数据库概论.陈立军.09.恢复控制(2)
恢复控制
恢复
事务故障恢复
- 撤消事务已对数据库所做的修改
事务故障恢复过程
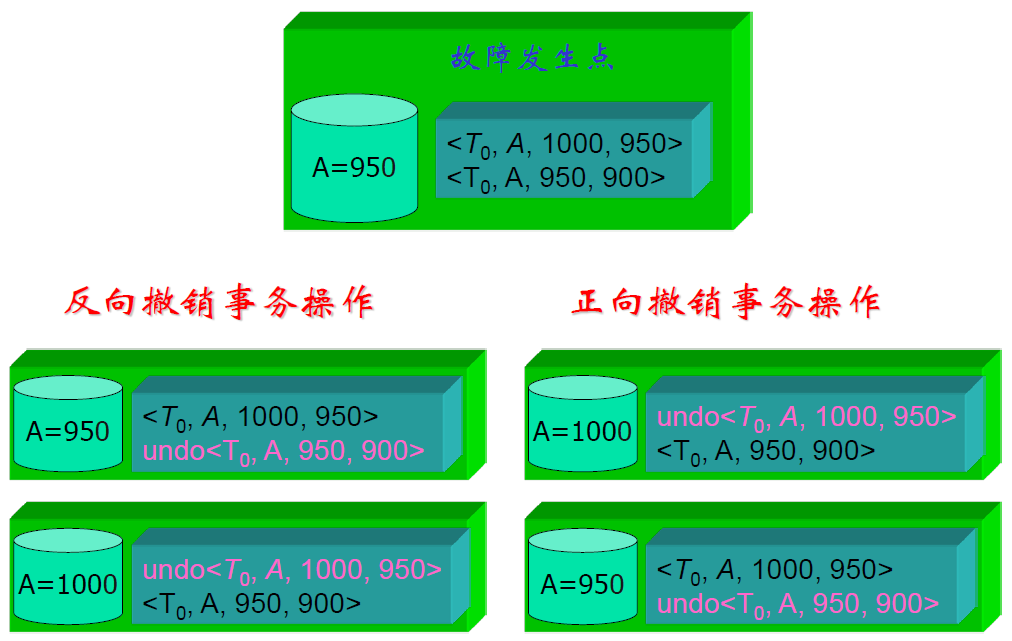
- 反向扫描日志文件,查找该事务的更新操作
- 对该事务的更新操作执行 undo 操作,即将事务更新前的旧值写入数据库
- 继续反向扫描日志文件,查找该事务的其他更新操作,并做同样处理
- 直至读到事务的开始标识,结束事务故障恢复过程
- 同一事务的日志需要反向链接在一起
- 加速事务的撤销操作
- 正向撤销会出错
- 这是显然的,撤销是写的逆过程
山寨版系统故障恢复
- 不一致状态原因
- 未完成事务对数据库的更新已写入数据库
- Steal policy
- 已提交事务对数据库的更新未写入数据库
- 还在 OS Buffer 中
- 未完成事务对数据库的更新已写入数据库
系统故障恢复过程
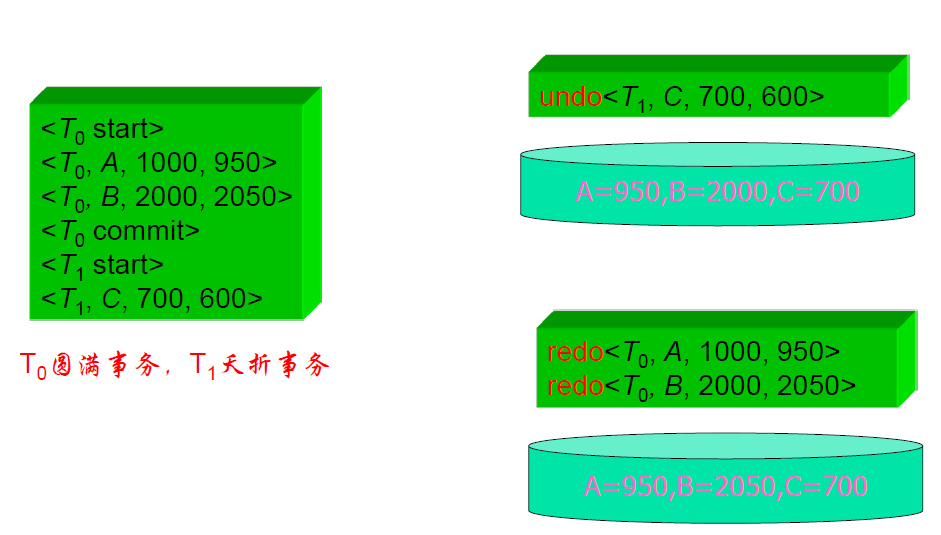
- 正向扫描日志文件,找出圆满事务,记入重做队列;找出夭折事务,记入撤消队列
- 反向扫描日志,对撤消队列中事务 Ti 的每一个日志记录执行 undo 操作
- 正向扫描日志文件,对重做队列中事务 Ti 的每一个日志记录执行 redo 操作
实际数据库
- 对所有操作(不区分成功还是失败),都进行 redo 操作
- 连续操作,磁盘 I/O 友好
- 然后再对夭折事务进行 undo
介质故障恢复
- 磁盘上数据文件和日志文件遭到破坏
