数据库概论.陈立军.10.数据库存储
数据库存储
存储介质
物理存储介质
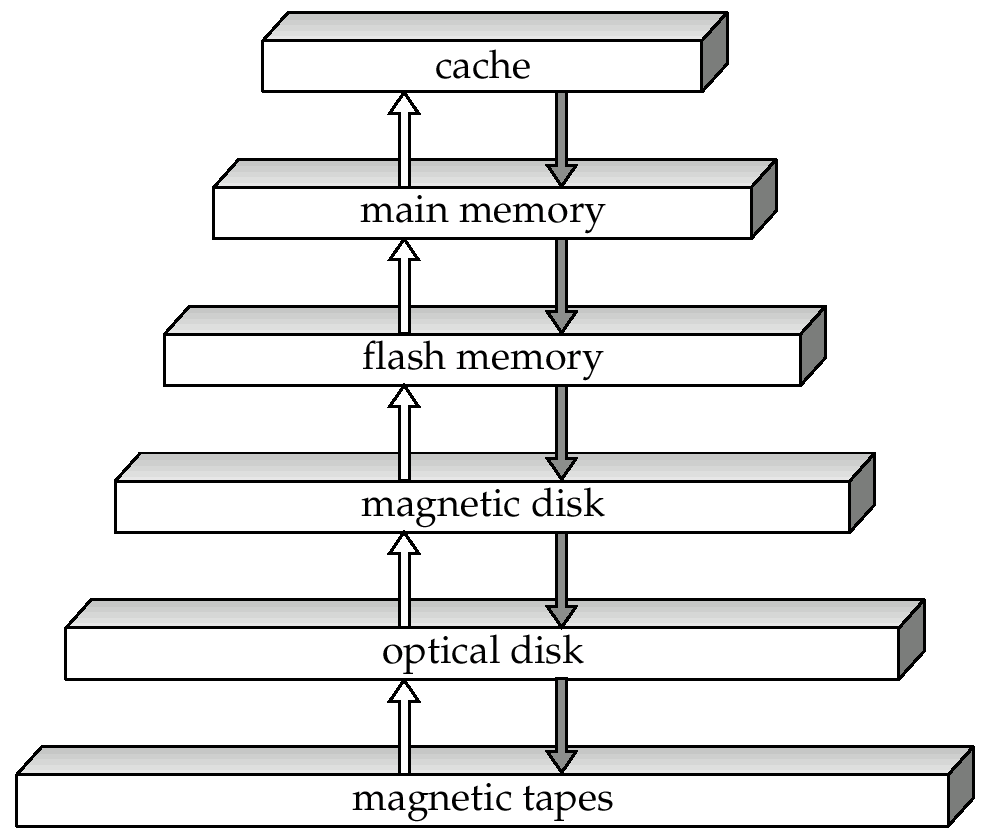
- 根据读写性能调整数据库算法
- 缓存:局部性原理
- 性能
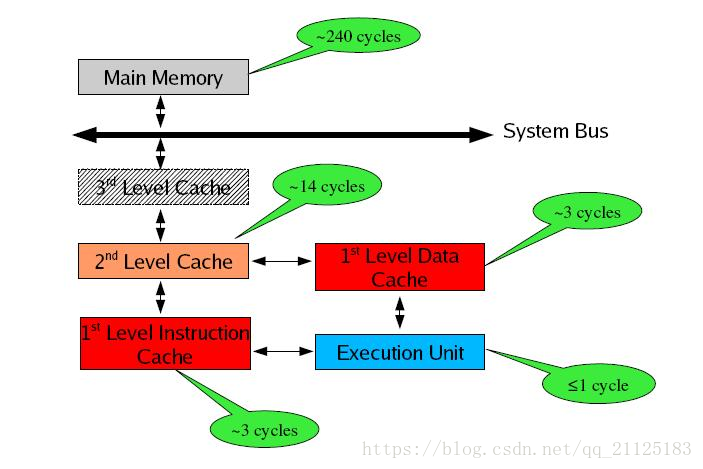
- 高速缓冲存储器(cache)
- 最快最昂贵的存储介质
- 很小,由操作系统管理
- 主存储器(main memory)
- 存放可被处理的数据的存储介质
- 易失,相对整个数据库太小
- 快闪存储器(flash memory)
- 读性能类似主存,写速度非常慢
- 电子可擦除可编程只读存储器 (Electrically Erasable Programmable Read-Only Memory)
- 磁盘存储器(Magnetic-disk storage)
- 直接读取设备,支持随机读取
- 非易失联机数据存储设备
- 访问数据时,磁盘 \(\to\) 内存
- 修改后的数据,内存 \(\to\) 磁盘
- 光学存储器(Optical storage)
- 只读(CD-ROM)、一次写多次读(WORM)、多次写(CD-RW)
- 磁带(tape)
- 顺序访问,归档存储,容量大,价格便宜
磁盘
- 磁盘物理结构
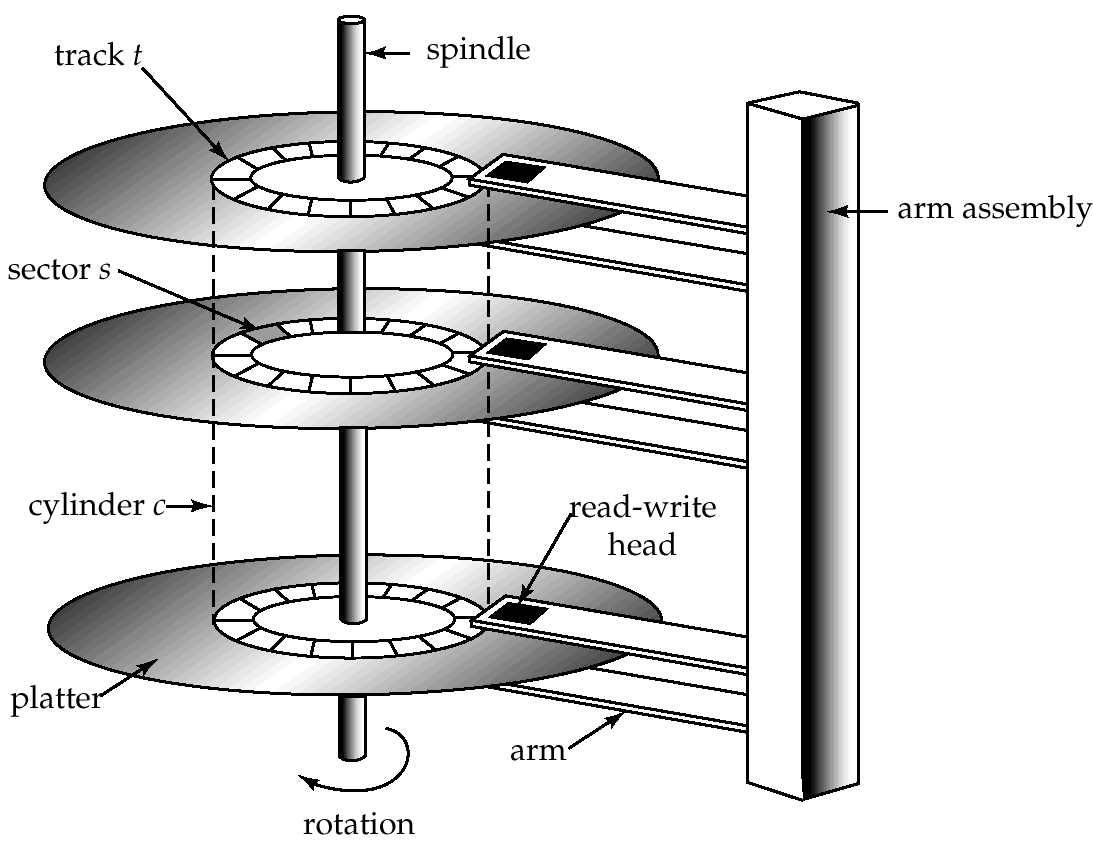
- 盘片(platter)、磁道(track)、扇区(sector)、柱面(cylinder)、磁盘臂(diskarm)
- 读写头(read-write head):反转磁性物质磁化方向
