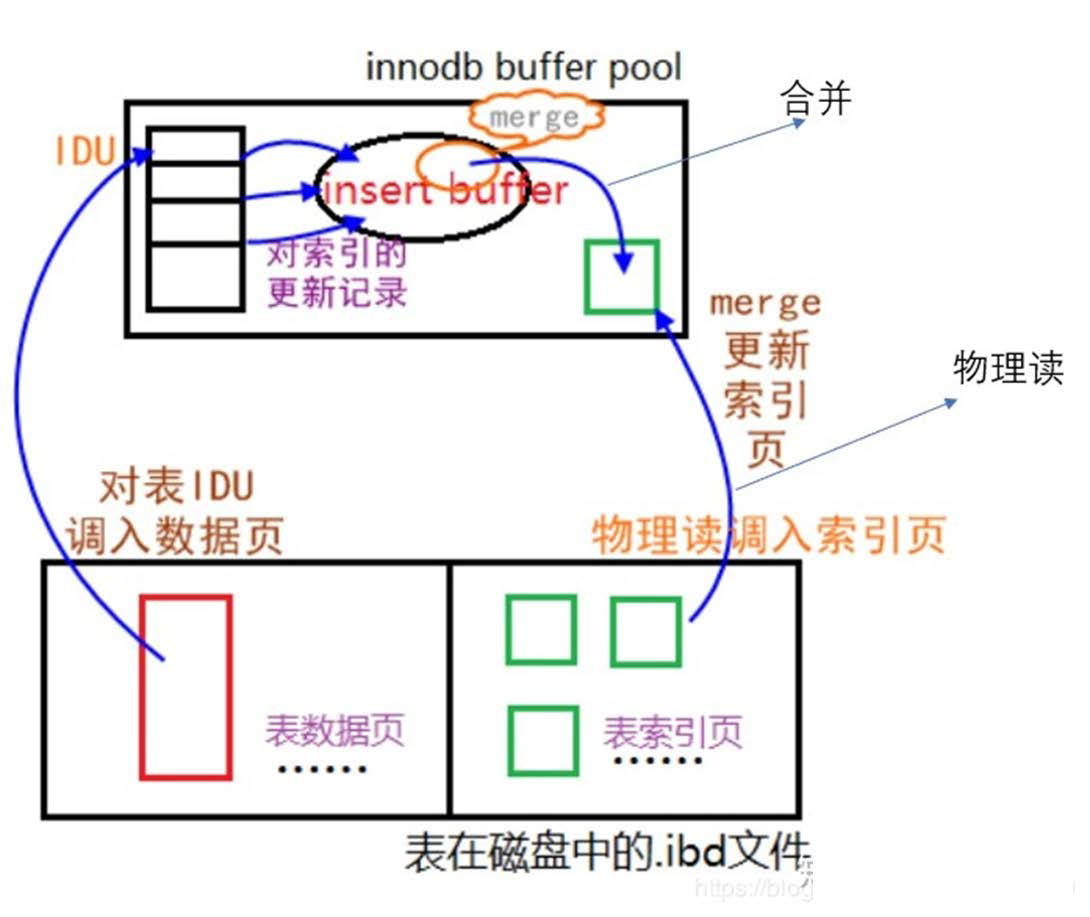
- 具体实现如下图
- 读盘先在 change buffer 中找,找到则直接返回
- 系统在空闲时运行清除(purge)操作,将更新的索引页写入磁盘
多大缓冲区是合适的
- 缓冲区过大占用过多内存
- 保持数据在内存,减少磁盘I/O,增加内存代价
- 若一个页面每秒被访问 n 次,将它驻留在内存节省 \(\mathrm{n*\dfrac{price\_per\_disk\_drive}{accesses\_per\_second\_per\_disk}}\)
- 保持一个页面在内存的代价 \(\mathrm{\dfrac{price\_per\_MB\_of\_memory}{pages\_per\_MB\_of\_memory}}\)
- 对比两个代价得出结果
- 5-minute rule
- 如果一个被随机访问的页面的使用频率超过每 5 分钟一次,那么它应该被驻留在内存
- 1-minute rule
- 如果被顺序访问的页面的使用频率超过每 1 分钟一次,那么它应该被驻留在内存
- 如果内存太小,不能满足 5 分钟规则的话,说明应该扩充内存
存储结构
SQL Server 数据库存储结构
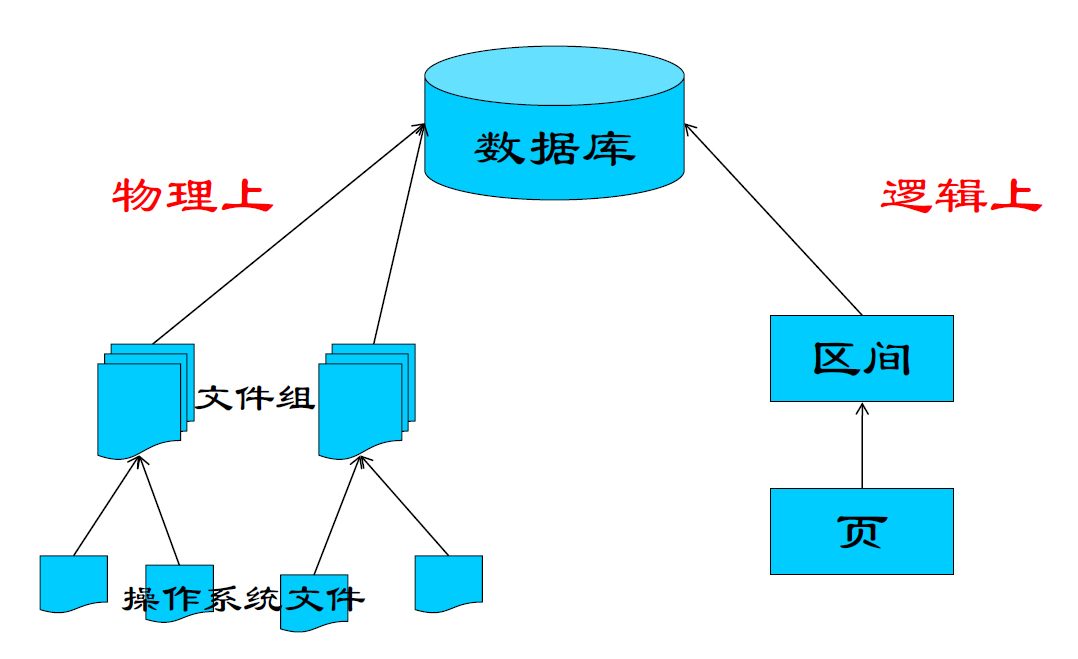
页面与区间
- 数据文件被划分成 8k 的页面
- 每个文件中的页面号都以 0 开始(文件内的逻辑页面号)
- 页面号的形式为 (file#:page#),如(3:124)
- 8 个连续页面构成一个区间 ——
64k
- 总是从能被 8 整除的页面开始
- 存储分配总是按照区间为单位进行
- 对象每次增长1个区间
- I/O 可以按页面(8KB)或者区间(64KB)来进行
存储结构的几个基本问题
- 如何为对象分配空间?
- GAM、SGAM、PFS
- 如何找到对象占据的空间?
- IAM
- 行在页内是如何存储的?
GAM
- Global Allocation Map
- 全局分配位图
- 记录文件当中哪些区间已经被分配的页面
- 可以看成是一个8000个字节的位图
- 每个位代表一个区间
- 位 0 代表区间 0,位 1 代表区间 8,位 2 代表区间 16
