0%
恢复控制
- 目标
- 可能的措施
- 备份
- 日志
- 把内存总的数据刷到稳定存储介质(磁盘等)上(ctrl+S)
故障
事务故障
- 事务的运行没有到达预期的终点就被终止
- 影响范围只在这个事务上
非预期故障
- 不能由事务程序处理的(异常)
- 如运算溢出,发生死锁而被选中撤消该事务
可预期故障
- 应用程序可以发现的事务故障,并且应用程序可以让事务回滚
- 如转帐时发现帐面金额不足
- 写了异常处理,那么可以把非预期故障转变为可预期故障
系统故障
- 软故障(soft crash)
- 在硬件故障、软件错误的影响下,虽引起内存信息丢失,但未破坏外存中数据
- 如CPU故障、突然停电,DBMS、OS、应用程序等异常终止
介质故障
- 硬故障(hard crash)
- 又称磁盘故障,破坏外存上的数据库,并影响正在存取这部分数据的所有事务
- 如磁盘的磁头碰撞、瞬时的强磁场干扰
- 只能通过备份等方式恢复
恢复的定义
- 恢复是把数据库从错误状态恢复到某一正确状态的功能,从而确保数据库的一致性
- 恢复的基本原理是冗余,即数据库中任一部分的数据可以根据存储在系统别处的冗余数据来重建
- 冗余
备份
转储
- 生成备份的过程:转储(dump)
- 将数据库复制到磁带或另一个磁盘上保存起来的过程
- 这些备用数据称为后备(后援)副本
转储类型
- 静态转储
- 转储期间不允许对数据库进行任何存取、修改活动
- 转储期间不向外提供服务
- 动态转储
- 转储期间允许对数据库进行存取或修改
- 转储期间数据块还对外提供服务
- 海量转储
- 增量转储
SQL Server 数据库备份
- 完整的数据库备份
- 数据库备份创建备份完成时数据库内存在的数据的副本,通常按常规时间间隔调度
- 还原数据库备份将重新创建数据库和备份完成时数据库中存在的所有相关文件
1
2
3
4
5
6
7
| USE master
EXEC sp_addumpdevice 'disk', 'MyBKDB', DISK ='c:\MyBKDB.dat'
BACKUP DATABASE LJCHEN TO MyBKDB
RESTORE DATABASE LJCHEN FROM MyBKDB
|
SQL Server 差异数据库备份
- 差异数据库备份(DCM)
- 差异数据库备份只记录自上次数据库备份后发生更改的数据,比数据库备份小而且速度快
- 使用差异数据库备份将数据库还原到差异数据库备份完成时的那一点
- 初始得是一个全量的备份
1
2
3
4
5
6
7
|