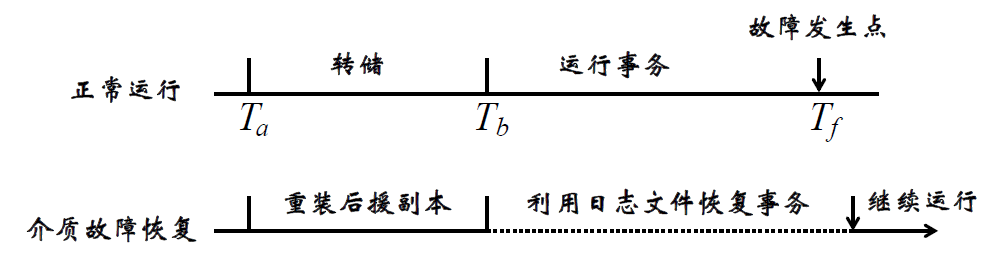
介质故障恢复过程
- 装入最新的数据库后备副本,使数据库恢复到最近一次转储时的一致性状态
- 装入相应的日志文件副本,重做已完成的事务
- 数据文件和日志文件最好不要放在一个磁盘上
检查点(Checkpoint)
- 当系统故障发生时,我们必须搜索整个日志,以决定哪些事务需要 redo,哪些需要 undo
- 大多数需要被重做的事务其更新已经写入了数据库中(\(\mathrm{redo}^2\))
- 因为我们不知道数据是否已经被写入磁盘(异步写缓冲区)
- 尽管对它们重做不会造成不良后果,但会使恢复过程变得更长
- 检查点原理:且行且珍惜
- 保证在检查点时刻,日志与数据库的内容是一致的
带有检查点记录的日志生成
- 将当前日志缓冲区的所有日志记录写入稳存中
- 在日志文件中写入一个检查点记录
- 将当前数据缓冲区的所有数据记录写入稳存中
- 输出检查点时活跃事务的列表 L
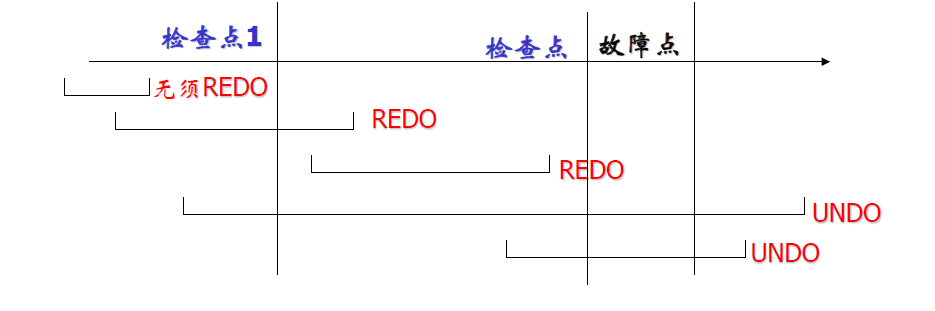
- 我们对检查点之前就已经提交的事务,不需要做 redo 处理
- 只需要对检查点时刻还在活跃的事务、检查点之后出现的事务进行 redo 处理
- 最小日志序列号
- 生成检查点时刻的还在活跃的最小日志记录的序列号
- 长事务再数据库中危害很大
- 并发
- 长事务不释放,检查点做的恢复工作不会少
- 最小序列号之后、但是在检查点之前已经提交的事务需要重做吗?
