数据库概论.陈立军.07.并发控制(3)
并发控制
锁的实现
- 锁管理器、锁表
- 锁管理器
- 事务向锁管理器发送封锁请求和释放请求
- 锁管理器维护一个锁表记录锁的授予情况和处于等待状态的封锁请求
- 锁表
- 锁表一般作为内存中的 hash 表,按被封锁对象的名字建立索引
锁表结构
- 内存中的哈希表
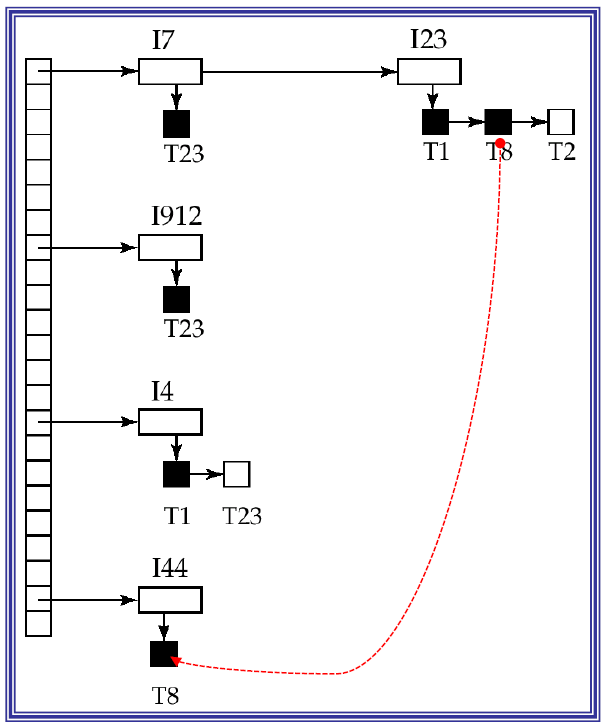
- 黑矩形表示已被授予的锁,白色表示等待的封锁请求
- 锁表同时记录锁的类型
- 需要检查锁是否想容
- 新的封锁请求加到对应请求队列的末尾,当封锁请求与前面的锁相容时被批准
- 释放封锁时请求从队列中删除并检查后续请求是否满足
- 如果事务放弃,所有授予的和等待的锁请求都被删除
- 为提高效率,锁管理器会记录每个事务持有锁的情况
- 红线:把一个事务所有的锁串成一个链
- 封锁资源如下
- 但是锁管理器对资源一无所知,它只是 ”memcmp()”
- 锁管理器不需要去区分被锁的是什么逻辑单元,只需要将这个字符串锁起来即可

锁升级(SQL Server)
- 这里的锁升级不是强度上的升级(读锁升级为写锁),而是粒度上的升级(行锁升级为表锁)
- 行锁太多的时候,我们可以把这些行锁升级为表锁
- 封锁开销与并发度的 trade off
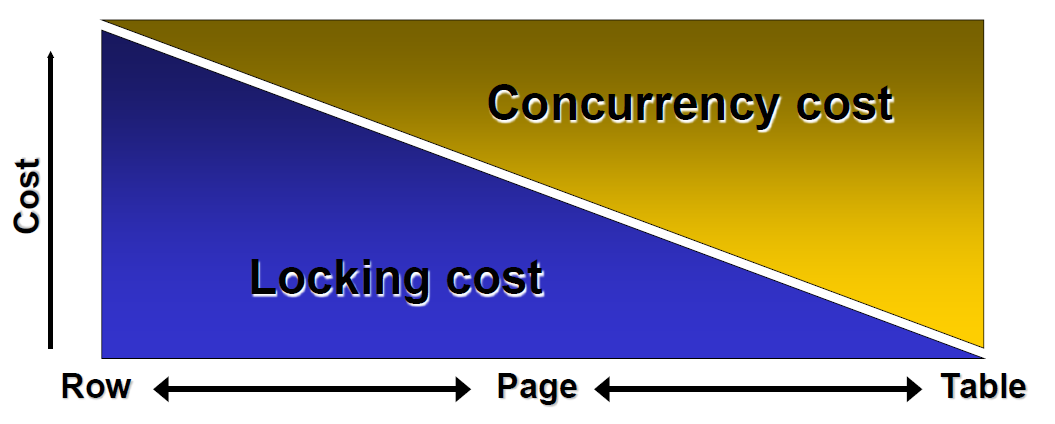
- 行锁代价高、并发度高
- 表锁代价低、并发度低
锁升级的定义与操作
- 锁升级是将众多细粒度锁转换为较少的粗粒度的锁的过程,以削减系统开销
- 当事务超过它的升级极限时,系统自动将行锁和页锁升级为表锁
- 当事务从表中请求行时,系统获取相应行上的锁,并在包含这些行的页和表上放置意向锁。当事务控制的锁数量超过其极限时,系统将表上的意向锁更改为更强的锁(如将IX锁更改为X锁),释放事务持有的所有页级锁和行级锁,从而削减锁的开销。
MySQL 没有锁升级
- InnoDB 不存在锁升级的问题
- InnoDB 不是根据每个记录来产生行锁,而是根据页进行加锁,并采用位图方式定位到行,锁住页中一个记录还是多个记录,其开销是一样的
开销对比
- 假设一张表有 \(3\times10^6\) 个数据页,每个页大约有 \(100\) 条记录,那么总共有 \(3\times10^8\) 条记录。