- 磁盘控制器(disk controller):
- 接受读写扇区命令,定位读写头
- 向扇区写入数据时附加校验和(checksum),读取时重新计算校验和
磁盘性能度量
- 访问时间
- 从发出读写请求到数据开始传输之间的时间
- 先移动磁盘臂,定位到正确的磁道,然后旋转磁盘,直到指定扇区出现在读写头下方
- 寻道时间(seek time)
- 磁盘臂重定位时间,取决于目标磁道和磁盘臂当前距离,2~30毫秒。平均寻道时间是最大寻道时间的1/3
- 旋转等待时间(rotational latency tiime)
- 目标扇区旋转到读写头下面的时间,每转在4~11毫秒之间。平均旋转时间是旋转一周的1/2
- 数据传输率(data-transfer rate)
- 25~100兆/秒
磁盘访问优化
- 磁盘块的大小
- 小,更多的磁盘传输次数
- 大,空间浪费
- 调度
- 块在一个柱面上,按块经过读写头的顺序访问
- 块在不同柱面上,按使磁盘臂移动距离最短的顺序访问
- 电梯算法
- 文件组织
- 按与预期数据访问方式最接近的方式组织磁盘块
- 碎片整理
- 日志磁盘
- 顺序写,消除了寻道时间
- 检查点
- 顺序写:把物理上相邻的页面聚集大一起,一次性写入磁盘
磁盘的顺序和随机访问对比
- 7200rpm 的希捷 SATA 硬盘顺序读写基本都能达到 300MB/s
- 随机读写 100IOPS,假设每次 IO 大小为 1KB,则随机读写数据带宽为 100KB/s
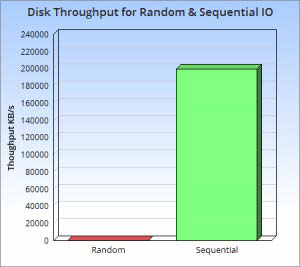