- 0:被使用;1:未被使用
- 一个页面 8k 字节 = 64k 位
- 能够表达 64k 个区间(512k 个页面)
- 64k x 64k = 4G
- 一个 GAM 表达不下就使用多个 GAM
- 第一个 GAM 位于文件的第三个页面(page2)
- 下一个GAM位于第 511232 个页面
- 具体计算方式涉及到具体放置内存的方式
- GAM 总是位于它所控制范围的第一个页面
SGAM
- 共享全局分配位图
- 结构与 GAM 相同,用于表示文件中哪些区间被作为共享区间分配并且仍然有空闲区间可供分配
- 每一位代表一个区间
- 位 0 代表区间 0,位 1 代表区间 8,位 2 代表区间 16
- 0:区间要么不是共享区间,要么共享区间没有空闲页
- 1:区间是共享区间,并且至少有一个空闲页
- 表达 4 GB 数据空间,与对应的 GAM 表达范围相同
- 如果文件大于 4GB,可以增加新的 SGAM 页
- 第一个SGAM位于文件的第四个页面(page3)
- 下一个 SGAM 位于第 511233 个页面
GAM 与 SGAM
| Current Use of Extent | GAM Bit Setting | SGAM Bit Setting |
|---|---|---|
| Free, not in use | 1 | 0 |
| Uniform extent, or full mixed extent | 0 | 0 |
| Mixed extent with free pages | 0 | 1 |
- 如果需要一个新的、完全没有使用的区间,可以从 GAM 中寻找位为 1 的区间
- 如果需要一个有空闲页的混合区间,可以寻找在 GAM 中位为 0、在SGAM中位为 1 的区间
PFS
- 空闲页空间
- 记录文件中每个页面是否已经被分配以及有多少空闲空间
- 每一个页面在 PFS 页中有一个字节对应
- 每个PFS覆盖8088个连续页面(64MB)
- 页面充满度:0,1-50%,51-80%,81-95%,96-100%
- 第一个 PFS 位于文件的第二个页面(page1),以后每 8088 都是一个 PSF 页
IAM
- 索引分配位图
- 如何发现一个特定对象的区间或页面?
