GAMES202.闫令琪.14.工业界算法实现
- https://www.bilibili.com/video/BV1YK4y1T7yY

工业界算法实现
- A Glimpse of Industrial Solutions (from the scientific perspective)
AA
- Anti-Aliasing:反走样
TAA
- Temporal Anti-Aliasing
- TAA 算法的成功,才有了 temporal 思想在 RTRT 中的应用
- 走样的来源:对于每个像素的采样数不够(采样定理)
- 解决思路:使用更多的样本
- temporal
AA:使用更多的样本,但是是使用更多上一帧(以及之前帧)的样本
- 思路和 RTRT 中是一样的
静止场景
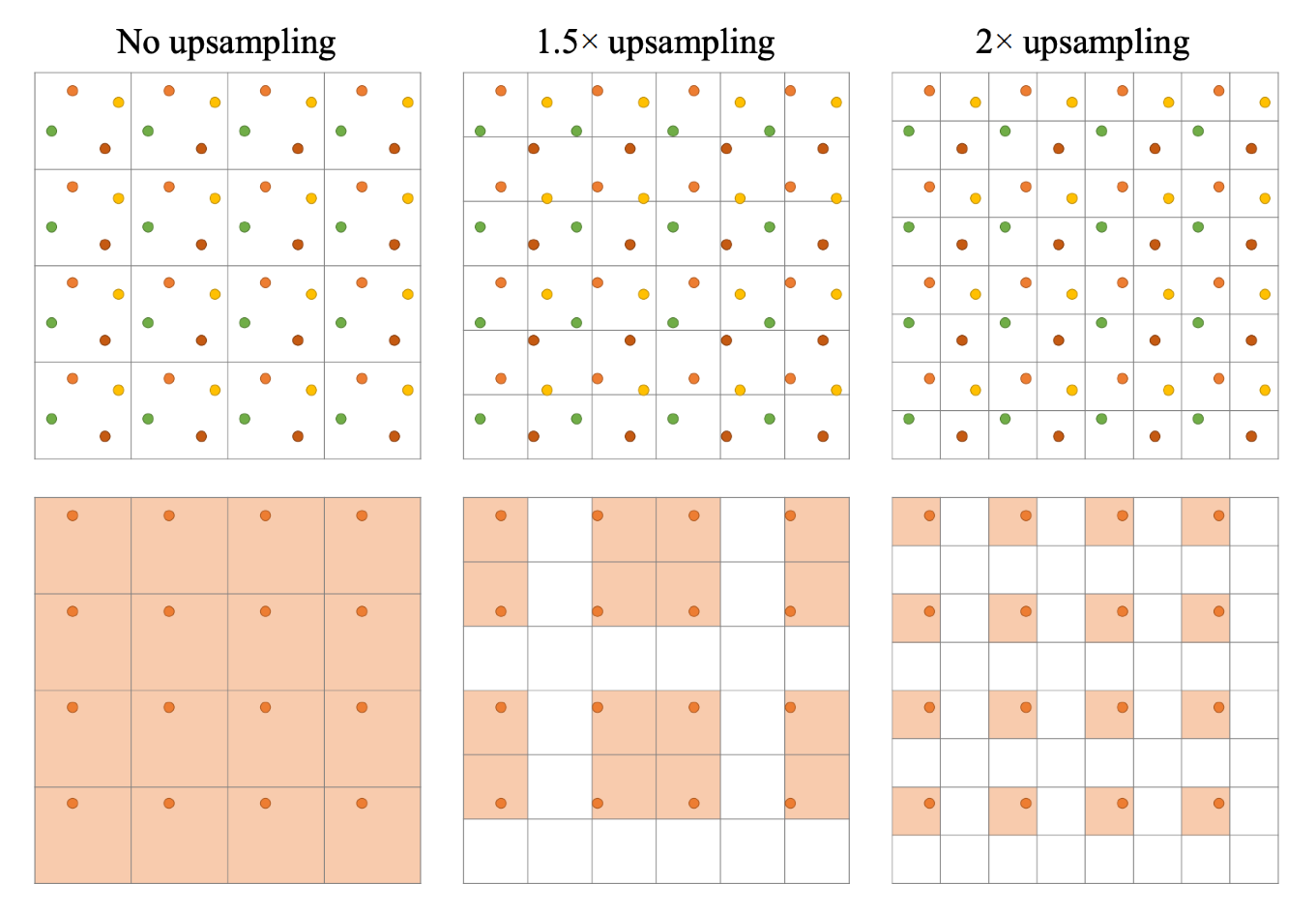
- 怎么复用上一帧的样本?