- 不同介质的顺序和随机访问对比
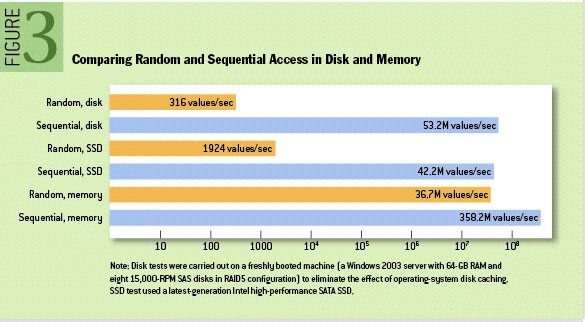
- 尽可能顺序读!!!
发掘磁盘顺序读的性能
预读
- prefetch、read-ahead
- 将临近的数据读进来
- 局部性原理
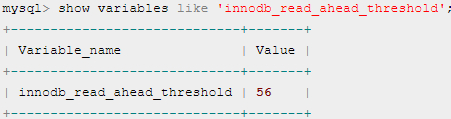
- MySQL线性预读(linear read-ahead):是否将下一个 extent 预读到
buffer pool 中
- 如果一个 extent 中被顺序读取的 page 超过或者等于该参数变量时,Innodb 将会异步将下一个 extent 读取到 bufferpool 中
LSM
- The Log-Structured Merge-Tree(LSM-Tree)
- 假设要写入10000 个 随机 key
- 最快的磁盘写入方式是批量顺序写,但这样带来的问题是每次查询都需要遍历整个数据
- 如果想获得高磁盘读性能,就需要对数据像 B 树那样进行排序,但其写性能又太差
- 如何权衡?\(\to\) LSM 树
- 将 \(N\)
个数据划分成多个小的有序结构,每 \(m\)
个数据在内存里排序一次,这样就获得 \(\dfrac{N}{m}\)
个有序结构;查询时从最新的一个有序结构里做二分查找,如果没找到就继续查找下一个有序结构
- 读取的时间复杂度是 \(\dfrac{N}{m}\log_{2}{M}\)
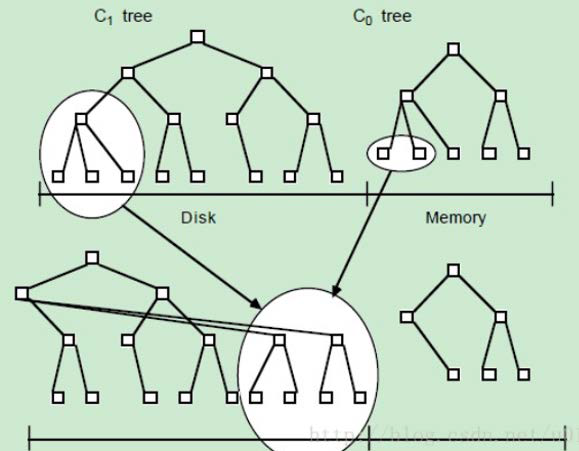
- LSM 把一棵大树拆分成 N