- 每个表 / 索引都至少有一个IAM,记录该对象拥有哪些区间
- IAM 覆盖的范围与 GAM 相同
- 如果位为 1,说明该区间被分配给该对象;如果位为 0,说明该区间未被分配给该对象
- 如 11000000,说明第一、二个区间被分配给该对象
- 一个对象每占据文件的 4G 空间,就需要一个 IAM,对象的所有 IAM 构成一个双向链表
基本页结构
- 所有页面包括页面头、页面体、页面槽
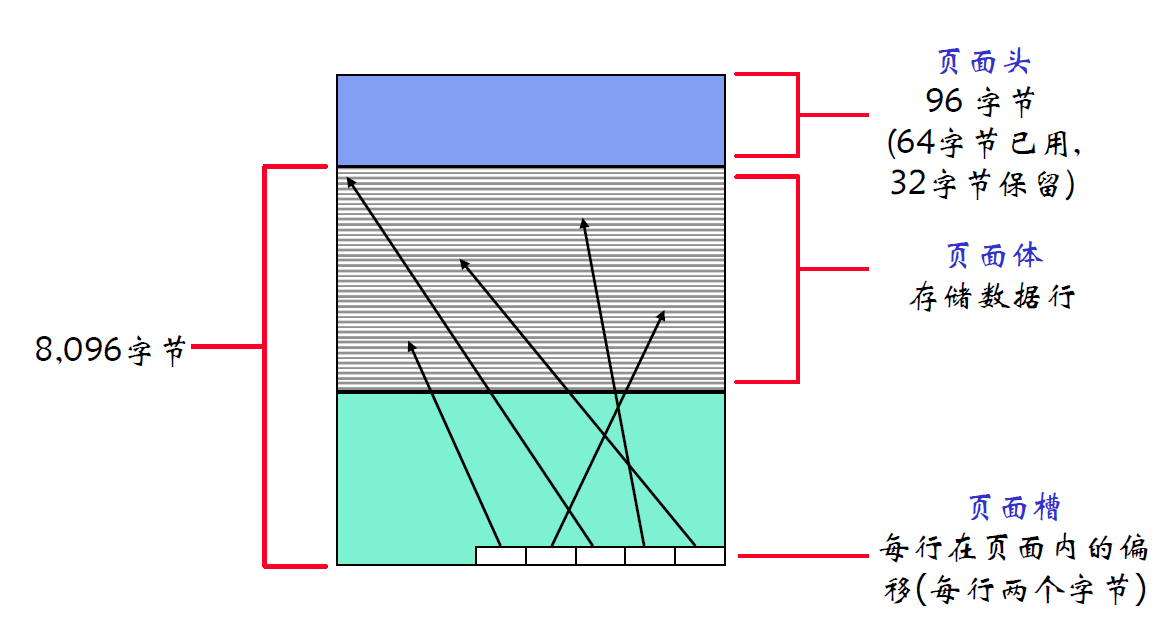
- 页面槽记录每行在页面内的偏移,位于页面最后面