BACKUP DATABASE LJCHEN TO MyBKDB WITH INIT
BACKUP DATABASE LJCHEN TO MyBKDB WITH DIFFERENTIAL
RESTORE DATABASE LJCHEN FROM MyBKDB WITH NORECOVERY
RESTORE DATABASE LJCHEN FROM MyBKDB WITH FILE=2, RECOVERY
|
- 一个位图,每一个页一位,如果修改了则把这个页对应位图上的位置为 1
SQL Server 事务日志备份
- 事务日志是自上次备份事务日志后对数据库执行的所有事务的一系列记录,它可以将数据库恢复到特定的即时点或恢复到故障点
1
2
3
4
5
| BACKUP DATABASE MyDB TO MyDB_1 WITH INIT
BACKUP LOG MyDB TO MyDB_log1
BACKUP LOG MyDB TO MyDB_log2 WITH NO_TRUNCATE
|
1
2
3
4
5
| RESTORE DATABASE MyDB FROM MyDB_1 WITH NORECOVERY
RESTORE LOG MyDB FROM MyDB_log1 WITH NORECOVERY
RESTORE LOG MyDB FROM MyDB_log2 WITH RECOVERY
|
- WITH NORECOVERY:重做所有日志记录
- WITH RECOVERY:回滚失败事务日志记录
一个例子
1
2
3
| read(A); A:=A-50; write(A);
read(B); B:=B+50; write(B);
commit
|
- 由于某些原因,事务 T 的两个操作被写到两个日志文件
MyDB_log1、MyDB_log2 中了
1
2
3
4
5
6
| MyDB_log1
<T,A,100,50>
MyDB_log2
<T,B,100,150>
commit
|
1
2
3
4
5
6
7
| RESTORE LOG MyDB FROM MyDB_log1 WITH NORECOVERY
RESTORE LOG MyDB FROM MyDB_log2 WITH RECOVERY
|
1
2
3
4
5
6
7
8
| RESTORE LOG MyDB FROM MyDB_log1 WITH RECOVERY
RESTORE LOG MyDB FROM MyDB_log2 WITH RECOVERY
|
- 因此告诉我们,如果我们有多个日志备份文件
