xv6-labs-2020.lab8.file system
lab8 file system
1. 作业链接
- https://pdos.csail.mit.edu/6.828/2020/labs/fs.html
2. 实习内容
2.1 Large files
(1) 目标与描述
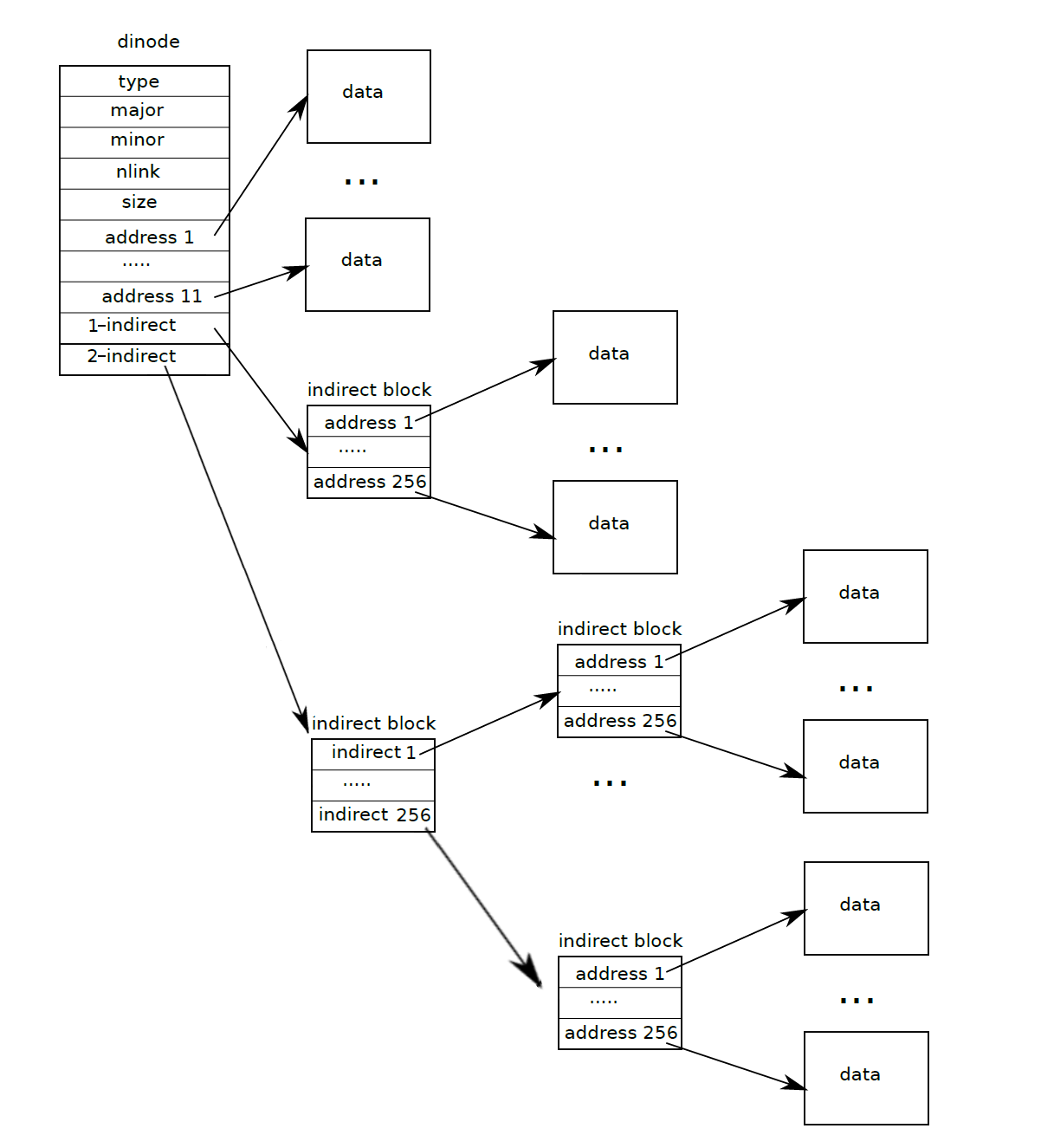
- xv6 的一个文件有 13 个数据项,前 12 个数据项直接索引到数据块,第 13
个数据项通过一级索引索引到数据块(先找到索引表,通过索引表找到数据块地址)
- 一个数据项大小为 \(4\) 字节,一个块的大小为 \(1024\) 字节,因此一个块中最多可以放 \(\dfrac{1024}{4}=256\) 个数据项
- 因此支持的的文件最大为 \(12+256=268\) 块
- 我们的目标是让 xv6 支持更大的文件,我们增加一个二级索引
- 前 11 个数据项直接索引,第 12 个数据项一级索引,第 13 个数据项二级索引
- 这样支持的最大文件为 \(11+256+256\times256=65803\)
- 注意文件系统的每次修改代码都需要
make clean,否则fs.img中文件系统会出问题- 或者删除文件
fs.img
- 或者删除文件
(2) 提示
fs.c中的bmap()函数建立起对数据块的索引- 读操作如果没找到数据块,则报错返回
- 写操作如果没找到,则需要分配一块
- bmap() 中的参数
bn是逻辑序号(文件内从 0 开始标的序号)
(3) 实现
[1] 修改宏
1 | // kernel/fs.h |
- 注意所有的原来相关引用必须正确
- NINDIRECT
- mkfs/mkfs.c:iappend() 正确
- NDIRECT
- NINDIRECT
1 | // kernel/file.h |
1 | // kernel/fs.h |
[2] 二级索引表
- 以下的代码修改都是
kernel/fs.c - 可以
ctrl-f找找需要修改的地方(addr) - 修改 bmap(),建立起新的映射关系
- 判断如果是二级索引的话,需要先读入二级索引表,再读入一级索引表,最后读入数据块地址
- 最后需要释放二级索引表
- 注意修改了内容就需要调用 log_write() 写到磁盘(write through)
1 | static uint bmap(struct inode *ip, uint bn) { |
- itrunc() 丢弃 inode 的时候需要回收所有的数据块
1 | void itrunc(struct inode *ip) { |
2.2 Symbolic links
(1) 目标与描述
- 实现软链接
1 | void symlink(char *target, char *path); |
- 软链接可以跨盘,硬链接不能跨盘
(2) 提示
- 一部分提示(准备工作)放在实现中
symlink(target, path)的 target 不存在也能成功- 你需要有一个地方保存 target 位置,可以保存在 inode 的数据块中
- 需要有返回值,0 成功,-1 失败(和 link/unlink 一致)
- 修改系统调用 open() 实现对软链接文件的处理
- 如果文件不存在,则 open 失败
- 如果文件打开的 flag 中有
O_NOFOLLOW,则不需要打开软链接对应的文件
- 如果软链接文件对应的文件还是软链接文件,需要递归打开,直至找到一个不是软链接的文件