- 若有一个事务执行全表更新的 SQL 语句,则需要对所有记录加 X 锁
- 若根据每行记录产生锁对象进行加锁,并且每个锁占用 \(10\) 字节,则仅对锁管理就需要差不多需要 \(3\mathrm{GB}\) 的内存
- 而 InnoDB
存储引擎根据页进行加锁,并采用位图方式,假设每个页存储的锁信息占用 \(30\) 个字节,则锁对象仅需 \(90\mathrm{MB}\) 的内存
- \(30\) 字节:位图 \(\dfrac{100}{8}=12.5\),加上一些其他信息
- 由此可见两者对于锁资源开销的差距之大
封锁带来的问题
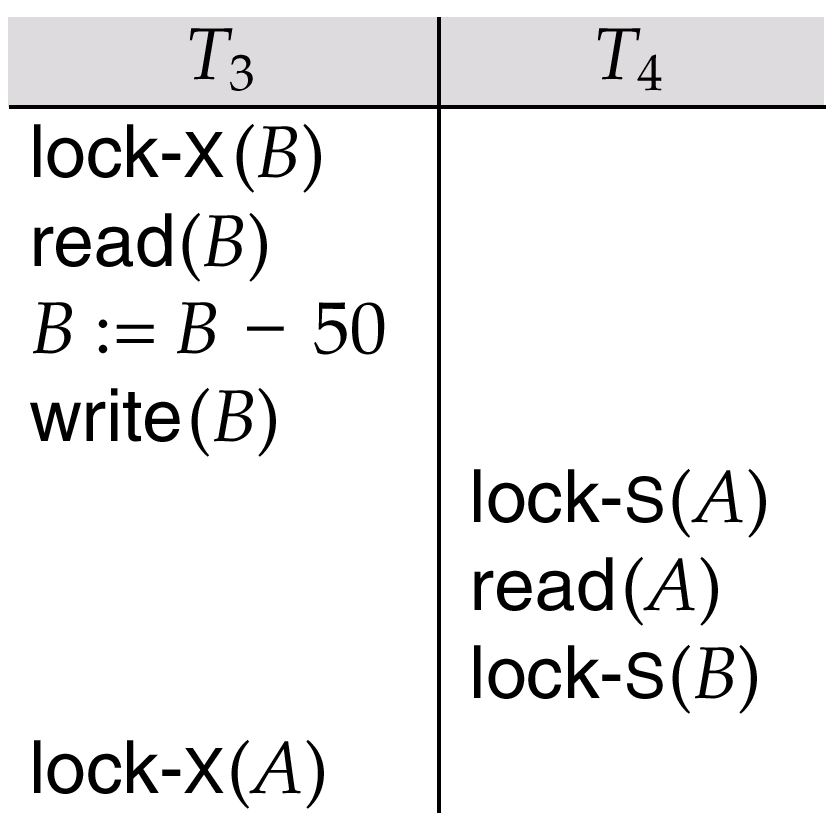
死锁(Deadlock)
- 两个事务都封锁了一些数据对象,并相互等待对方释放另一些数据对象以便对其封锁,结果两个事务都不能结束,则发生死锁
- 死锁发生的条件(4)
- 互斥条件:事务请求对资源的独占控制
- 占有等待条件:事务已持有一定资源,又去申请并等待其它资源
- 非抢占条件:直到资源被持有它的事务释放之前,不能将该资源强制从持有它的事务夺去
- 循环等待条件:存在事务相互等待的等待圈
- 定理:在条件 (1)(2)(3) 成立的前提下,条件 (4) 是死锁存在的充分必要条件
一个例子
| 事务号 | 占有资源号 | 请求资源号 |
|---|---|---|
| T1 | R1 | R2 |
| T2 | R3 | R1,R2 |
| T3 | R2 | R3 |
graph LR; T1[T1]--->T3[T3] T2--->T1 T2--->T3 T3--->T2
- 在数据库中定期扫描锁表,如果发现死锁,则破坏第 3
个条件(回滚某个事务)
- 系统同时会向这个事务发送一个信号
- SQL Server:1205
循环死锁例子
| 事务1 | 事务2 |
|---|---|
| begin tran update S set sname= '张三' where sno= ' S1' |
|
| begin tran update C set cname= '数据库基础' where cno= ' c1' |
|
| update C set cname= '数据库教程' WHERE cno= ' c1' commit tran |