- 前面的文件应该都是
WITH NORECORERY
- 只有最后一个日志文件是
WITH RECOVERY
SQL Server 恢复模型
- 我们期望能够保留下来的工作越多,也就是希望数据库能够恢复到更近的一致性的状态
简单恢复
- 允许将数据库恢复到最新的备份
- 简单数据库备份,没有日志,只能恢复到最新的数据库备份那一刻的内容
- 数据库备份 + 差异备份(可选)
完全恢复
- 允许将数据库恢复到故障点状态
- 完全恢复(恢复到尽可能近的状态),先通过数据库备份恢复,然后通过日志记录恢复
- 数据库备份 + 差异备份(可选) + 事务日志备份
大容量日志记录恢复(BCM)
- 允许大容量日志记录操作(select into,bcp,bulk insert)
- 批量的修改会导致日志文件庞大,对性能造成影响
- 这种模式下,日志文件中只记录操作的帧,操作所影响的数据写到其他的数据文件中
- BCM 位图实现,把影响的页面单独写出去,并在位图上做标记
- 数据库备份 + 差异备份(可选) + 事务日志备份
切换恢复模型
- 可以将数据库从一个恢复模型切换到另一个恢复模型,以满足不断变化的业务要求
- 例如,如果系统需要完全的可恢复性,可以在装载和索引操作的过程中,将数据库的恢复模型更改到批量日志记录模型,然后再返回到完全恢复
1
2
3
4
5
6
|
alter database <database_name>
set recovery[ FULL | BULK_LOGGED | SIMPLE ]
select database propertyex('<database_name>', 'recovery')
|
MySQL 备份类型
- 备份内容
- 逻辑备份:从表的角度备份
- 裸文件备份:把磁盘上面的数据文件备份出去
- 备份方法
- 热备(Hot Backup):数据库保持业务工作的同时进行备份
- 冷备(Cold Backup):数据库停下来备份
- 温备(Warm Backup):只允许读操作下执行,不允许写操作执行
- 备份数据库内容
MySQL 备份工具
1
2
3
4
| mysqldump --databases db1 db2 db3 > dump.sql
mysqldump --no-data -databases db1 db2 > structure.sql
mysqldump test t1 t3 t7 > dump.sql
source dump.sql
|
1
2
3
4
5
6
7
8
9
10