SQL Server:最小恢复LSN
- MinLSN 是下面这些 LSN 中的最小 LSN:
- 检查点起点的 LSN
- 最旧的活动事务起点的 LSN
SQL Server:生成检查点
- 将标记检查点起点的记录写入日志文件
- 将为检查点记录的信息存储在检查点日志记录链内,将这条链起点的 LSN 写入数据库根页
- 将最小恢复 LSN(MinLSN) 保存在检查点记录中
- 将所有未完成的活动事务列表保存在检查点记录中
- 如果数据库使用的是简单恢复模式,则删除新的 MinLSN 之前的所有日志记录
- 将所有脏日志和数据页写入磁盘
- 将标记检查点末端的记录写入日志文件
恢复过程
- 检查点线程遍历缓冲区池,按照缓冲区编号顺序扫描页面,当它发现脏页时,它将查看与该页面物理(磁盘上)连续的其他页面是否也是脏的,这样它可以进行大块写操作
- 顺序写性能远高于随机写
- 如果它看到页面5是脏的时,它可能会写入页面10、25、380、500等,这些页面在磁盘上是连续的。这样,缓冲区中非连续的页面可以被一次聚集写入(gather-write)磁盘
- 以后检查点会到达页面 500,为避免将该页面重复写入磁盘,检查点算法会为每个页面设置标志位,开始时所有的位都相同(都为0或1)。当检查点检查到某个页面时,它将其标志位翻转。如果检查点碰到具有相反位的页面,它就跳过该页面
- 对于在检查点期间新近引入的页面,或者已经被检查点输出到磁盘但又重新变脏的页面,都不会被该次检查点操作写入
recovery interval
- recovery interval 选项设置 SQL Server 恢复数据库所需的最大分钟数
- 据此 SQL Server 将估计在恢复时间间隔期间可以处理多少更新的数据,从而决定在每一个数据库中 SQL Server 何时生成一次检查点
- SQL Server 根据 10MB 的日志可以在 1 分钟内得到恢复这样一个估计来确定它的恢复间隔
- 当最近一个检查点之后数据更新操作达到了 SQL Server 认为可以在恢复时间间隔更新的数量时,它将进行一个检查点操作
MySQL 检查点执行时机
- Master Thread Checkpoint
- 每秒或每10秒刷出一定比例的脏页
- FLUSH_LRU_LIST Checkpoint
- LRU 列表中空闲页不够时淘汰的页面中有脏页
- Dirty Page too much Checkpoint
- innodb_max_dirty_pages_pct