- 一种想法,每一帧采不同的区域
- 连续 4 帧,分别采样 左上、右上、右下、左下(移动的 sampling pattern)
- 复用上一帧,递归形成复用之前所有的样本的 sampling

- 为什么不随机生成呢?
- 相对均匀分布
- 如果随机会引入一些额外的高频信息,效果可能不太好
运动场景
- motion vector
- temporal 信息不可用的时候,也是使用 clamping 的方法
- 基本上和 RTRT 中的思路一致
MSAA 和 SSAA
- SSAA:Supersampling
- 渲染的时候,使用更高的分辨率,在渲染结束后,降采样到要求的分辨率
- 正确的,效果非常好,但是开销非常大
- MSAA:Multisampling AA
- 一个 primitive 只会进行一次 shading
- 下图中,SSAA 需要做 4 次 shading,MSAA 只需要做两次
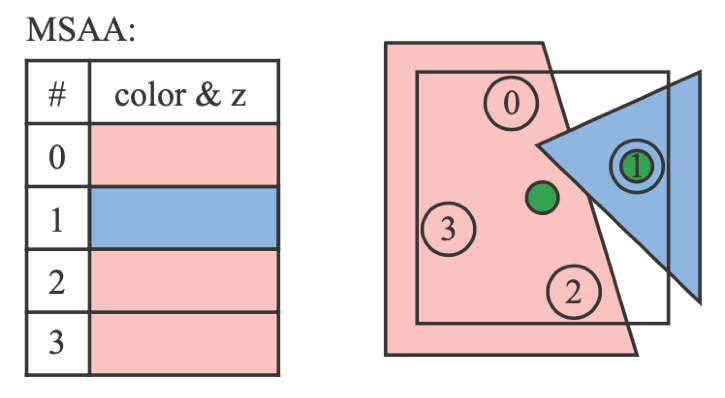
- MSAA 支持空间上的复用
- (1)(2) 中间的两个采样点可以被视为对 (1) 的贡献,也能被当作对 (2) 的贡献
- 复用了中间两个点
- https://www.sapphirenation.net/anti-aliasing-comparison-performance-quality
图像上的 AA
- 先渲染得到带锯齿的结果图,然后在图像上进行反走样处理
- 最流行的方法:SMAA(Enhanced subpixelmorphological AA)
- 发展历史:FXAA \(\to\) MLAA(Morphological AA)\(\to\) SMAA
SMAA
- http://www.iryoku.com/smaa/
- 先检测出来边界,然后根据找出来的边界,根据占比上色
- 矢量化的过程
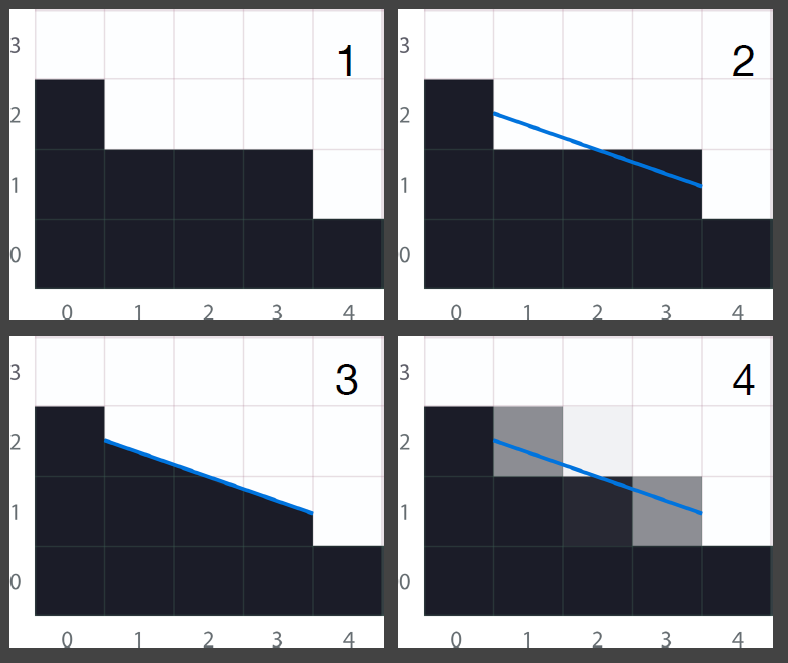
- 效果非常快
- 不能对 G-Buffer 做反走样,反走样了则失去了原来的意义
Temporal Super Resolution
- 超分辨率:Super Resolution(Super Sampling)
- 字面理解:提高分辨率
DLSS
- Nvidia
- DLSS
1.0:硬猜,通过神经网络学习到一些结果,将模糊的边缘换成不模糊的边缘
- 完全数据驱动