11
|
select * into outfile 'data.txt'
fields terminated by ','
lines terminated by '\r\n'
from my_table
load data infile 'data.txt'
into table my_table
fields terminated by ','
lines terminated by '\r\n'
|
MySQL 热备工具
1
2
3
4
5
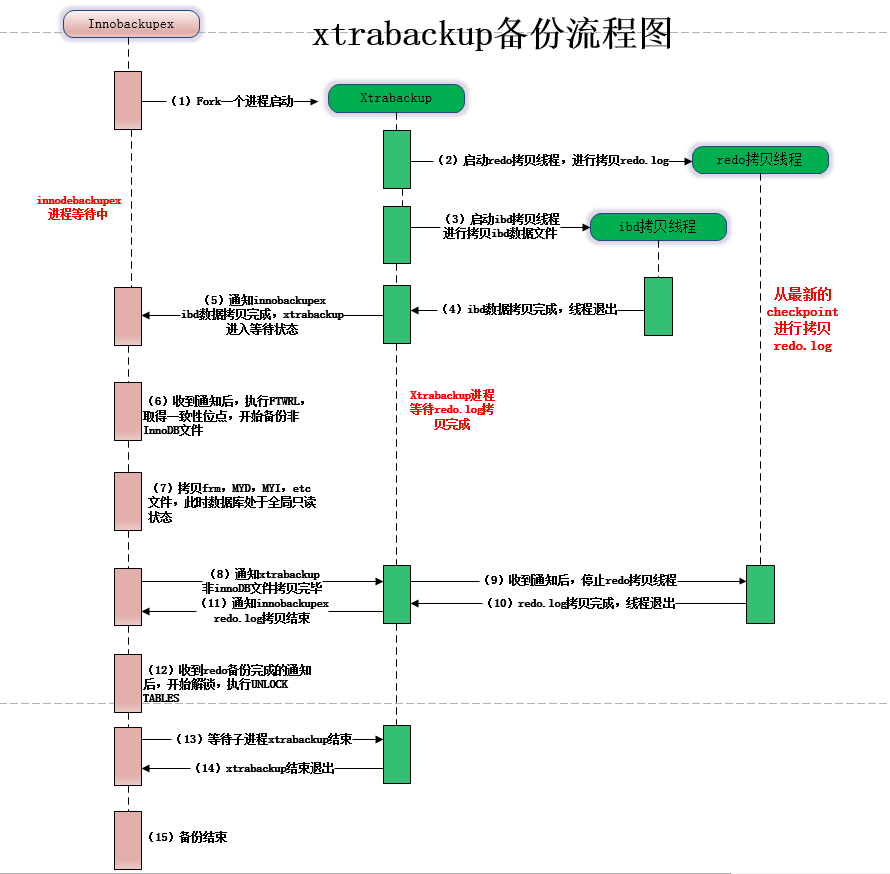
| innobackupex --user=root --password=123456 --host=127.0.0.1 /backups/
innobackupex --apply-log /backups
innobackupex --copy-back /backups
|
- 在增量备份时,比较表空间中每个页的 LSN
是否大于上次备份时的 LSN,若是,则备份
日志
- 日志文件是以事务为单位用来记录数据库的每一次更新活动的文件,由系统自动记录
- 日志内容包括
- 记录名、旧记录值、新记录值、事务标识符、操作标识符等
- 内容如下
- 事务 Ti 开始时,写入日志:Tistart
- 事务 Ti 执行 write(X) 前,写入日志:<Ti,X,V1,V2>
- V1 是 X 更新前的值,V2 是 X 更新后的值
- 事务 Ti 结束后,写入日志:Ticommit
- 日志记录的是值的变换,而不是逻辑的操作
- 记录的是物理值的话,不管重复多少次,结果中是一致的
- 如果记录具体的逻辑操作,重复多次的结果不一样
事务分类
- 基于日志记录对事务进行分类
- 圆满事务(成功了)
- 夭折事务(失败的)
- 日志文件中只有事务的 begin transaction 标识,无 commit
基本的恢复操作
- 对圆满事务所做过的修改应执行 redo
操作,即重新执行该操作,修改对象被赋予新记录值
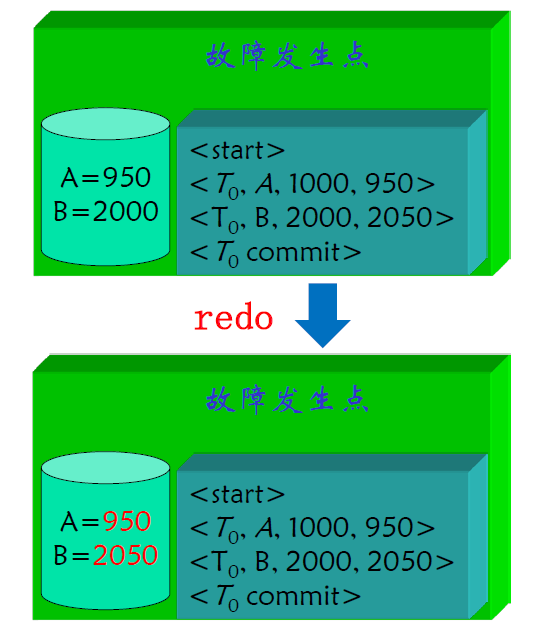
- 不管 redo 多少次,结果都是一样的(\(\mathrm{redo^2=redo}\))
- 对夭折事务所做过的修改应执行undo操作,即撤消该操作,修改对象被赋予旧记录值
事务的原语操作
- input(X):将包含数据库元素 X
的磁盘块拷贝到内存缓冲区
- read(X,t):将内存缓冲区的数据库元素 X
拷贝到事务的局部变量 t