棵小树,随着小树越来越大,内存中的小树会 flush
到磁盘中,磁盘中的树定期做 merge
操作,合并成一棵大树,以优化读性能
- 内存中满了之后整体刷到磁盘上,这样是顺序写,而不是 B 树或者 B+ 树的随机写
- 将对数据的修改增量保持在内存中,达到指定的大小限制后再批量写入磁盘,所以写入性能大大提升
- 需要合并磁盘中历史数据和内存中最近修改操作
- 读取时需要先看是否命中内存,否则需要访问较多的磁盘文件
- 在合并过程中,并不会像 B+ 树一样,在原数据的位置上修改,而是直接插入新的数据,从而避免了随机写
- 当磁盘中的小树合并成一个大树的时候,可以重新排好顺序,使得block连续,优化读性能
- LSM-Tree 属于传输型,因为它会使用日志文件和一个内存存储结构把随机写操作转化为顺序写
- 对于删除操作,只需在 memtable 中插入一条数据当作标志,如 delKey:1933
- 当读操作读到 memtable 中这个标志时,就会知道这个 key 已被删除
- 把树刷到磁盘的时候,修改为 immutable,不允许修改
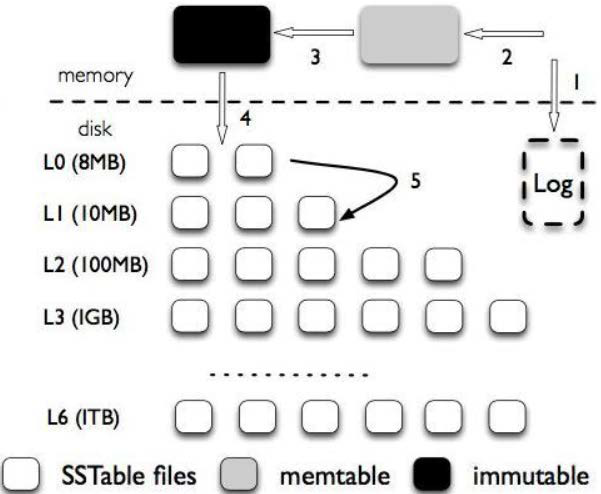
- 怎么保证读到的数据是最新的?
- 如果一个数据多次更新,可能会存在其的多个副本
- 我们读的顺序是由新到旧的读,因此读到的总是最新的
- 小树合并成大树的时候可以把多个副本处理掉
bloom filter
- 对于不存在的数据,如何避免遍历所有集合?
- 如果使用 LSM 树的话,需要遍历所有树