|
| update S set sname= '李四' where sno= ' S1' commit tran |
转换死锁例子
1 | set transaction isolation level repeatable read |
两个事务都执行如上代码,都是先读后写,死锁
解决方案
- 调整事务的隔离性级别
- 强制 SQL Server 使用更新锁
1
SELECT * FROM S (UPDLOCK)
因缺少索引而导致死锁
- 扫描全表导致的相互阻塞
- 可以通过显示锁表展示死锁信息
| 事务1 | 事务2 |
|---|---|
| begin tran update T1 set col1 = 'a' where id = 101 |
|
| begin tran update T2 set col2 = 'a' where id = 201 |
|
| select col2 from T2 where id = 203 |
|
| select col1 from T1 where id = 103 |
预防死锁
破坏占有等待条件
- 死锁根源:T1 持有 R1,申请 R2;T2 持有 R2,申请 R1
- 预先占据所需的全部资源
- 要么一次全部封锁,要么全不封锁
- 缺点:难于预知需要封锁哪些数据并且数据使用率低
- 所有资源预先排序,事务按规定顺序封锁数据
- 按照相同的资源顺序获取锁
- 不允许 T3 在没有获得资源 R1 时就去获取 R3

破坏非抢占条件
- 人为规定一个优先级,将非抢占式转化为抢占式
- 使用抢占与事务回滚
- 规定老事务优先级高于新事务
- 下图为例,不允许两个箭头同时出现即可
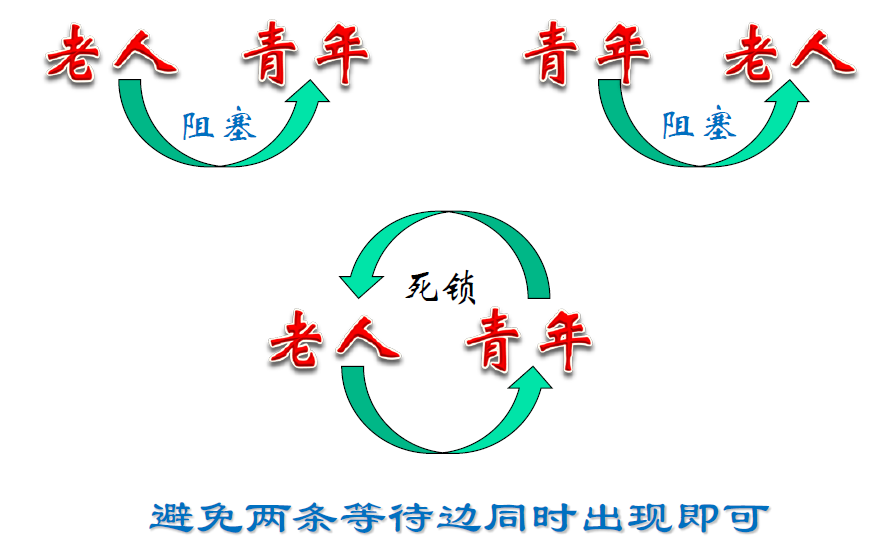
- 死锁序列
- start(T1), start(T2), w1(R1), w2(R2), r1(R2), r2(R1)
- 注意以下两种策略,在任何时候都是回滚优先级低的新事物
- 策略1:wait-die
- 如果 T1 等待 T2,仅当 T1 的时间戳小于 T2 时,允许 T1 等待,否则回滚 T1
- 执行结果:r2(R1) 时触发,回滚 T2

- 策略2:wound-wait