- DLSS 2.0:使用更多 Temporal 的信息
- 分辨率提高,变模糊,等价于是采样不足,试从上一帧中获取信息
- 核心思想就是利用 TAA
- Temporally reuse samples to increase resolution
- DLSS 面临的另外一个问题,如果时间的信息不可用,不能使用 clamping
的方法
- 对 temporal 的信息利用更加严格
- 我们实际上需要的是一个增大了分辨率的结果,我们需要知道一些更细致分辨率的值,如果我们不能够在时间上获取到这些信息,盲目的使用周围的值去猜,这样会导致模糊的结果
- 也就是说新的值和原来的值本质上是不同的,更细致的分辨率有更多细节
- 因此我们需要找一个比 clamp 更好的方案(当 temporal failure 的时候)
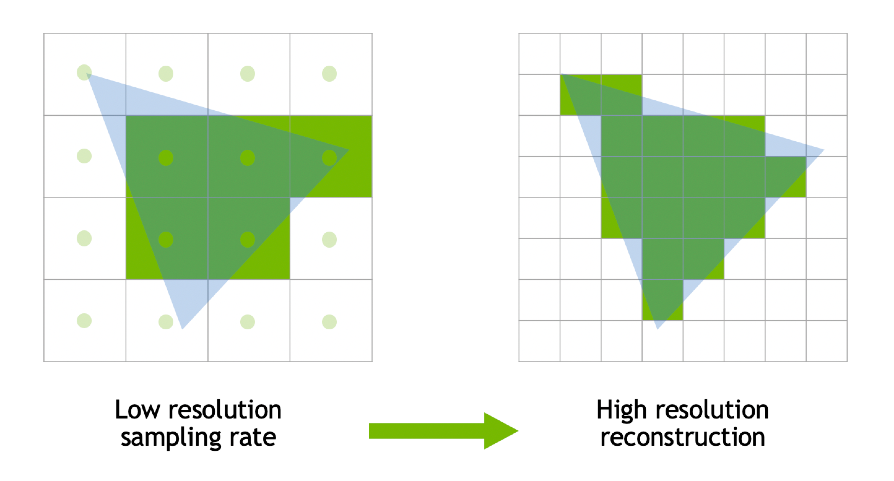
- 当前帧和上一帧的采样信号 \(\to\)
得到一个当前帧增加了采样点的值
- DLSS 的网络没有输出具体的颜色值,而是告诉我们应该怎么去使用上一帧的信息
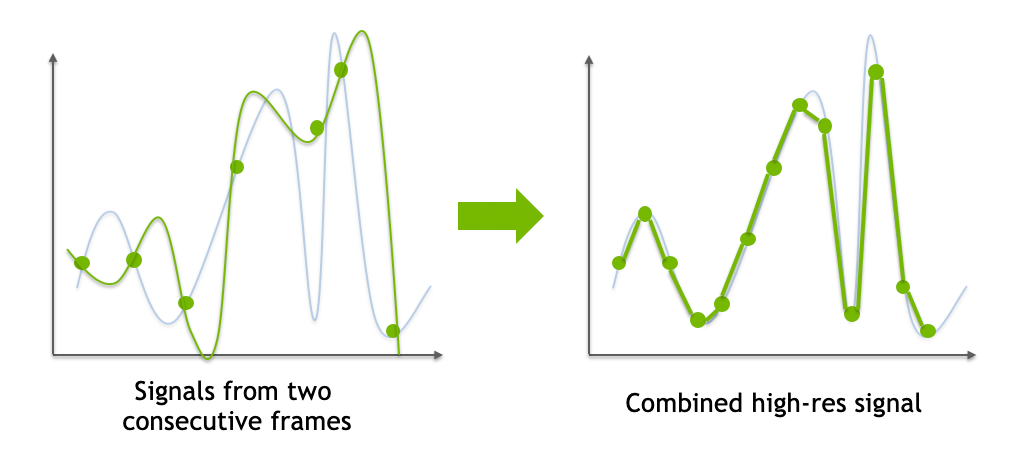
效果对比
- 540p Bicubic Upsampled to 1080p

- 540p to 1080p DLSS2.0

- 1080p with TAA

- DLSS 2.0 的效果可能更加锐利,因为 Temporal 的复用可能提高的分辨率不止 2x
其他
- DLSS 网络跑得快,具体怎么实现不清楚
- Network inference performance optimization (classified)
- AMD 也有 DLSS
- AMD:FidelityFX Super Resolution
- 同样性能的 CPU,AMD 的价格大概在 Nvidia 的一半价格
- Facebook:Neural Supersampling for Real-time Rendering [Xiao et al.]
- 效果不太好,实现上更像 DLSS 1.0,工业界不好用
避免没有意义的 shading
Deferred Shading
- 延迟渲染
- 让 shading 变得更加高效,速度更快
- 传统的光栅化渲染管线
- Triangles -> fragments -> depth test -> shade -> pixel
