数据库概论.陈立军.08.数据挖掘简述
数据挖掘
- 一个广为流传的例子:啤酒和尿布
- 数据挖掘是识别数据中有效的、新颖的、潜在有用的、最终可被理解的模式的非平凡过程
预测型工具
- 有效的
- 该模式具有足够的通用性,即对于新数据,该模式同样适用
- 新颖的
- 该模式是深层次的,事先无法预料的
- 潜在有用的
- 该模式可以指导一些有效的行为,不仅仅是检索有效的新颖的模式,可以指导决策人员进行科学决策
- 最终可被理解的
- 该模式必须简单易懂
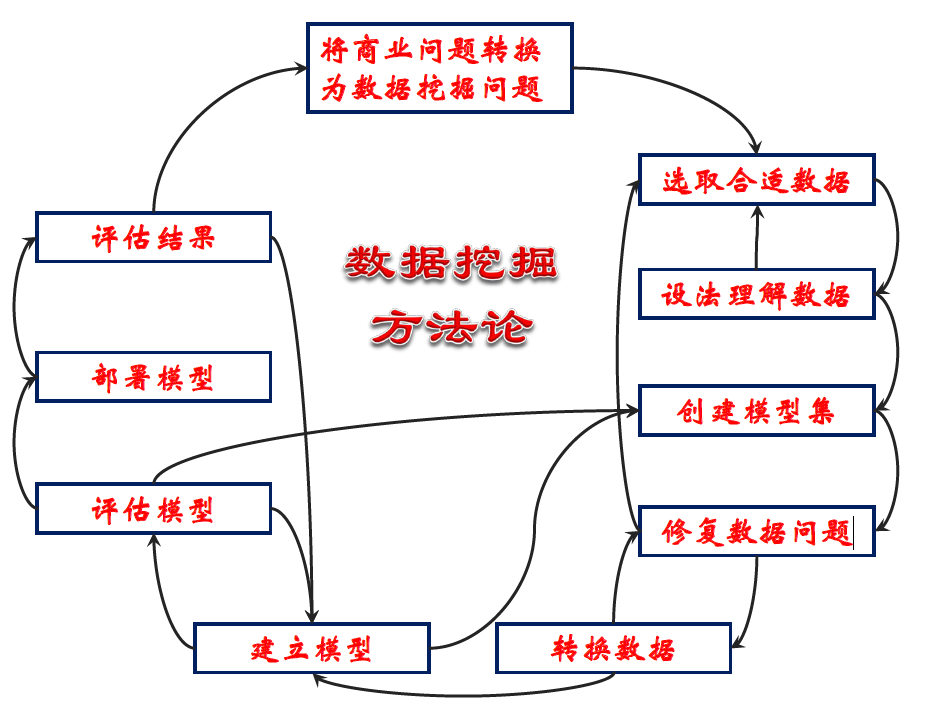
数据挖掘方法论
数据挖掘的任务与方法
| 数据挖掘任务 | 描述 | 相关技术 |
|---|---|---|
| 数据划分 | 聚类分析:
在预先没有确定类别的情况下,根据数据的不同属性,将数据分成不同的类别。 分类分析:将数据映射到预先定义的数据类别中 |
聚类分析 Bayesian分类 决策树或分类树 人工神经网络 |
| 依赖分析 | 找出各个属性之间的依赖关系 | Bayesian网络 关联分析 |
| 奇异点分析 | 找出与一般数据行为不一致的数据项 | 聚类分析 奇异点检测 |
| 趋势检测 | 通常在时间序列上,对数据库中的数据利用线性回归或曲线拟合等方式进行综合分析 | 回归分析 序列模式分析 |
查询分析
- 查询哪些商品经常被购买
1 | Select item, count(*) |
- 查询哪两个商品经常一起被购买
1 | Select t1.item, t2.item, count(*) |
- 上面简单的连接,效果很差,运行很慢
关联分析
- 目的:发现数据间的相互关联
- 购物篮分析:给定一组商品,一个交易集合,通过分析交易记录集合,推导出商品间的相关性
- 基本形式
- 给定:一组事务集,每一个事务中包含若干个数据项
- 挖掘:各个数据项之间的关联
- 结论:98% 的顾客在购买电动剃须刀的同时会购买一些电池
关联分析支持度(support)
- 在关联分析中表示满足规则的记录数与总记录数的比
- 它表明了规则的模式在数据库中出现的频度
- 对于规则:\(X\to Y\),其支持度表示为
$$
$$
关联分析置信度(confidence)
- 在关联分析中表示为满足规则的记录数与出现被分析数据项的记录数之比