- 方便存储:数据是从空闲的地方往后加,页面槽是从后往前加
页头字段含义
| Field | What It Contains |
|---|---|
| pageID | 数据库中该页的文件号和页号 |
| nextPage | 在页链中该页的下一页的文件号和页号 |
| prevPage | 在页链中该页的上一页的文件号和页号 |
| objID | 该页所属对象的ID |
| lsn | 用于修改该页的日志序列号(LSN) |
| slotCnt | 该页上槽的总数 |
| level | 该页在索引中的级别(对于叶级别该值为0) |
| indexId | 该页的索引ID(对于数据页该值为0) |
| freeData | 该页上第一个空闲空间的字节偏移量 |
| pminlen | 行的固定长部分的字节数 |
| freeCnt | 该页上空闲字节的数目 |
| reservedCnt | 由所有事务保留的字节数 |
| xactreserved | 由最近启动的事务保留的字节数 |
| tornBits | 每个扇区1位,用于监测使该页分裂的写 |
| flagBits | 一个两字节的位图,包含有关该页的额外信息 |
数据行结构
- 如何处理定长数据和变长数据
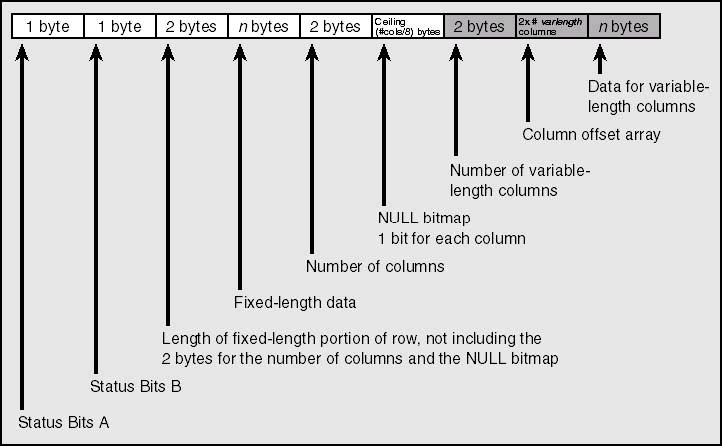
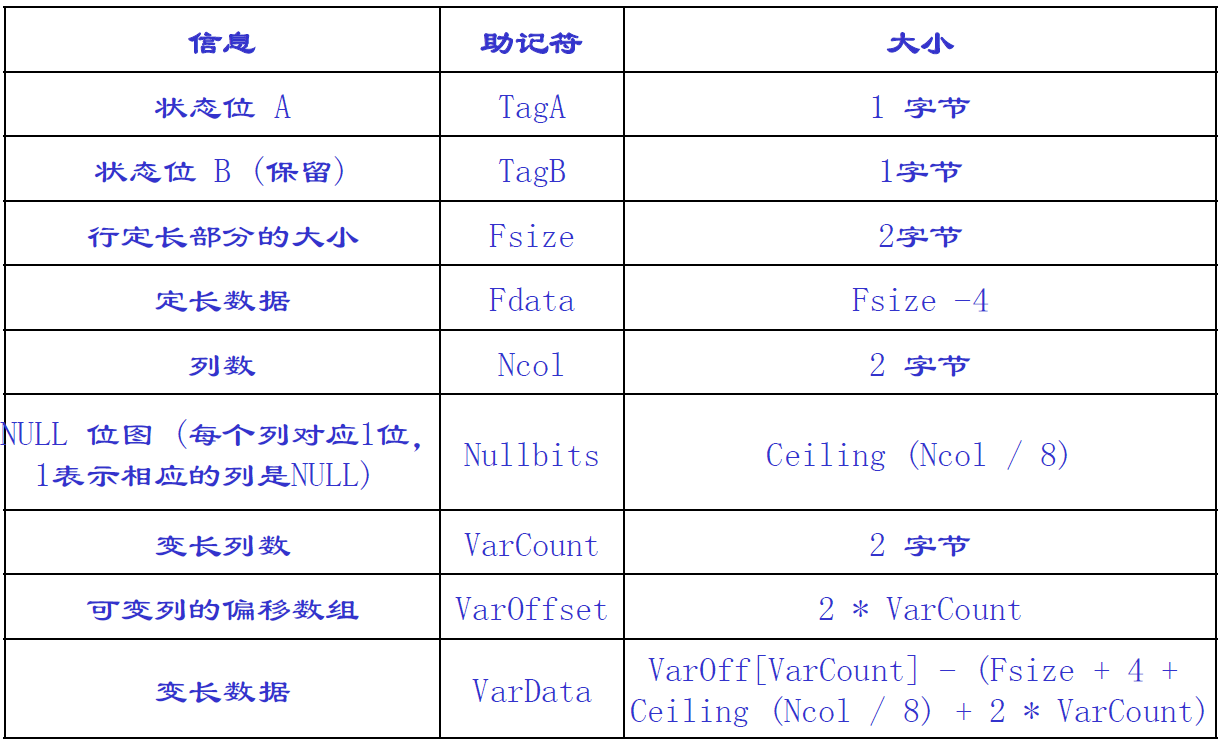
- 观察内部存储结构
1 | select * from sys.partitions |
MySQL 数据库存储结构
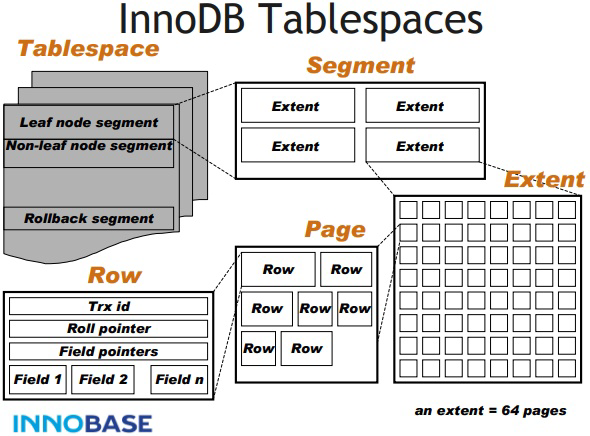
- Segment:数据段,索引段,回滚段