- 延迟渲染的想法
- 在传统的光栅化渲染管线下,只有对视点可见的点的 shading 才是真正有效的,其他点的渲染本质上都是是无用功
- 最坏的情况
- 对于每一个 fragment,都是从远到近渲染的,这样做了很多无用功
- 这样每一个点都得做 shading
- 复杂度:O(#fragment \(\times\) #light)
- 延迟渲染的基本想法
- 大部分的 fragment 在最终的 image 中是不可见的
- 我们只需要渲染在最终的 image 中可见的 fragment
思路
- 光栅化两次
- 第一次光栅化
- 只生成 depth-buffer
- 不做 shading
- 第二次光栅化
- 给通过深度测试的 fragment 进行 shading
- 因为对于每一个像素,能够通过深度测试的 fragment 只会有 1 个
- 延迟渲染的基本想法
- 一次光栅化的开销比对大量不必要点的 shading 计算开销要小
- assume rasterizing the scene is way faster than shading all unseen fragments (usually true)
- 复杂度:O(#vis. fragment \(\times\) #light)
- 问题
- 我们做不了 AA(G-Buffer 不能做 AA)
- 但是可以通过 TAA 或者图像空间上的 AA,AA 的问题能够被很好的解决
- 因此延迟渲染成为工业界的标配
Tiled Shading
- 优化光源
- 把屏幕切分为若干个 tile(大概每个 \(32\times32\)),每个小块单独做 shading
- 这样子的方法可以减少每一个小块需要考虑的光源数目
- 如下是 frustum 的俯视图
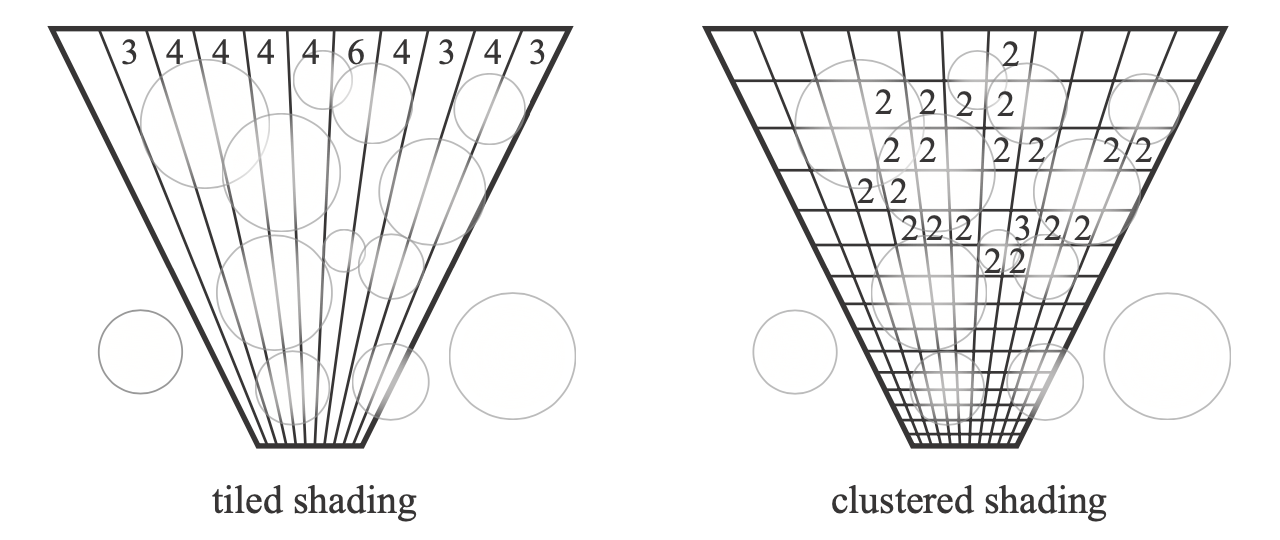
- 对于每一个小条,不是所有光源都会影响到它
- 光源的平方衰减
- 上面的圆圈表示每一个光源的覆盖范围(球投影成圆)
- 上面的数字表示影响到这个光源的光源个数
- 光源的平方衰减
- 复杂度:O(#vis. frag. \(\times\) avg #light per tile)
Clustered shading
- 想法和 tiled shading 类似
- 深度上也切片
- 一个格子可能包含多个像素,前面可能不会把后面整个各自都遮挡住