- 如果 T1 等待 T2,仅当 T1 的时间戳大于 T2 时,允许 T1 等待,否则回滚 T2
- r1(R2) 时触发,回滚 T2

- 在实际数据库中以上的预防方法都不适用,一般都是通过死锁检测找到死锁,然后接触死锁
- 超时法:如果等待封锁的时间超过限时,则撤消该事务
- 等待图法:LOCK_MONITOR
活锁(live lock)
- 可能存在某个事务永远处于等待状态,得不到执行,称之为活锁(饿死)
- 饥饿例子:读者优先策略
- T2 持有对 R 的 S 锁,T1 申请对 R 的 X 锁,则 T1 必须等待 T2 释放 S 锁;若在 T2 完成之前有 T3 申请对 R 的 S 锁,则可以获得授权封锁,于是 T1 必须等待 T2、T3 释放 S 锁
- 避免活锁的策略是遵从“先来先服务”
的原则,按请求封锁的顺序对各事务排队
- 降低了系统的并发度(总吞吐量)
- 先来先服务
- 当事务 Ti 对数据项 R 加 M 型锁时,获得封锁的条件是
- 不存在在 R 上持有与 M 型锁冲突的锁的其他事务
- 不存在等待对 R 加锁且先于 Ti 申请加锁的事务
- 当事务 Ti 对数据项 R 加 M 型锁时,获得封锁的条件是
使用绑定连接
- 一个事务对应多个连接的需求
- 绑定连接
- 绑定连接允许两个或多个连接共享同一个事务和锁定
- 绑定连接可以对同一个数据进行操作,而不会有锁冲突
- 把不同的连接上的操作绑定在同一个事务中
- sp_getbindtoken:返回事务的唯一标识符,将其作为绑定令牌
- sp_bindsession:绑定与同一 SQL Server 实例中的其它事务的连接
锁定提示
- 一般而言,操作加的锁是由数据库系统本身决定的,但是我们可以添加一些要求加什么锁的提示
1 | select ... from table_name[with (lock hint)] |
| holdlock | readuncommitted |
| updlock | readcommitted |
| xlock | repeatableread |
| tablock | serializable |
| paglock | readcommittedlock |
| tablockx | nolock |
| rowlock | readpast |