XV6 源代码阅读——文件系统
说明
阅读的代码是 xv6-riscv 版本的
涉及到的文件如下
kernel
buf.h、bio.c、param.h、log.c、fs.h、file.h、file.c、fs.c、stat.h、fcntl.h、sysfile.c、ide.c
阅读笔记
这一部分为阅读 book-riscv-rec1 的笔记
文件系统的目标
文件系统需要解决的几个问题
需要有一个保存在磁盘上的数据结构,保存文件的结构信息、文件本身、空闲的磁盘区域
需要支持故障重启(crash recovery)
多进程的并发访问
磁盘访问是慢速的,需要维护一个 cache,保存经常访问的块
七层结构
File Discriptor
Pathname
Directory
Inode
Logging
Buffer cache
Disk
disk 层从一个虚拟硬盘(vitro hard drive)上读取 block
buffer cache 层缓存 block
保证同一个 block 只能被一个内核进程同时访问
logging 层记录一些日志信息,用于出错恢复
inode 层是一个独立的文件,唯一的 i-number 和一些存储数据的块
directory 层把文件夹封装称为一些特殊的 inode
内容为一些列目录项,包括文件名和 i-number
pathname 层提供一个层次化的树结构,处理了递归包含的情况
file descriptor 层把 pipes, devices, files
等都抽象为文件,使用统一的文件系统的接口
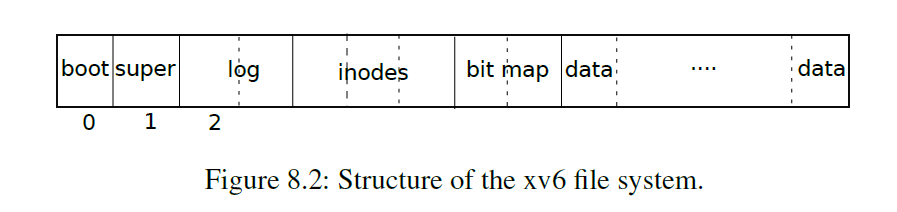
物理存放结构
第 0 块保留,用于存储引导扇区
第 1
块为超级块(superblock),保存着文件系统的元数据、一些用于构建初始操作系统的代码(称为
mkfs)
元数据
文件系统的大小(多少块)
数据有多少块
inode 有多少个
log 占多少块
从第 2 块开始,保存 log 信息
大小为 LOGSIZE+1=(MAXOPBLOCKS*3)+1=31
接下来是 inode(每个块有多个 inode)
接着是 bitmap blocks,用来保存那些块是被使用或空闲的
最后是数据块(要么是文件夹或文件,要么在 bitmap 中标记为空闲)
Buffer cache 层
两个目标
同步磁盘块,保证每个磁盘块在内存中最多只有一个拷贝,保证每一个磁盘块的拷贝只能被一个内核线程使用
缓存 popular blocks,减少访问磁盘导致的开销
对上提供的接口如下
bread():获取一个磁盘块的拷贝到内存中
bwrite():将缓存写入磁盘的对应块中
brelse():释放缓存块(用完必须得释放 )
通过给每一个 buffer 分配一个 sleeplock
的方式实现一个磁盘块的拷贝只能被一个内核线程使用
bread() 返回一个带锁的 buffer
brelse() 释放锁
当需要的磁盘块没有读入内存的时候,通过 LRU 的方式回收一个
buffer,并从磁盘中将对应块读入内存
通过 virtio_disk_rw(b, 0) 实现
Buffer cache 层(代码实现)
kernel/bio.c一共有 30 个 buffer
通过 binit() 将,所有的 buffer 保存为一个静态的数组
组织成一个双向循环链表(为了实现 LRU 的替换算法)
为了方便组织,这个双向链表带一个空的虚拟头结点
1 2 3 4 5 6 struct { struct spinlock lock ; struct buf buf [NBUF ]; struct buf head ; } bcache;
每一个 buffer 的数据结构如下
valid 字段表示这个 buffer 是否对应磁盘上的某一个块(1
表示有对应)
disk 字段表示是否将 buffer 中的信息写回了磁盘上(1
表示修改了未写回)
1 2 3 4 5 6 7 8 9 10 11 12 struct buf { int valid; int disk; uint dev; uint blockno; struct sleeplock lock ; uint refcnt; struct buf *prev ; struct buf *next ; uchar data[BSIZE]; };
bread() 函数调用 bget() 获取一个 buffer
如果返回一个 valid=1 的 buffer,说明待读取的 buffer
已经在内存中了
如果返回一个 valid=0 的 buffer,说明待读取的 buffer
尚未进入内存,通过调用 virtio_disk_rw(b, 0)
从磁盘中将其读入内存(buffer 中)
bget() 的逻辑如下