- 引入布隆过滤器,当它显示某 SSTable 中没有目标数据时,就跳过
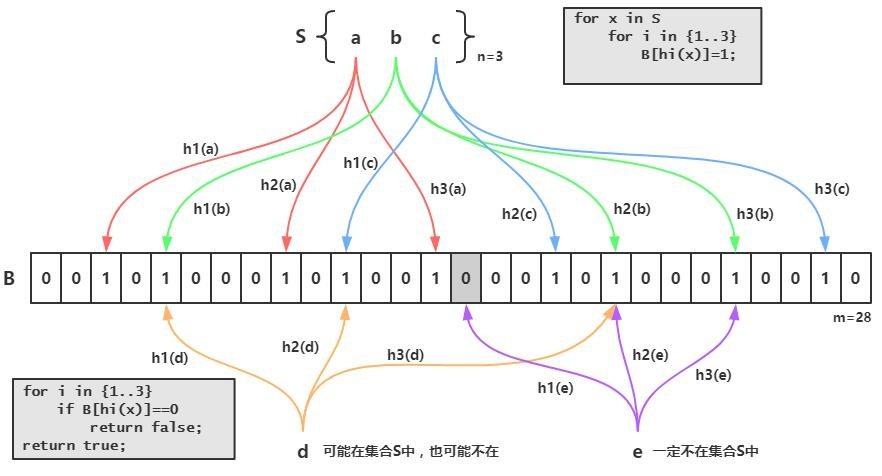
- 使用多个哈希函数,都存在才表明这个元素存在
- bloom filter
- 如果判定一个元素没有出现过,那么这个元素一定没有出现过
- 如果判定一个元素出现过,那么这个元素可能出现过也可能没出现过
RAID
- Redundant Arrays of Inexpensive Disks
- 是一种利用大量廉价磁盘进行磁盘组织的技术
- 好处
- 价格:大量廉价的磁盘比少量昂贵的大磁盘合算得多
- 性能:大量磁盘可以提高数据的并行存取
- 可靠性:冗余数据可以存放在多个磁盘上,因此一个磁盘的故障不会导致数据丢失
- 过去 RAID 是大而昂贵的磁盘的替代方法,今天使用 RAID
是因为它的高可靠性和高数据传输率
- Redundant Arrays of Independent Disks
不同方式
通过冗余提高可靠性
- N 个磁盘组成的集合中某个磁盘发生故障的概率比特定的单个磁盘发生故障的概率高很多
- 假定单个磁盘的 MTTF 是100,000小时(约为11年),则由 100 个磁盘组成的阵列的MTTF是1000小时(约为41天)
- 冗余(Redundancy):存储额外的信息,以便当磁盘故障时能从中重建
镜像冗余
- 一个逻辑磁盘由两个物理磁盘组成
- 写操作在每个磁盘上执行
- 如果其中一个发生故障,数据可以从另一个磁盘读出
- 只有第一个磁盘的故障尚未恢复,第二个磁盘也发生故障,这时才会发生数据丢失