- write(X,t):将局部变量 t
的值拷贝到内存缓冲区中的数据库元素 X
- output(X):将包含 X
的缓冲区拷贝回磁盘
- 发出者不同
- read 和 write 由事务发出
- input 和 output
由缓冲区管理器(或日志管理器)发出
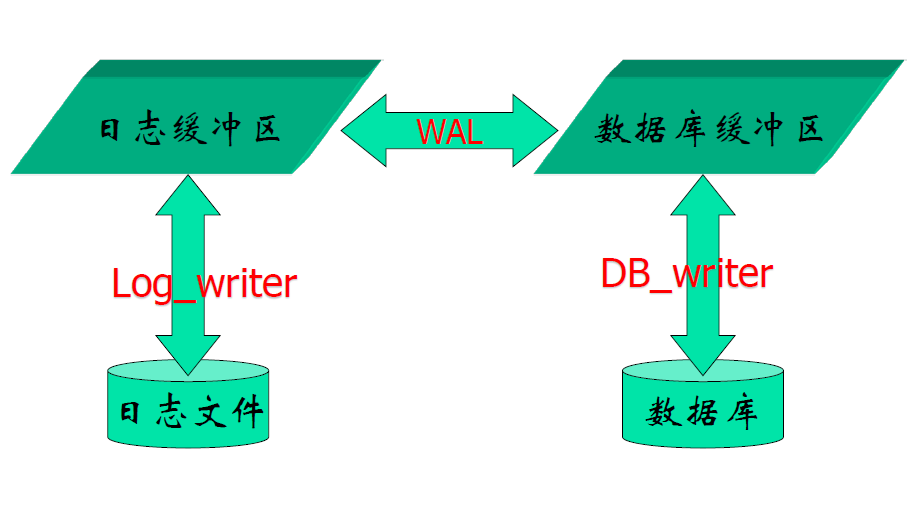
先写日志的原则(WAL)
- 保证原子性(all or not)
- 日志记录将要发生何种修改
- 写入 DB 表示实际发生何种修改
- Write Ahead Log(WAL)
- 对于尚未提交的事务,在将DB缓冲区写到外存之前,必须先将日志缓冲区内容写到外存去
- 如果先写
DB,则可能在写的中途发生系统崩溃,导致内存缓冲区内容丢失,而外存 DB
处于不一致状态,由于日志缓冲区内容已破坏,导致无法对 DB 恢复
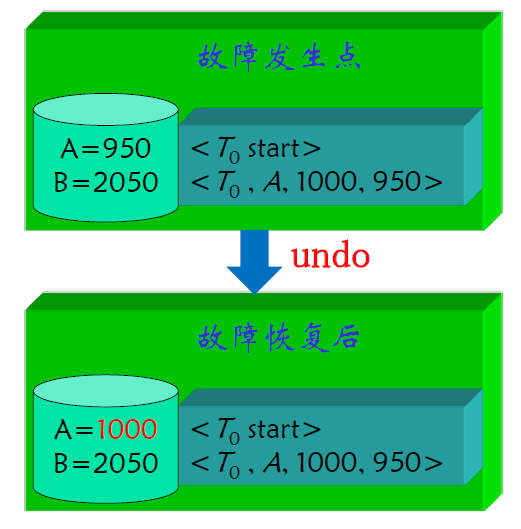
- 如果先写数据库再写日志记录的话
- 假设这样的一种情况,日志记录还没写完,系统崩溃了
- 此时日志中只有 A 的记录
- 故障恢复的时候,由于缺少 commit,认为是夭折事务,执行 undo
- 此时 B 的结果没有修改回去,造成错误(不一致)
- 先写日志则能够恢复到一致的状态
- 以下是写 B 日志的时候系统崩溃了的情况
- 此时 redo 操作能够撤销 A 的修改,虽然 B 没有修改,但是 redo
也不会将其改成错误数据
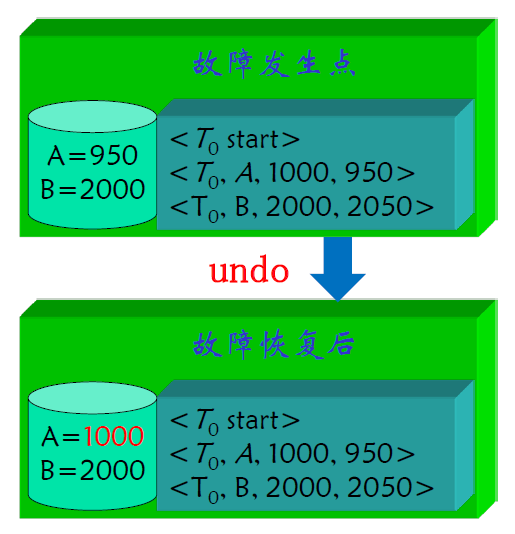
- 日志写完了,但是磁盘没写完,此时系统崩溃了,通过 redo
操作实现一致
写时机
- 日志缓冲区和数据库缓冲区的写时机不同
- 同步(synchronous)写日志
- 只有事务的相关日志已经完全在磁盘上了,才会向进程发送该事务已提交的确认消息
- 事务提交驱动
- 异步(asynchronous)写缓冲区
- 只需要将数据页的写入操作投递给操作系统即可,不需要等待其完成
- 不是事务提交驱动的
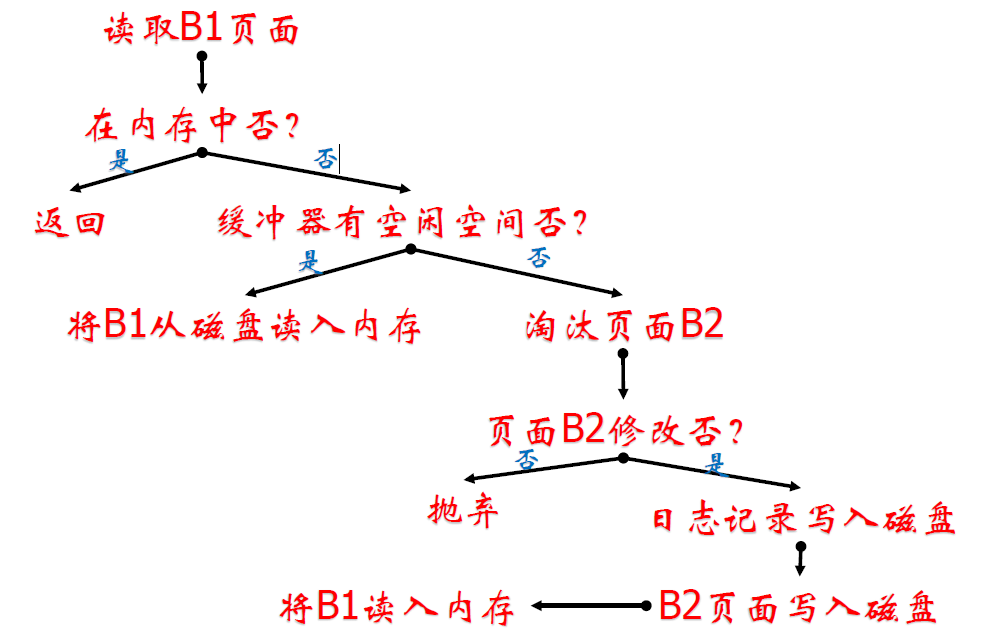
Buffer Manager(BM)
- 不同策略(当然要求先写日志)
- Steal policy
- 对内存页面的更改可以随意同步回硬盘而不需要等待事务提交
- Force policy
- ARIES 的 BM 遵循 “Non-Force,Steal”
- 如果必须等待所有更改过页面的事务都提交了才同步这个内存页到磁盘会如何?