- Async/Sync Flush Checkpoint
- redo_lsn–checkpoing_lsn 超过日志文件大小75%
杂项
MySQL 日志文件
- 重做日志(redolog)
- 回滚日志(undolog)
- 二进制日志(binlog)
- 错误日志(errorlog)
- 慢查询日志(slowquerylog)
- 一般查询日志(generallog)
- 中继日志(relaylog)
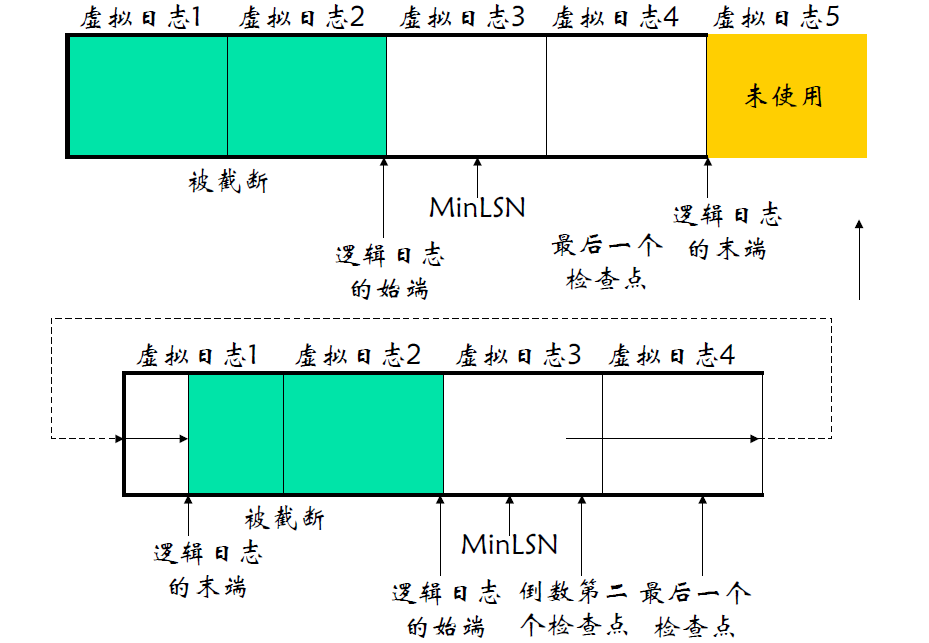
事务日志物理构架
- 循环使用
- 生成检查点的时候,可以释放之前的一些无用日志块
逻辑 Undo 日志
- 针对索引页
- 一般恢复技术要求一旦事务更新了一个数据项,其它事务都不能更新该数据项,直至第一个事务提交或回滚
- 严格两阶段封锁协议实施到某些特殊结构如 B+
树索引页时,并发性极度下降。为提高并发性,可以使锁较早释放
- 提早释放会导致问题
- 如果是物理日志
- A 事务写页 a,B 事务也写页 a,此时 A 事务出错,回滚,页 a 回滚(页面为单位),此时把事务 B 修改的部分给覆盖了
- 逻辑日志则没有这个问题
- 插入操作必须通过一个逻辑 undo 来完成,即通过执行一次删除操作撤消
- 闩锁,自旋锁
- 如果事务 T 向 B+ 树插入了一项,在插入操作结束后但在事务提交前释放了某些锁,那么在锁释放后,其它事务可执行插入或删除操作,于是造成对 B+ 树结点的进一步改变
- 如果使用物理 undo 执行事务回滚,即事务回滚时我们将 B+ 树内部结点(执行插入操作前)的旧值写回,那么其它事务在其后执行的插入或删除操作所做的某些更新可能会丢失
其他恢复技术
提交日志(Commit Logging)
- 特点
- 只有 redo 记录,没有 undo 记录
- 脏数据不会持久化
- 提交时将事务日志都刷写到磁盘
- 如果日志只写到一半时出现系统故障,事务修改也会随之消失。当数据库系统重新恢复时,会发现日志中事务没有完成标记,就好像完全没有发生过一样
- OceanBase、Hekaton(SQL Server 内存存储引擎)
- 如果在系统故障后,重启的时候发现有一条事务没有 commit 标记,怎么办?
- 不需要做任何操作,是一条失败的操作记录(日志不完整而且脏数据没写回磁盘)
- 只需要重做已经成功的日志
Shadow Paging
- 影子页,没有日志的概念