- 假定一个磁盘的MTTF是 \(10^5\) 小时,修复时间是 \(10\) 小时,则镜像磁盘的MTTF是\((10^5)^2/(2*10)=500*10^6\) 小时,约为 \(57000\) 年
校验码冗余
- 内存中每个字节都有一个奇偶校验位与之相连,它记录该字节中为 1 的比特位的总数是偶数(=0)还是奇数(=1),如果字节中有一位被破坏,则字节的 ECC 与存储的 ECC 就不会相匹配
- 通过 ECC 可以检测到所有的 1位 错误
通过拆分提高并行
- 将数据拆分到多个磁盘上以提高传输率
- 通过并行提高性能的两种途径
- 负载平衡多个小的存取操作(即页面存取),提高以提高这种存取操作的吞吐量
- 并行执行大的存取操作,以减少大的存取操作的响应时间
两种不同的拆分方式
- 比特级拆分(Bit-level striping)
- 将每个字节按比特分开,存储到多个磁盘上
- 一个由 8 个磁盘组成的阵列,将每个字节的第 i 个比特位写到第 i
个磁盘上
- 其存取速度是单个磁盘的 8 倍
- 对于由 4 个磁盘组成的阵列,将每个字节的第 i 个比特位和第 i+4 个比特位写到第i个磁盘上
- 块级拆分(Block-level striping)
- 对于由 n 个磁盘构成的阵列,文件的第i块存放在第 (i mod n)+1 个磁盘上
- 比特级拆分 vs 块级拆分
- 位级拆分:响应时间(多个盘同时响应)
- 块级拆分:吞吐量(不同的读取操作读不同的块,这些块在不同磁盘上)
RAID 级别
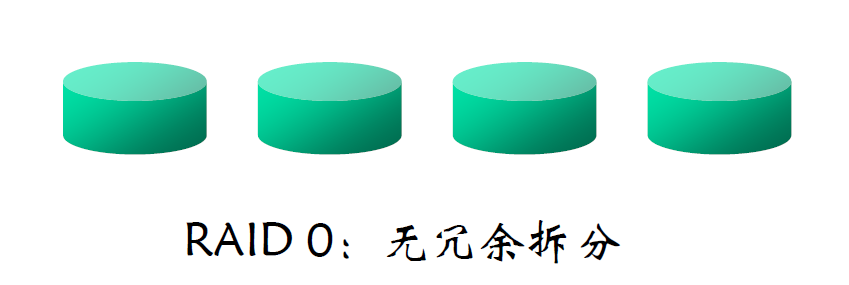