- 对于规则:\(X\to Y\),其置信度表示为
\[ C=\dfrac{同时购买商品\;X\;和\;Y\;的交易数}{购买商品\;X\;的交易数} \]
关联分析核心:发现频繁项集
- 频繁项集:出现频率超过预设支持度的项集
- 关联分析就是发现频繁项集的过程
- 不能够先生成商品组合然后逐一过滤,这样候选集太大了
先验(Apriori)法则
一个频繁项集的任何非空子集肯定也是频繁项集
\(\{A,B\}\) 为频繁项集,那么其子集 \(\{A\}\)、\(\{B\}\) 也都为频繁项集
反单调
- 一个集合如果不是频繁的,则它的任何超集也不是频繁的
由低阶频繁项集构造高阶频繁项集
关联分析示例
- 表格如下
| TID | 项集 |
|---|---|
| 1 | 面包,牛奶 |
| 2 | 面包,啤酒,鸡蛋,尿布 |
| 3 | 牛奶,啤酒,尿布,可乐 |
| 4 | 面包,牛奶,啤酒,尿布 |
| 5 | 面包,牛奶,尿布,可乐 |
- 结果
- 尿布 \(\to\) 啤酒 支持度 \(\dfrac35\),置信度 \(\dfrac34\) 啤酒 \(\to\) 尿布 支持度 \(\dfrac35\),置信度 \(\dfrac33\)
先验法则求解
- 设定最小支持度为 3
- 依次寻找一阶项、二阶项、三阶项
| 1阶项 | 计数 |
|---|---|
| 啤酒 | 3 |
| 面包 | 4 |
| 可乐 | 2 |
| 尿布 | 4 |
| 牛奶 | 4 |
| 鸡蛋 | 1 |
| 2阶项 | 计数 |
|---|---|
| 啤酒, 面包 | 2 |
| 啤酒, 尿布 | 3 |
| 啤酒, 牛奶 | 2 |
| 面包, 尿布 | 3 |
| 面包, 牛奶 | 3 |
| 尿布, 牛奶 | 3 |
| 3阶项 | 计数 |
|---|---|
| 面包, 尿布, 牛奶 | 3 |
关联分析算法过程
连接步
- 对 K-1 阶频繁项集 Lk-1 做 Self-Join 操作,形成 K 阶频繁项集的候选集
Ck
- 前 K-1 项相同,第 K 项 p<q(避免重复)
1 | insert into Ck |
剪枝步
- 任何 K-1 阶非频繁项集,则其不可能为 K 阶频繁项集的子集
1 | for all itemsets c in Ck do: |