Level of Detail
- LoD
- 例如 mipmap 就是一个 level of detail
- 在具体使用的时候,选择正确的层级去使用,这样能够节省计算的效率
- RTR 工业界中把这种在对不同层级细节的使用称为 cascaded
- shadow map 可以用来做 LoD
Cascaded Shadow Map
- [Dimitrov et al., Cascaded Shadow Maps]
- 离视点近的物体使用高分辨率的 SM,离视点远的物体使用低分辨率的 SM
- 下图中,三角形为 frustum,红色使用高分辨率 SM,蓝色使用低分辨率 SM
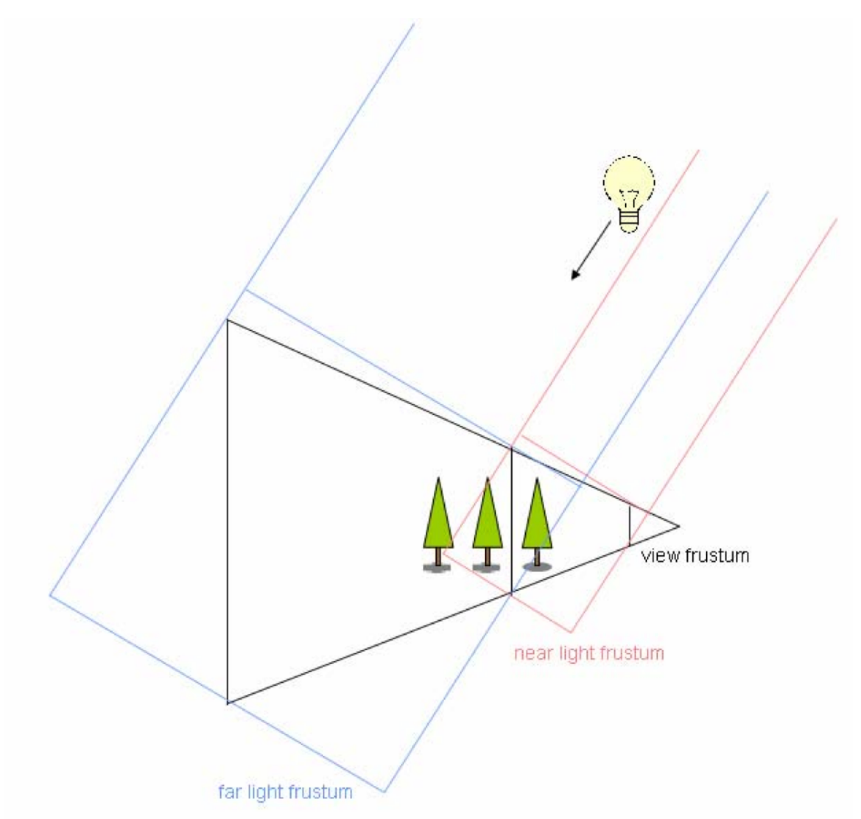
- 实际应用中我们很难生成一张变分辨率的 SM,因此实际应用会生成多张不同分辨率的 SM
- 针对不同距离,我们使用不同分辨率的 SM
- 范围会有一些重叠
- 保证切换 SM 时能够平滑过渡
- 重叠区域使用两个 SM 混合的效果
Cascaded LPV
- [Anton Kaplanyan, Light Propagation Volumes in CryEngine 3]
- 近处比较小,远处比较大
Geometric LoD
- 高模(三角形多的模型)、低模(三角形少的模型)
- 预先生成一系列的不同三角形数的模型
- 可以对一个物体的不同部分使用不同精细程度的模型细节
- UE5 的 Nanite 就是利用这些原理实现
- 对于引擎来说,技术实现是难点
Cascaded 的问题
- 在不同层级之间切换的时候可能会有问题(popping artifactss)
- 通常的方法可以在边界的地方使用 blending 的方法
- Popping artifacts
- TAA 处理(复用上一帧的信息)
引擎实现的难点
- 一个物体的不同部分使用不同层级的 LoD,怎么保证相接的地方是没有缝的?
- 如何动态加载和调度不同层级的资源?
- GPU 容量有限
- Representing geometry using triangles or geometry textures?
- 怎么表示几何形体?三角形?几何纹理?
- 引擎实现的加速
- clipping 裁剪
- culling 剔除(背面剔除)
全局光照的解决方法
- SSR 屏幕空间光线跟踪
- 没有一种简单的 GI 方法能够解决所有的场景