- 如果需要支持行锁,那么一个页面可能有多个行被不同的 Tx
更改,这个页面必须等待所有的 Tx 都 Commit,但是如果不断有新的 Tx
来更改这个页面,这个页面就迟迟无法同步回物理页面
读取一个页面的过程
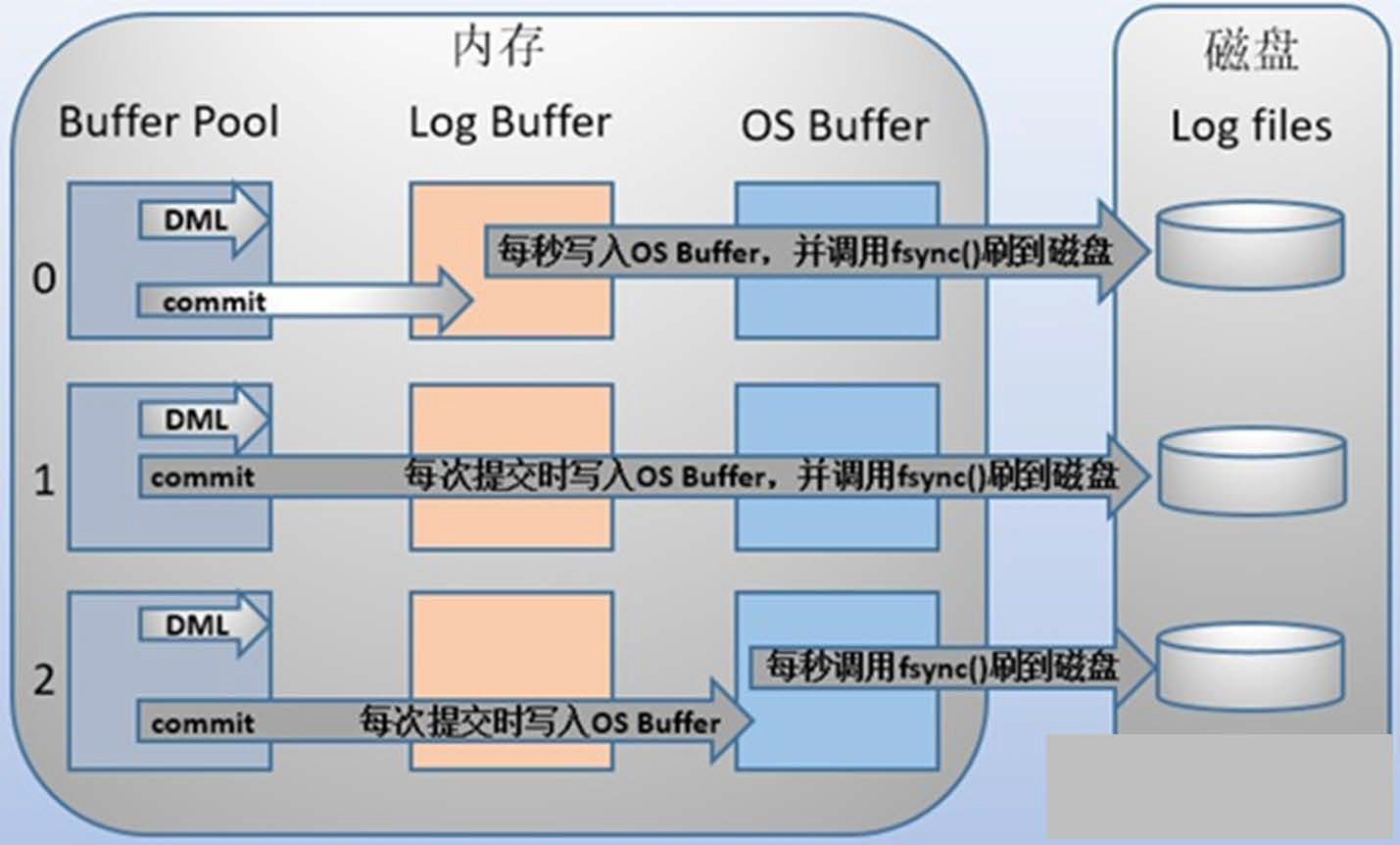
MySQL 日志刷写时机
- 在主线程每秒一次的循环中,将重做日志缓冲器的内容刷新到重做日志文件中,即便某个事务尚未提交
- 由参数 innodb_flush_log_at_trx_commit 控制
- 0 代表提交事务时,并不立即刷出日志,而是等待主线程每秒的刷新
- 1 代表提交事务时,将重做日志同步写磁盘,也即伴有 fsync() 的调用
- 2 代表提交事务时,将重做日志异步写磁盘,也即写入文件系统缓存中
- 有两个缓冲区
MySQL 组提交
- 磁盘 I/O 开销大
- fsync 是昂贵的操作,MySQL 一次事务提交最多会导致 3 次 fsync
- 组提交通过将多个并发需要提交的事务共享一次 fsync
操作来进行数据的持久化
- binlog_group_commit_sync_delay=N
- binlog_group_commit_sync_no_delay_count=N