RAID 0
- 块级拆分且没有任何冗余的磁盘阵列
- 用于高性能访问且数据丢失不十分重要的应用场合
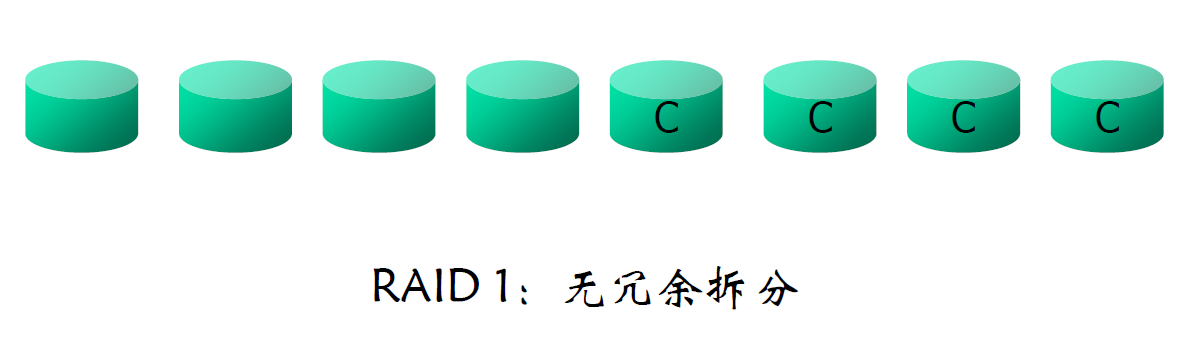
RAID 1
- 带块级拆分的磁盘镜像
- 提供最佳写性能
- 一般用于类似于数据库系统中日志文件存储的应用场合
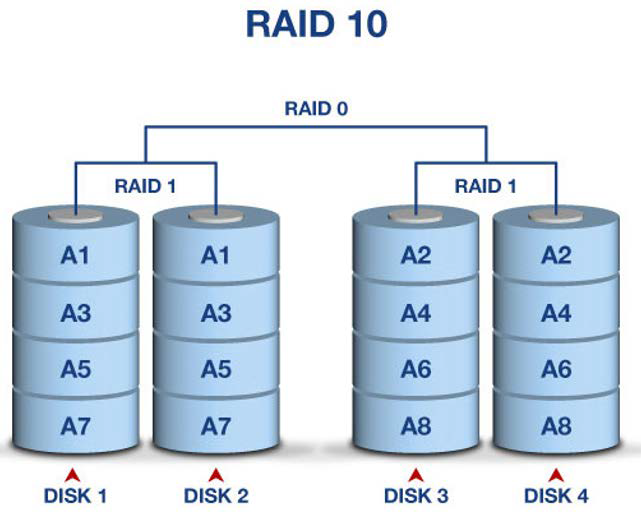
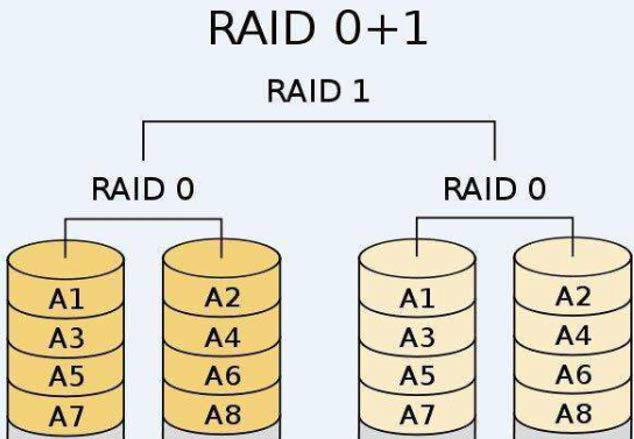
RAID 10
RAID 01
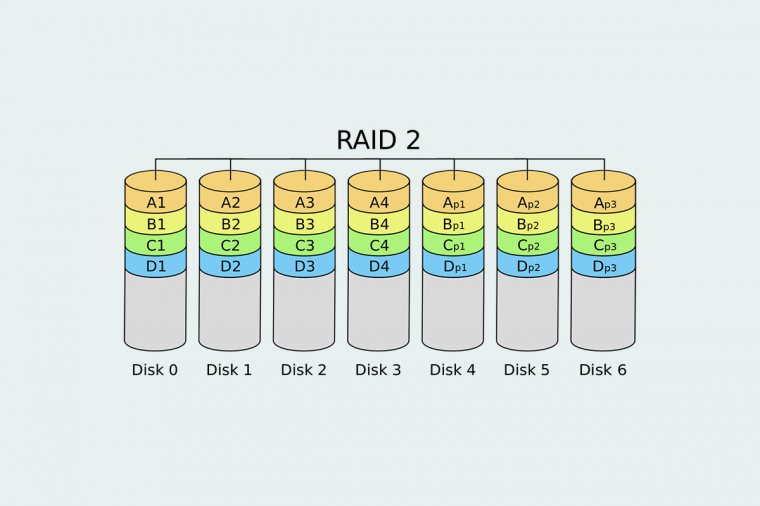
RAID 2
- 汉明码
- 允许多个磁盘出错
RAID 3
- 位交叉奇偶校验
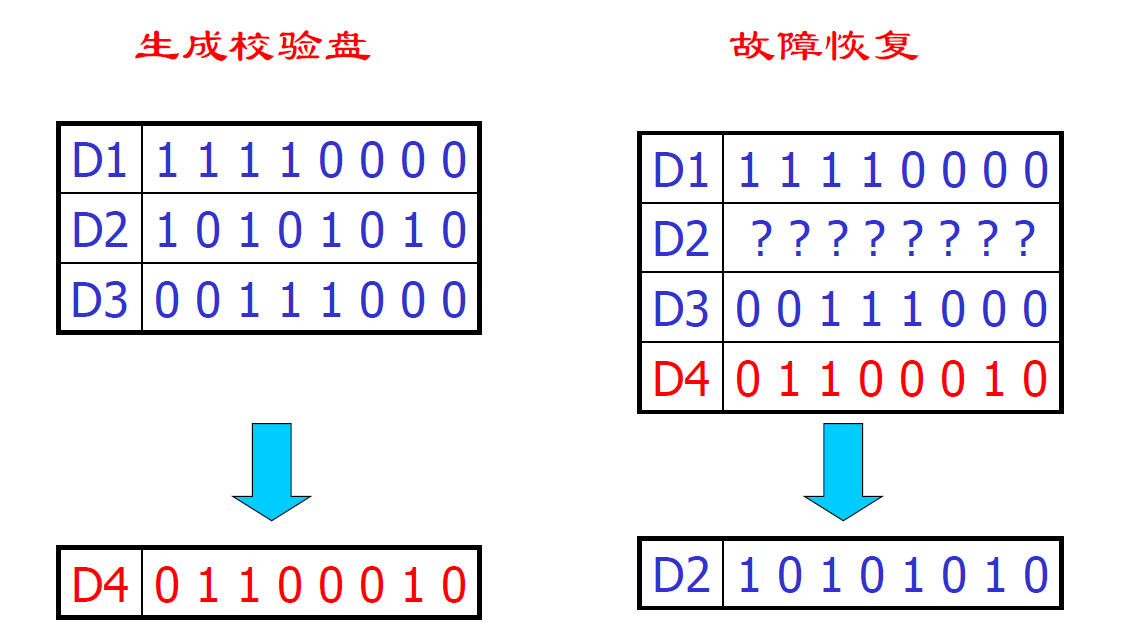
- RAID 3 写操作更新校验盘的两种方式(例如写D2,生成 D2')
- 根据 D1, D3, D2' 生成 D4:读D1,D3,写D2, D4
- 根据 D2, D2' 生成 D4:读D2,D4,写D2,D4
- 多个数据盘优势大,跟数据盘个数无关
- 数据盘多的话,产生故障的几率大了,恢复过程变得耗时
RAID 4
- 块级拆分,在一个独立的磁盘上为其他 N 个磁盘上对应的块保留一个奇偶校验块
- 读取一个块只访问一个磁盘,每个存取操作的传输率低但可以并行地执行多个读操作,从而产生较高的总 I/O 率

- 问题:负载不均衡
- 读数据盘的时候 D4(校验盘) 不工作
- 写数据盘的时候都得写 D4