- Page:数据页、回滚页、系统页、事务页、插入缓冲位图页
文件结构
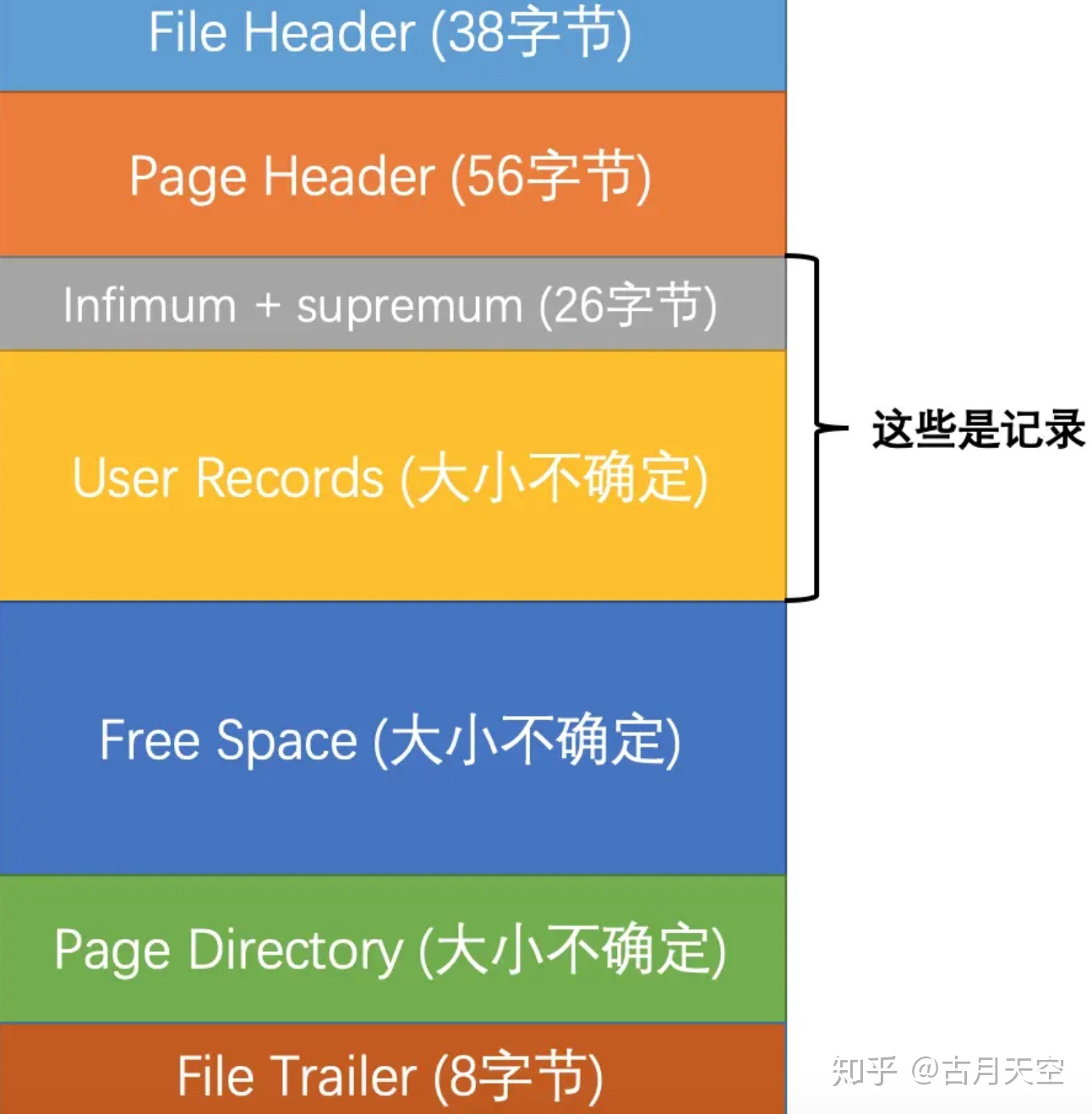
- 校验页的完整性
- 本页有多少条记录,第一条记录的地址,页目录中有多少 slot,最后插入记录的位置
页结构
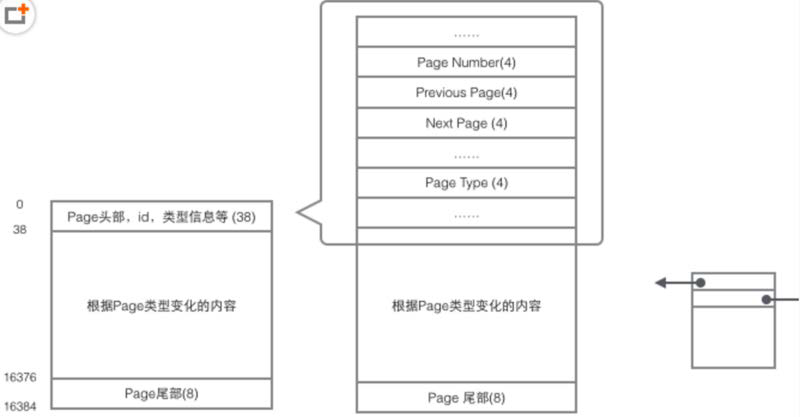
行结构
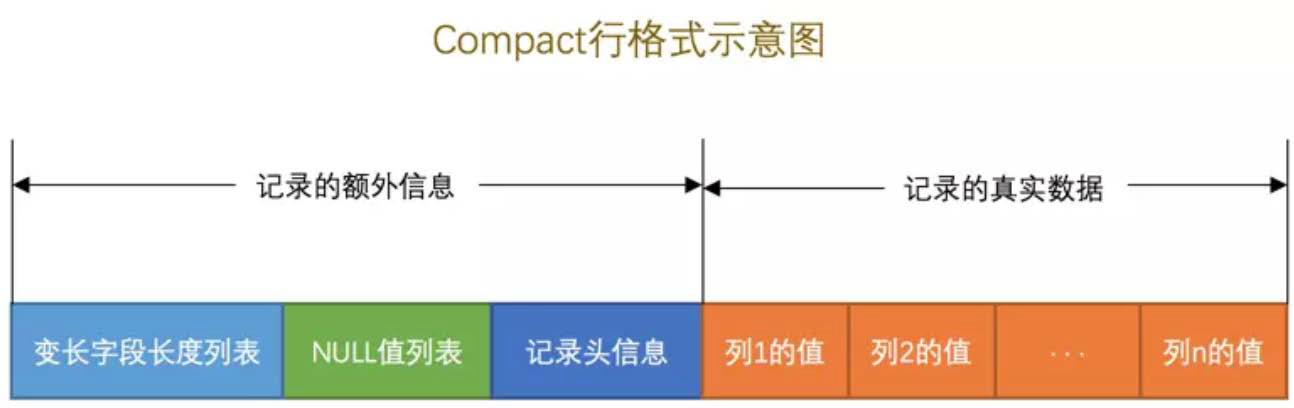
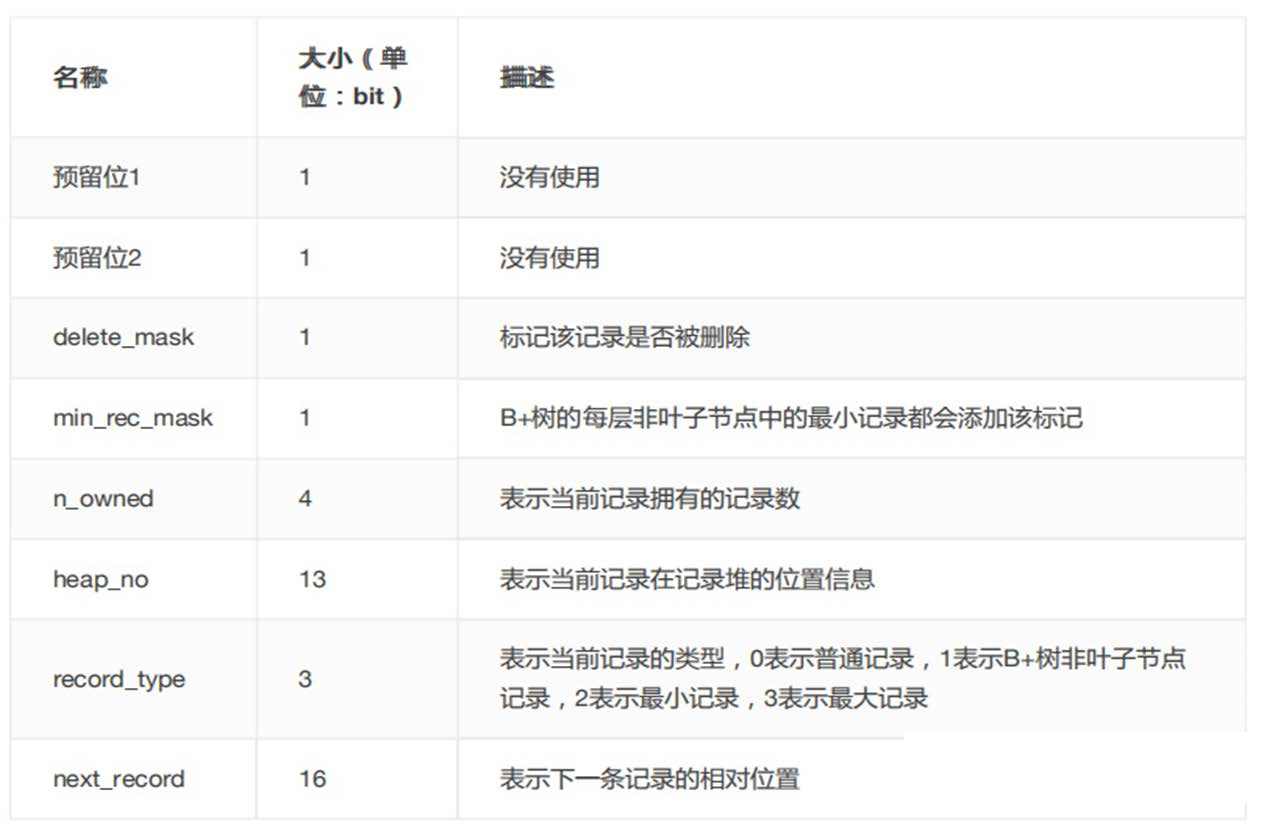