- 在事务操作过程中,被修改的数据会同时存在两份,一份修改前的数据,一份是修改后的数据,这就是影子(Shadow)这个名字的由来
- 持久性保证:事务的修改直接持久化在硬盘上
- 如果在事务提交前出现系统故障,数据库恢复时见不到未完成事务的修改,硬盘上的这个事务曾经修改的数据也会由垃圾回收模块回收
- SQLite
例子
- A 向 B 转账 100
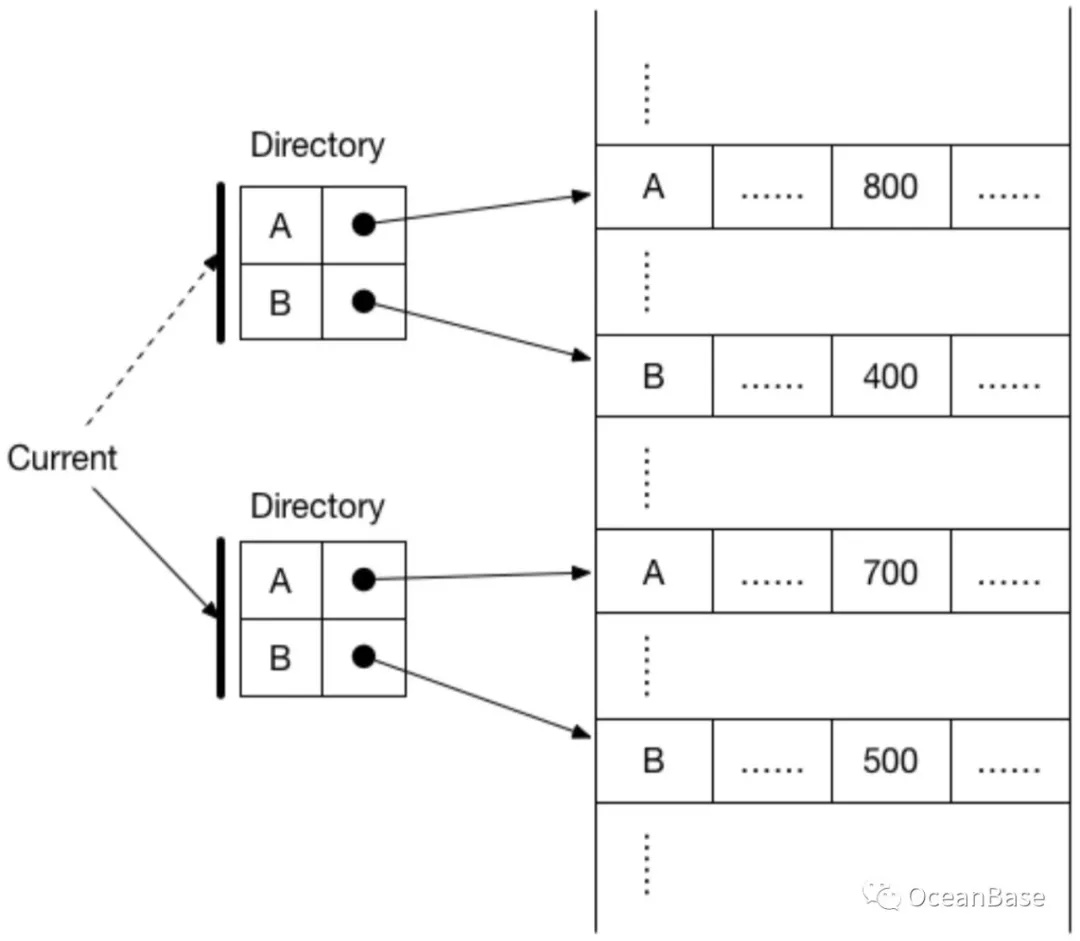
- 当事务提交时,以一次原子的数据写入让整个事务新的修改生效
- A 和 B 的余额都是直接写入新的位置,保证原先的数据没有改动
- 系统通过两个目录结构分别指向修改前的数据和修改后的数据,最后 Current 指针原子切换到新的目录上,表示事务提交成功
镜像数据库
- 主体服务器
- 存放数据库
- 执行事务
- 推送更新(内容数据同步)
- 镜像服务器
- 存放数据库副本
- 接受更新
- 替补篡位(主题服务器宕机)
- 见证服务器
- 自动故障转移
- 判断主体服务器不可用
- 实际部署的问题(为什么需要见证服务器)
- 怎么判断主体服务器是否还在工作:heartbeat
- 如果是由网络故障导致接收不到 heartbeat,镜像服务器不能贸然替补篡位
- 这个由见证服务器判断
- 通常使用投票来决定谁是主题服务器
- 怎么判断主体服务器是否还在工作:heartbeat
- split-brain quorum
复制
- 实现系统的安全性,抗故障能力
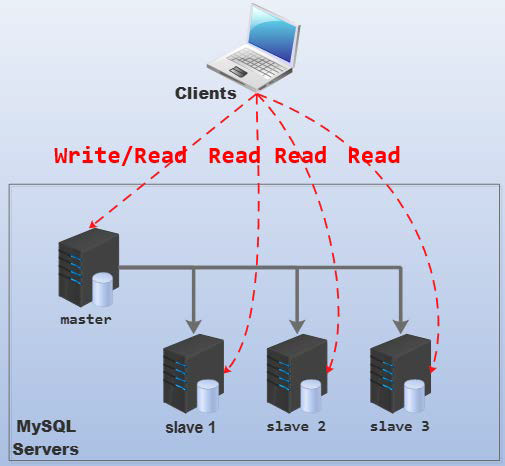
- 读写分离、伸缩性、安全性
- 提高访问的本地性(可以在比较近的服务器上读取数据)
- 增加系统可靠性(一个结点失效,其他结点还是可用的)
数据复制的更新传播策略
- 紧密复制:将所有结点上的副本更新作为一个原子事务的一部分,所有结点上的副本严格同步
- 更新代价大
- 松散复制:更新事务提交之后,异步的将更新传向其他结点
- 各个结点之间会有短暂的不一致
数据复制的更新控制策略
- 主方式(master)
- 每一对象都有一起主结点,只有主结点能够更新对象的主拷贝,其他副本是只读的。其他与更新该对象的结点请求主结点完成更新,由主结点将更新传向其他结点。
- 群方式(group)
- 任何拥有某数据项拷贝的结点都可以更新该拷贝,称之为随处更新(update everywhere)并将更新操作广播到其他结点
- 需要设计冲突协调策略?怎么解决冲突?