首先扫描整个链表,看需要读取的内容是否被缓存,若缓存了,直接返回
若未缓存,从链表开始扫描,找到一个空闲的 buffer(refcnt=0) 返回
注意此时需要把 valid 项置为 0,表明需要从磁盘中读取具体的内容
如果还没找到,则报错 panic()
注意返回的 buffer 是带锁的
bget() 的整个过程都是持有锁 bcache.lock
的,因此保证了每一个磁盘块在 buffer 中最多只会有一个拷贝
如果修改了 buffer 中的内容,需要调用 bwrite()
将内容写回磁盘,内部调用 virtio_disk_rw(b, 1) 实现
最终需要调用 brelse() 进行释放缓存块,将 refcnt 减 1,同时得释放
buffer 上的锁
如果 refcnt 为 0,将这个 buffer 插入到链表头的后面
这就保证了 LRU
的实现,在逆向查找,找到的第一个空闲块一定是最老的
logging 层
这一部分的设计主要是为了处理故障恢复的问题
例如在一个操作执行到一半的时候发生了故障,此时可能出现磁盘内容不一致的情况
当需要向磁盘写入内容的时候,xv6
先向磁盘上写一个日志记录,当把所有的写操作都计入日志之后,写一个 commit
表示日志记录完整,此时再进行系统调用将内容写入磁盘,当内容都写完之后,在磁盘上消去这个日志信息
系统崩溃重启之后的流程如下
检查日志记录,如果有完整的操作,那么就执行,如果操作不完整,则直接忽略
日志记录保证了这个操作是原子的(全或无)
log 的设计
log 在磁盘中的位置是确定的,在 superblock 中能够找到
由一个头块(header block)和一些更新的块(logged blocks)组成
header block
一个扇区编号的数组
对应扇区磁盘内容写入下标+1 所在的 log
块中,具体见下面的代码
日志块的个数
header block 占据一个块的大小,具体在 initlog() 有检查
计数要么为
0(没有需要处理的记录),要么非零(表示存在一个事务,即一组待处理的写操作)
一个事务可能包含一组系统调用,为了避免一个有关文件系统的系统调用被拆分为多个事务,因此
commit 只在没有有关文件系统的系统调用出现时进行
在日志处理中,log
块的空间是固定的,因此如果需要写的内容太多的话会出问题
两个系统调用 write、unlink 写的内容可能会过大
xv6
的实现可以把一个很多块的写操作拆分为若干个较少块的写操作,解决上述问题
如果一个有关文件系统的系统调用写的内容超过了 log
区域中剩余块的大小,此时这个系统调用不会被执行
logging 层(代码实现)
kernel/log.c一个典型的在系统调用中使用 log 机制的方式如下
1 2 3 4 5 6 7 begin_op(); ... bp = bread(...); bp->data[...] = ...; log_write(bp); ... end_op();
begin_op()
等待,直到 log 系统没有 committing 而且有充足的 log blocks
xv6 认为每个系统调用只会使用 MAXOPBLOCKS(10) 个 block
满足条件后,系统调用数 +1 并返回
log.outstanding 记录使用 log 系统的系统调用数
log_write()
把 buffer 的磁盘块号保存到 log 中,同时做一个优化(absorbtion)
找到一个同一磁盘块的拷贝时,用新的修改覆盖它即可(直接说使用原来留下的
slot)
同时把 buffer 的 refcnt +1(避免被替换出去)
end_op()
首先将计数 log.outstanding -1(系统调用数 -1)
如果此时计数变成 0,则调用 commit() 进行 commit
commit()
1 2 3 4 5 6 7 8 9 10 static void commit () { if (log .lh.n > 0 ) { write_log(); write_head(); install_trans(0 ); log .lh.n = 0 ; write_head(); } }
write_log():把具体的内容写入 log 对应的磁盘块里
通过调用 bread() 读取磁盘块、memmove() 内存复制、bwrite()
写入磁盘完成
需要写入的磁盘区域 \(\to\) 对应的
log 块
代码如下 ,注意这里的 log
数组中记录的磁盘块写入对应下标+1 的 log
块中,因为第一块留给了 log 的 head