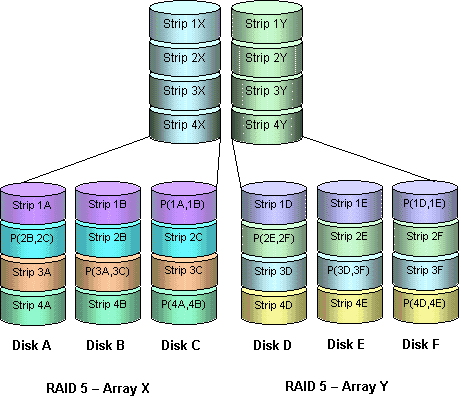
RAID 5
- 基于 RAID 4,将数据和奇偶校验位分布到所有的 N 个磁盘上
- 奇偶校验块不能和这个块对应的数据存储在同一个磁盘上
- RAID 5 所有磁盘都参与对读请求的服务,而 RAID 4 中奇偶校验磁盘不参与读操作
- RAID5 包容 RAID 4,在相同成本下提供更好的读写性能

RAID 50
RAID 6
- P+Q:Reed-Solomon 码
- 允许多个盘出错,也能恢复
总结
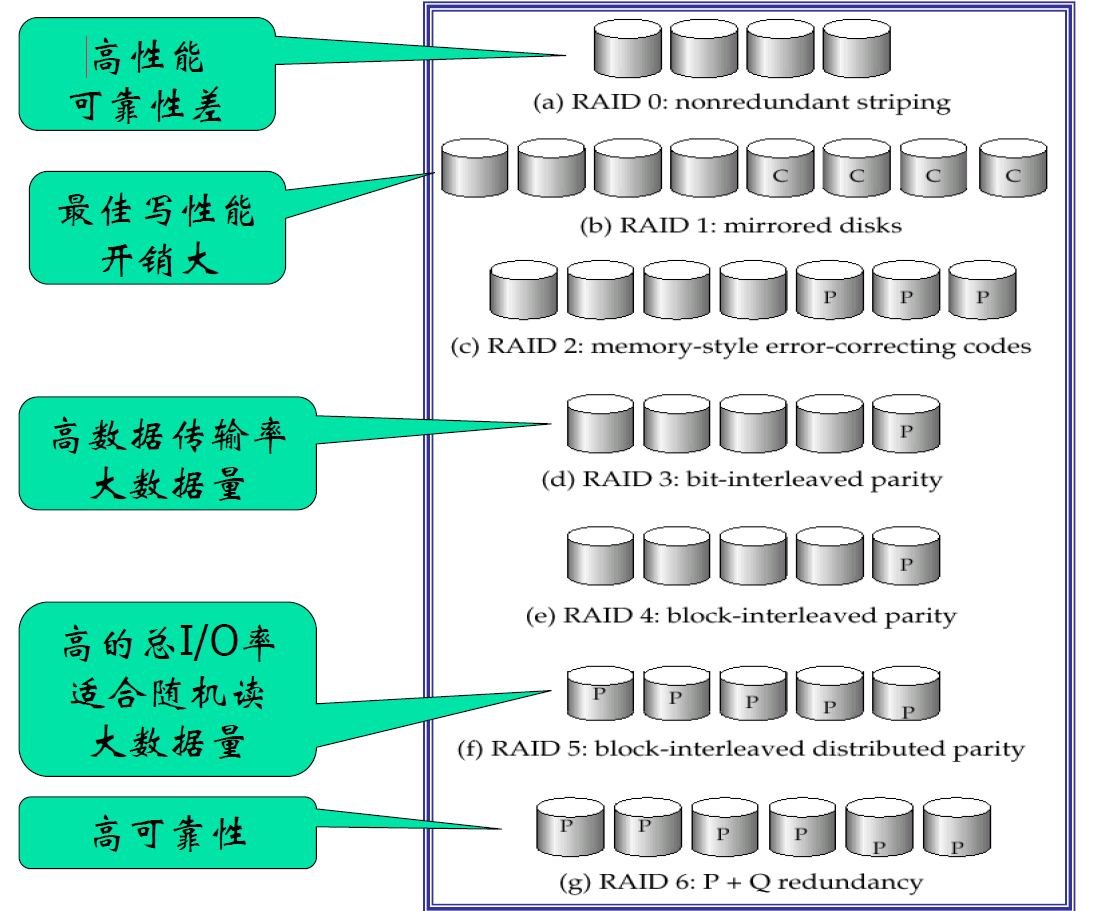
比较
- RAID 1 vs RAID 5
- 为写 1 块数据,RAID5 需要 2 块读和 2 块写
- 如果应用需要每秒 r 次读,w 次写
- RAID 1 要求每秒 r+2w 次 I/O 操作
- RAID 5 要求每秒 r+4w 次 I/O 操作
- 写(4 I/O):阅读待更新块、阅读奇偶校验块、更新块中的数据块、更新奇偶校验块
- 当写操作较少且数据非常大时,RAID 5 较优,否则 RAID 1 更佳
其他
- RAID 的 Write Back
- 插入 20 万条数据,每条数据放在单独一个事务中执行
| RAID卡设置 | 耗时 |
|---|---|
| Write Back | 43 秒 |
| Write Through | 31 分钟 |
| Write Through with innodb_flush_log_at_trx_commit = 0(日志强制写回磁盘、内容不强制) | 68 秒 |