- 人为设计:时间靠后、值较大 ······
数据复制的更新策略
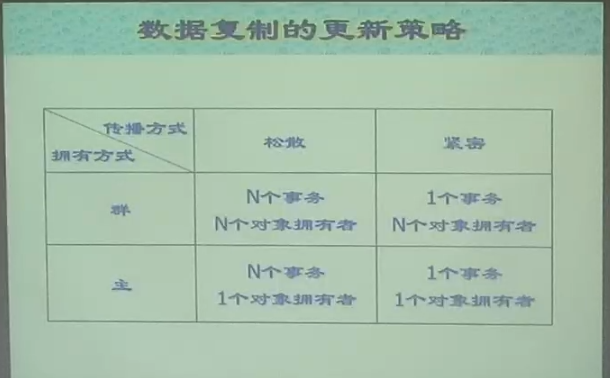
- 松散 + 群:数据一致性很差,数据库场景中实际应用较少
- SQL Server 4 种都支持
MySQL 复制类型
- 没有群方式,只有主从
- 所有的更新都发生在主结点,再由主结点将更新推送给其他结点
- 主从 + 同步/异步
同步复制
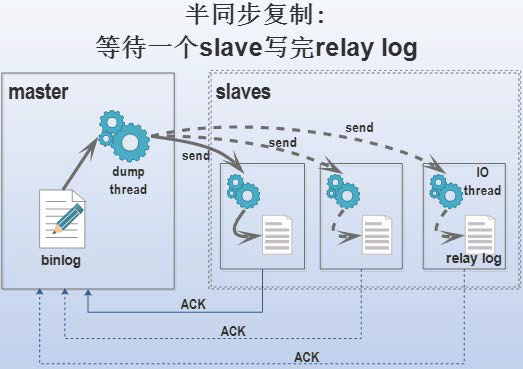
- 只有所有的 slaver 更新完成之后,整个事务才完成
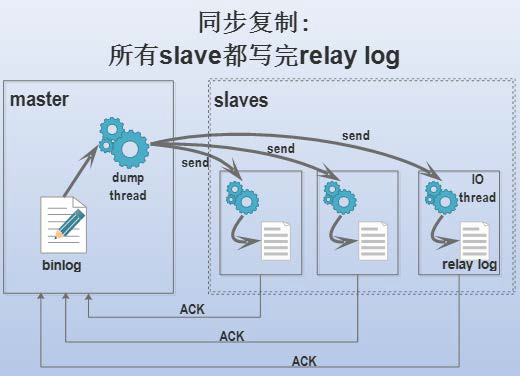
- 主结点发送一个 binlog 到其他的从结点,slaver 结点再现这个 log ,然后发送 ACK 回主结点
异步复制
- 主结点不会等待从节点更新完成
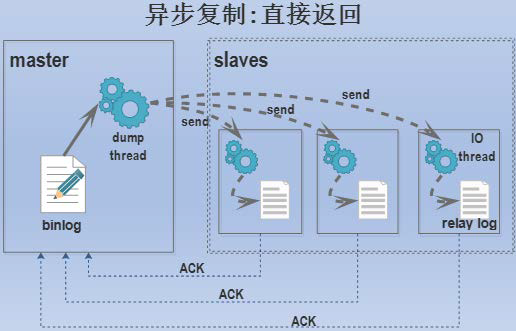
- 问题
- 主结点更新完就挂了,此时数据丢失,无法恢复
半同步复制
- 主结点等待某一个从结点更新结束之再进行接下来的操作