1 2 3 4 5 6 7 8 9 10 11 12 static void write_log (void ) { int tail; for (tail = 0 ; tail < log .lh.n; tail++) { struct buf *to =log .dev, log .start+tail+1 ); struct buf *from =log .dev, log .lh.block[tail]); memmove(to->data, from->data, BSIZE); bwrite(to); brelse(from); brelse(to); } }
write_head():把 log 块的头信息写入磁盘
log 块区域的第一块是 log 的 header 块
这一个区域完成之后就实现了 commit()
的功能,就来来执行真正的写操作
install_trans():执行原来要求的写操作
通过调用 bread() 读取磁盘块、memmove() 内存复制、bwrite()
写入磁盘完成
对应的 log 块 \(\to\)
需要写入的磁盘区域
write_head():将磁盘块中的头信息清空(将计数归零)
recover_from_log()
1 2 3 4 5 6 7 static void recover_from_log (void ) { read_head(); install_trans(1 ); log .lh.n = 0 ; write_head(); }
这部分代码会在系统启动的时候调用
fsinit() \(\to\) initlog() \(\to\) recover_from_log()
注意这里的 install_trans() 的参数 1
因为如果不是恢复,log_write()
的操作为了不让墓表块释放,因此会将引用计数+1,此时在 install_trans()
中需要 -1,但是在恢复的时候没有进行这个操作,所以不需要 -1
一个例子
file.c 的 filewrite() 表示一个例子
注意这里为了避免文件一次写的太大,把文件拆分为多个写操作
块分配器(bitmap)
通过 bitmap 记录一个磁盘块是否空闲(0 表示空闲)
在系统启动的时候,mkfs 代码会将 boot
sector、superblock、log blocks、inode blocks、bitmap 对应在 bitmap
中的值设置为 1
代码:kernel/fs.c
balloc() 函数从磁盘中找一个空闲的磁盘块并返回(bitmap 中标记为
0)
bfree() 函数释放一个指定的磁盘块
读取 bitmap 的块
1 bp = bread(dev, BBLOCK(b, sb));
bitmap 只能被一个进程同时访问
因为在最后需要调用
brelse()/bread(),这已经隐式加上了锁,所以不需要对 bitmap 显式加锁
Inode 层
两种含义
磁盘上的数据结构(on-disk),包含文件的大小和一个数据存放位置的列表
内存中的数据结构(in-memory),包括磁盘上数据结构的一个拷贝以及一些内核需要用到的内容
on-disk
磁盘上的 inode 被放置在 inode blocks 中,大小都是相同的,给定一个
n(i-number)就能找到第 n 个 inode 的位置
数据结构如下
type:file、directory、special files(devices)、0(表示空闲)
nlink:引用数(用于判断数据块是否该被释放)
size:文件所占据的字节数
addrs:文件所在数据块的地址
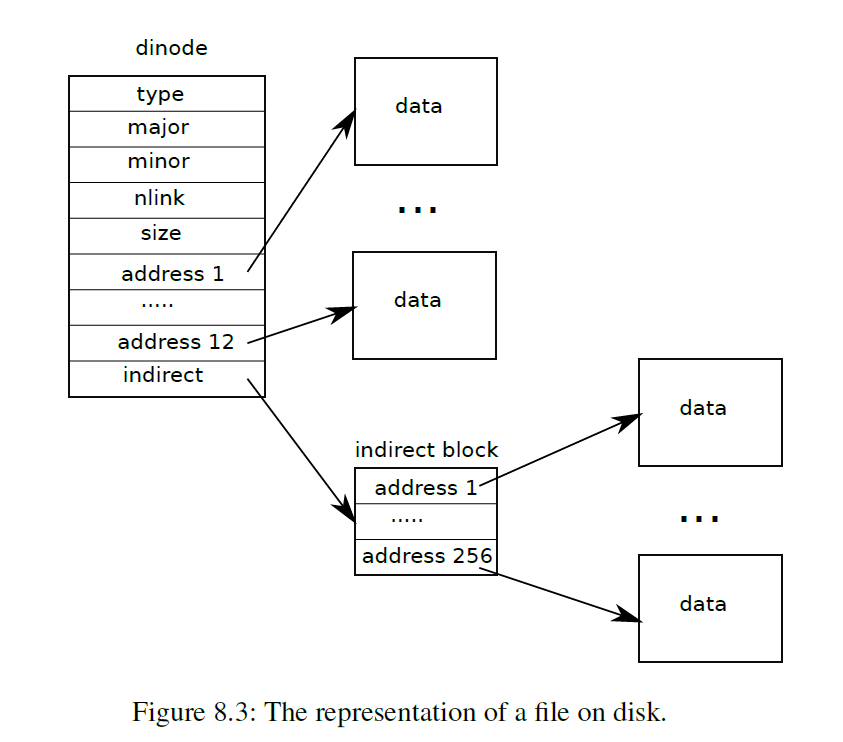
1 2 3 4 5 6 7 8 9 10 struct dinode { short type; short major; short minor; short nlink; uint size; uint addrs[NDIRECT+1 ]; };
in-memory
数据结构如下,除了上面的 dinode 之外还有一些其他的字段
ref 记录引用数(用于判断这个数据结构是否该被释放)
iget()、iput() 增加和减少引用数
引用来源:文件描述符、当前工作目录、暂时的内核代码(exec 等)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct inode { uint dev; uint inum; int ref; struct sleeplock lock ; int valid; short type; short major; short minor; short nlink; uint size; uint addrs[NDIRECT+1 ]; };
有 4 种锁的机制
icache.lock 保证一个 inode 只会在缓存中出现一次,保证引用计数 ref
的正确