- RTRT可以,但是现在还是太慢了
- 工业界经常把多种方法混合起来使用
- 一个 GI 的解决方案
- SSR 得到近似的 GI
- 对于 SSR 失败的地方,是用其他方式补充
- hardware (RTRT) or software ray tracing
- 软件光追
- HQ SDF for individual objects that are
close-by
- 高质量的有向距离场
- LQ SDF for the entire scene
- RSM if there are strong directional / point
lights
- 手电筒
- Dynamic Diffuse GI(DDGI)
- Probes that stores irradiance in a 3D grid
- 利用这些探针去照亮整个场景
- HQ SDF for individual objects that are
close-by
- 硬件光追
- Doesn’t have to use the original geometry,
but low-poly proxies
- 使用简化的模型
- Probes(RTXGI)
- Doesn’t have to use the original geometry,
but low-poly proxies
- 以上红色部分是 UE5 的 Lumen 实现
课程没有涉及的部分
- Texturing an SDF
- Transparent material and order-independent transparency
- Particle rendering
- Post processing (depth of field, motion blur, etc.)
- Random seed and blue noise
- 蓝噪声:
- Foveated rendering
- 注视点投入更多渲染的算力
- Probe based global illumination
- ReSTIR, Neural Radiance Caching, etc.
- Many-light theory and light cuts
- Participating media, SSSSS
- 参与介质
- 次表面散射
- Hair appearance
- ......