- 删除记录不是直接删除,而是做一个标记(delete_mask)
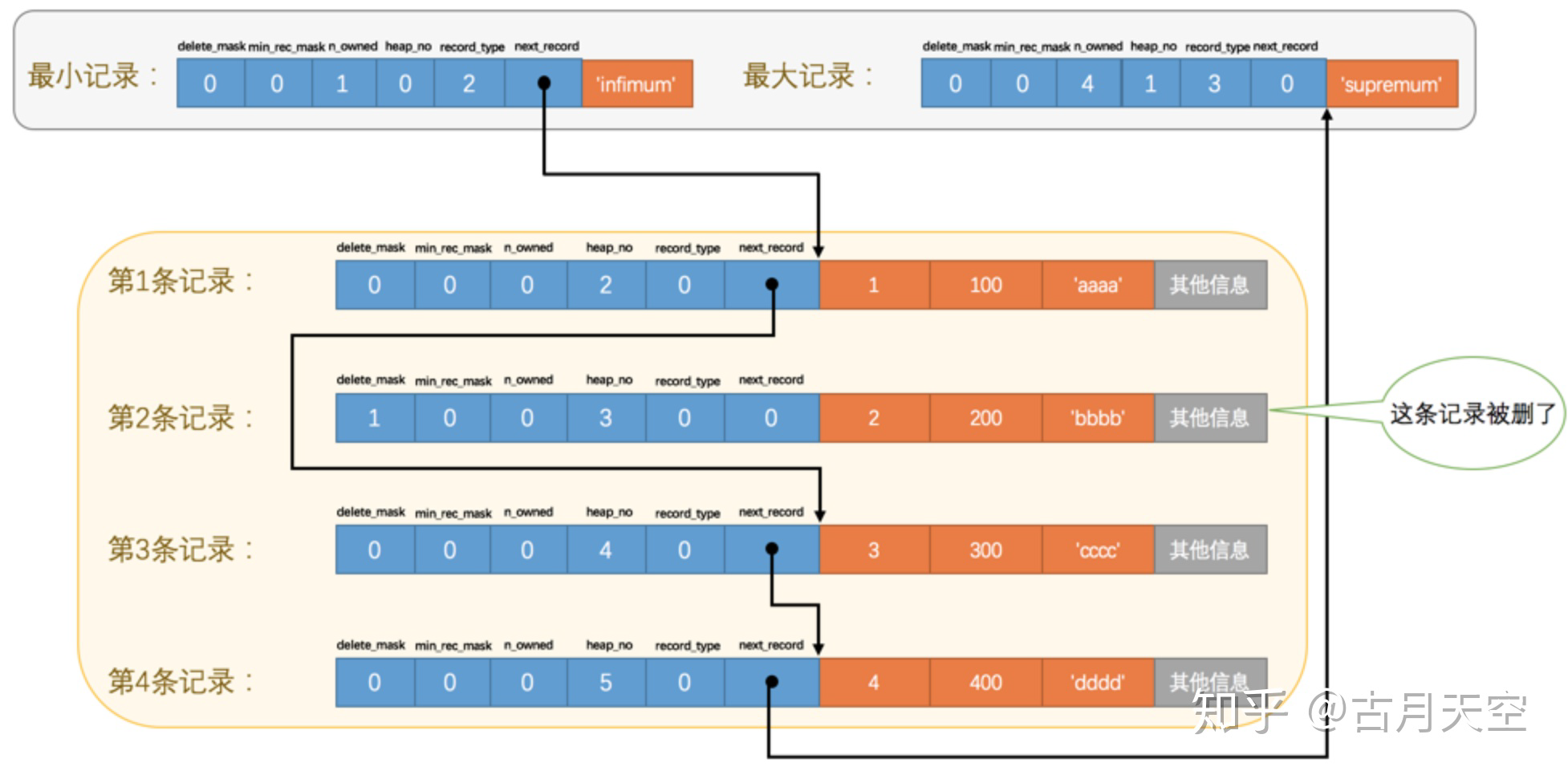
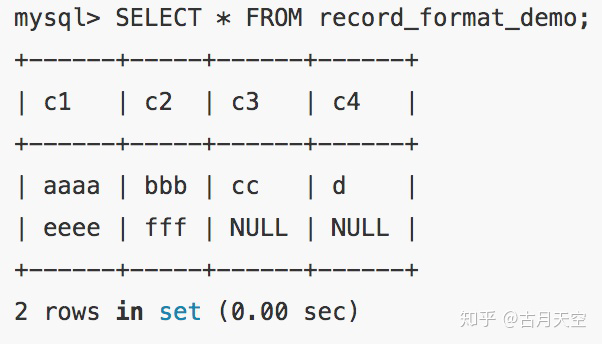
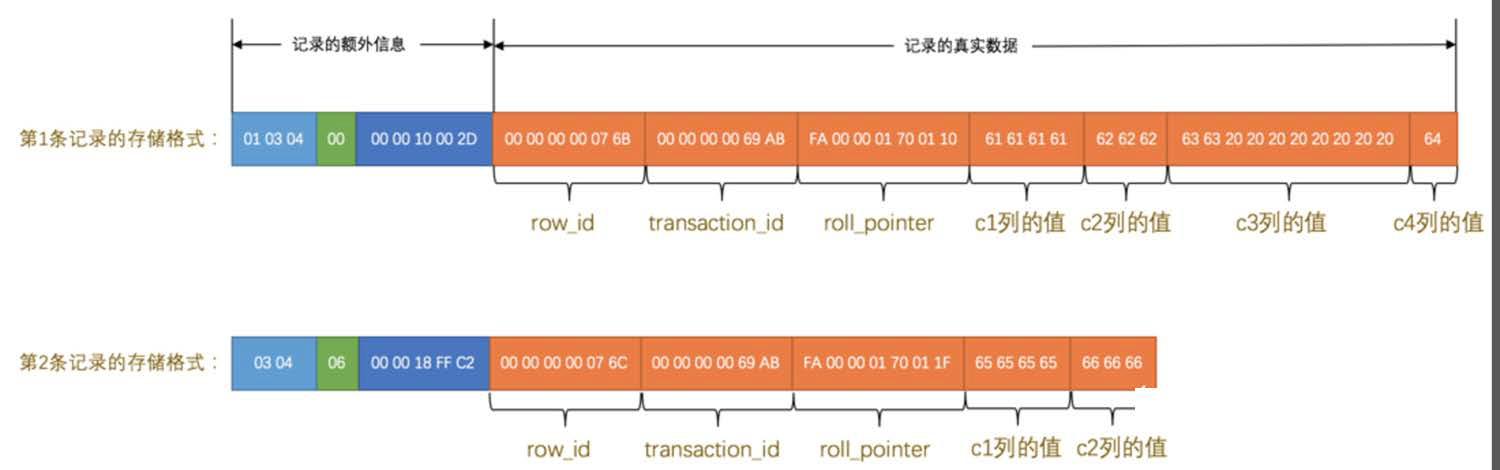
行结构示例

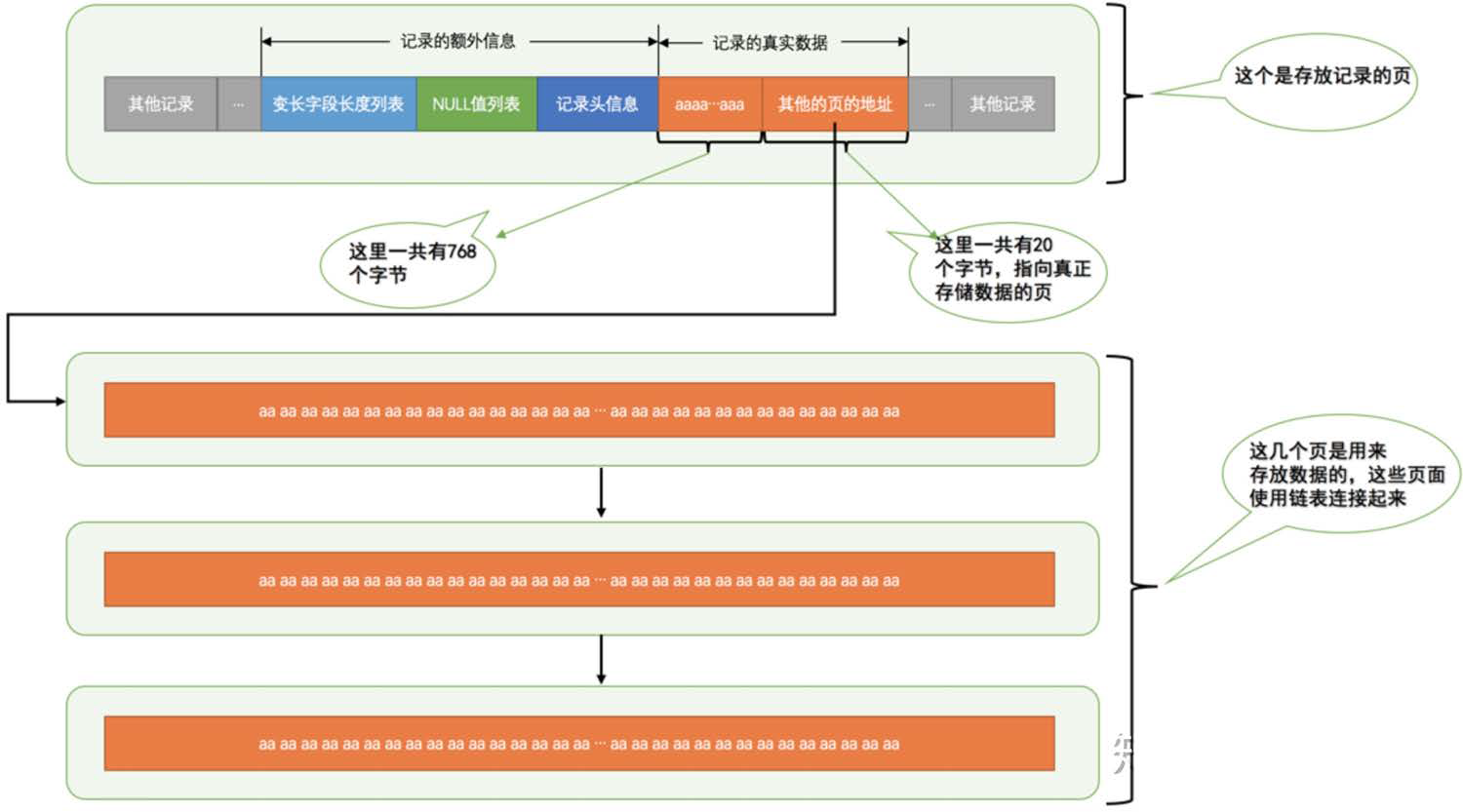
行溢出数据
- 某些行特别大
- Dynamic 行格式完全放入溢出页