关联分析算法例子
- 3 阶高频项目集:L3={ abc, abd, acd, ace, bcd }
- 连接步
- Self-joining:L3*L3
- abc, abd \(\to\) abcd
- acd, ace \(\to\) acde
- 剪枝步 acde 移出,因为 ade 不包含在 L3 中
- 4 阶候选集:C4={ abcd }
- 还得在数据库中验证之后才能称为 4 阶高频项目集
SQL 实现
- 最核心的问题:如何实现对候选集的计数
- 论文:Integrating Association Rule Mining with Relational Database Systems: Alternatives and Implications
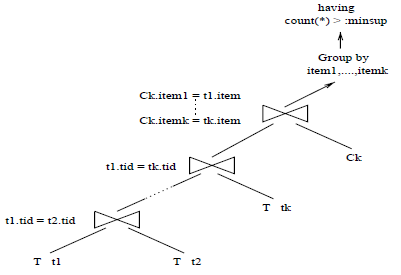
基于连接实现
- K-ways joins
- 代码

- 图示
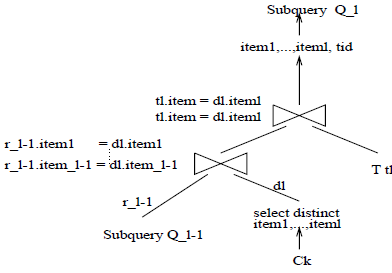
基于子查询实现
- subquery
- 代码

- 图示
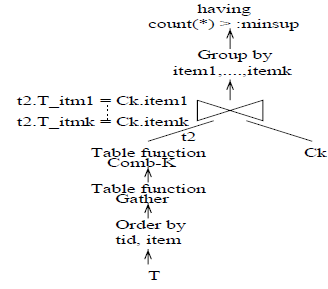
基于面向对象的 SQL 实现
- 代码

- 图示
关联分析和相关性分析
- 实际可能是负相关
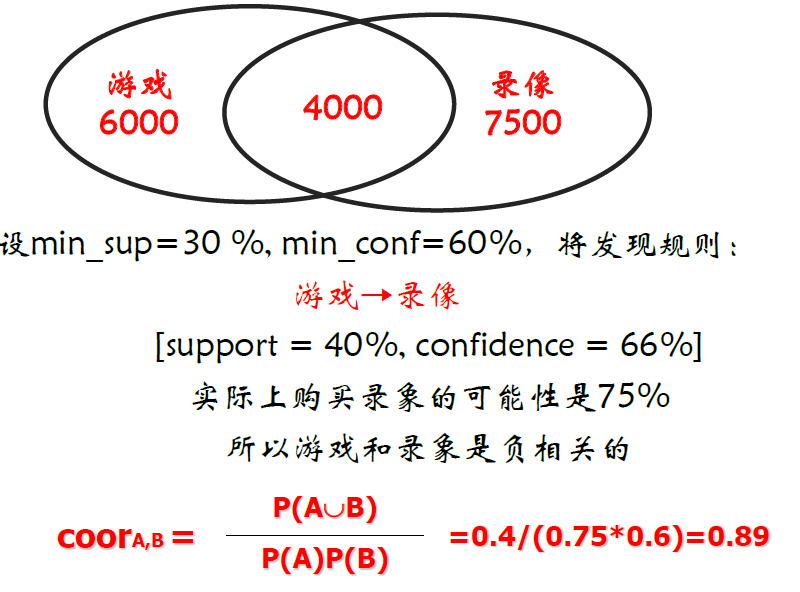
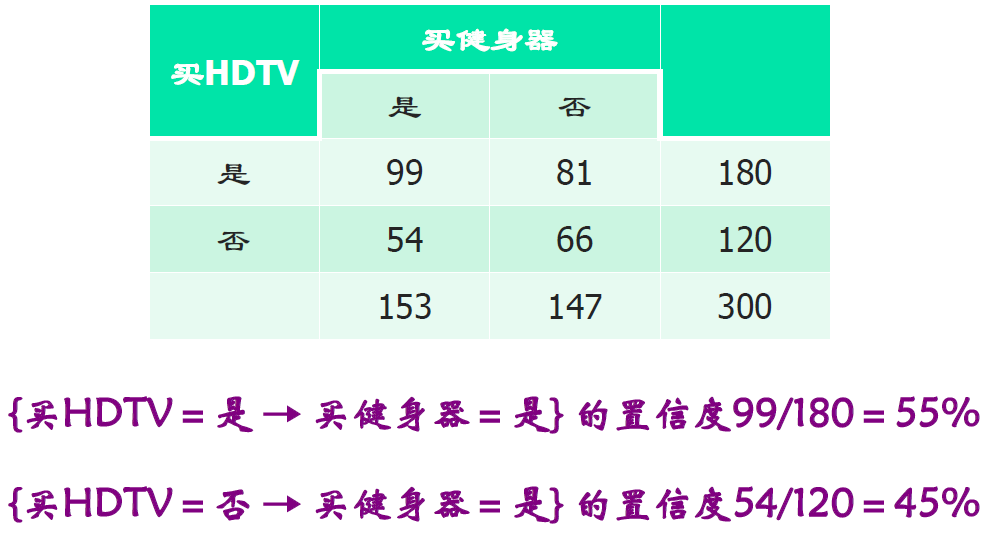
关联分析的辛普森悖论
- 数据子集显示出来的结果和数据集本身相反
- 数据集
- 数据子集
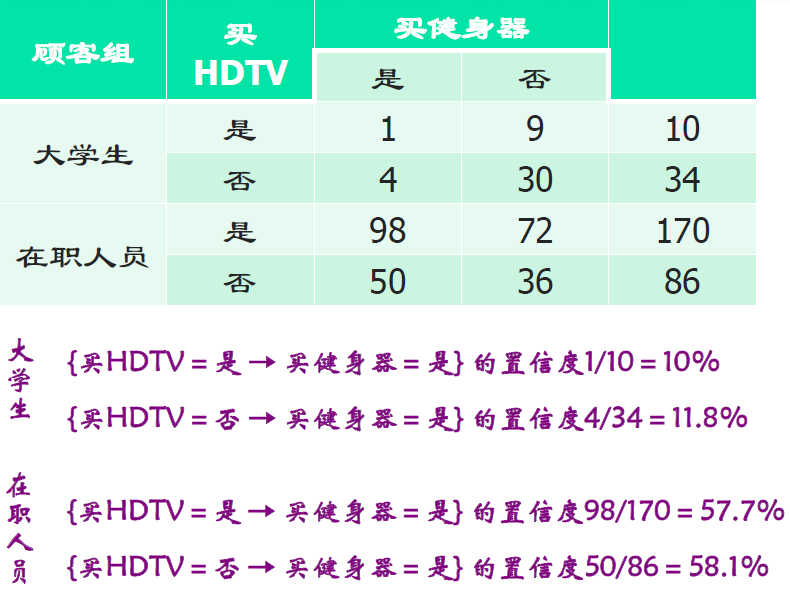
- 原因
\[ \begin{align} \dfrac{a}{b}&<\dfrac{c}{d}\\ \dfrac{p}{q}&<\dfrac{r}{s}\\ \dfrac{a+p}{b+q}&<\dfrac{c+r}{d+s}\\ \end{align} \]
- 提示:数据子集的划分要仔细,否则可能得出相反结论
- 连锁超市的购物篮应按商店位置分层
- 病人医疗记录应按年龄、性别等分层
序列关联分析
分类分析
- 决策树
- 朴素贝叶斯
- 支持向量机 SVM
聚类分析
- 无监督学习
- 基于划分
- K-means