- 如果成环,则需要报错(简单使用一个递归深度阈值判断即可,10)
- 其他系统调用(例如链接和取消链接)不需要打开到软链接最终链接的文件,只需要打开软链接文件本身即可
- 不需要处理软链接指向文件夹的情况
- 不允许指向文件夹
(3) 实现
[1] 添加一个新的系统调用 symlink
Makefile
1 | ifeq ($(LAB),fs) |
user/usys.pl
1 | entry("symlink"); |
user/user.h
1 | int symlink(const char *, const char*); |
kernel/sysfile.c
1 | uint64 sys_symlink (void){ |
kernel/syscall.c
1 | extern uint64 sys_symlink(void); |
kernel/syscall.h
1 |
kernel/stat.h中添加文件类型,表示软链接(symbolic link)
1 |
kernel/fcntl.h添加新的 flag,用于 open 系统调用,注意文件打开的 flag 是是使用 or 进行组合的,因此不能和已有的 flag 重合
1 |
[2] sys_symlink() 具体实现
- 注意一些小问题即可
- symlink 的 path 是可以存在的,测试数据中那个有这样的内容
- 这个人感觉很不合理
- 没有做一些其他的处理,例如释放原来的文件数据块(感觉应该是要做,但是在这个lab中没有实现)
- namei() 返回 ip 不为 0 的情况下,ip 是不带锁,但是引用计数+1
- 因此需要注意 iput() 的调用
- 将 target 保存在 data 段的开始
- symlink 的 path 是可以存在的,测试数据中那个有这样的内容
1 | // 仿照 sys_link 实现即可 |
[3] sys_open() 的实现
- 在打开文件的时候进行一个判断,如果是软链接同时没有
O_NOFOLLOWflag 的话,就打开软链接对应的文件即可
1 | uint64 sys_open(void) { |
- namei_check_symlink() 如下
- 显式的递归深度检测
- 注意细节 iput(),因为切换到下一个文件,因此将引用计数-1
- 读取 target 的时候,注意是在 data 段的开头
1 | // 返回如果不为 0, 计数 +1 |
3. 实验结果
- bigfile 和 usertests 不能在规定时间内完成任务(电脑性能问题)
- 修改了 timeout
1 |
|
1 | $ make qemu-gdb |
4. 遇到的困难以及收获
- 第一部分修改宏的时候,没有把所有引用宏的地方都对应上,因此报了奇怪的错误
1 | panic : virtio_disk_intr status |
- 以后得注意,在修改已有代码段的时候,需要注意所有引用在修改后还是正确的
- 文件系统的设计确实很巧妙,函数之间的相互调用需要符合一定的规范
- 例如引用计数以及锁的设计,感觉都得好好思考才能做出答案
- 感觉 symlink 的 path 可以存在这个设定确实不太合理
5. 对课程或 lab 的意见和建议
- 建议提供一些关于 lab 的 debug 功能的指导
6. 参考文献
- https://pdos.csail.mit.edu/6.828/2019/xv6/book-riscv-rev1.pdf