每一个 inode 都有一个 sleeplock,用于保证其内部字段的独占访问
ref 不为 0 的时候这个 entry 不会被回收
nlink 字段表示这个文件的引用数(他不为 0,xv6 就不会释放
entry)
iget() 返回一个 inode
如果是新使用的,valid = 0,之后使用的时候会从磁盘读入(ilock()
实现读入)
ilock() 是加锁的,iget() 不加锁
inode cache 是 write-through(直写的),调用 iupdate()
直接反应到磁盘上
Inode 层(代码实现)
分配一个新的 inode 结点(新建文件等)的流程如下
调用 ialloc()
从标号为 1的 inode 的开始查找,找到一个空闲的 inode 之后,调用
iget() 返回
标号为 0 是预留的?
根节点也是从 1 开始的(#define ROOTINO 1)
iget()
先看看有没有缓存,若有缓存,则引用数 ref +1,直接返回
如果没有找到,则将第一个空闲的 inode 返回
ilock()
想要对 inode 进行读写操作的时候,需要先对 inode 获取锁(调用
ilock)
同时 ilock 会检查这个内容有没有从磁盘冲读进内存,如果没有则读入
iunlock()
iput()
引用数 ref -1
如果减完之后计数为 0,同时 valid=1,nlink=0 的话,释放数据块
可能会出现这样一种情况,nlink=0,ref 不为 0,此时 inode 没有被释放
当 ref 被减为 0 的瞬间,系统崩溃了
重启的时候我们知道 nlink=0
的文件是没有用的,但是我们在磁盘上这块空间并未被释放
xv6 没有针对这个问题进行补救,因此可能出现磁盘空间耗尽的情况
Inode 的内容
结构如下
前 12 块是直接索引,后面 256 块是间接索引
文件最大大小为 268kB
bmap() 返回第 n 个数据块的地址
按照上面的索引方式找出即可
越界 panic,如果没有则分配一个
itruc() 释放数据块
遍历所有索引,如果不为 0,就释放,最后把间接索引块也释放了
stati() 将 inode 的元数据拷贝返回一个数据结构 stat
Directory 层(代码实现)
和文件相似,只不过
type=T_DIR,内容为一组目录项,每一个目录项的结构如下
1 2 3 4 5 struct dirent { ushort inum; char name[DIRSIZ]; };
name 最长为 DIRSIZ=14 个字符
dirlookup()
在一个目录中查找指定 name 的文件,返回 inode 指针
dirlink()
按照给定的 name,新建一个新的文件夹
遍历 entry,找到一个空闲的返回
如果已经存在,则报错
Pathname 层(代码实现)
通过一系列的 dirlookup() 实现
namei() 返回待查找文件的 inode
1 2 struct inode* namei (char *path) ;
nameiparent() 返回待查找文件的父节点的 inode,同时返回文件名到 name
中
1 2 struct inode* nameiparent (char *path, char *name) ;
1 2 static struct inode* namex (char *path, int nameiparent, char *name) ;
namex() 逻辑如下
首先判断是相对路径还是绝对路径,返回查找的起始 inode
接着就是一个递归查询,直到找到最终的结果,返回 inode
File descriptor 层
Unix 把很多东西都抽象为文件,
xv6 给每一个进程维护了一个文件描述符表
所有的打开文件保存在一个全局的文件表(file table
ftable)里
1 2 3 4 5 struct { struct spinlock lock ; struct file file [NFILE ]; } ftable;
filealloc()
从 ftable 中找一个引用为 0 (空闲)的文件返回
filedup()
fileclose()
引用计数 -1,如果为 0,同设置 type 为 FD_NONE
filestat()
fileread()
filewrite()
系统调用(代码实现)
sys_link()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 uint64 sys_link (void ) { char name[DIRSIZ], new[MAXPATH], old[MAXPATH]; struct inode *dp , *ip ; if (argstr(0 , old, MAXPATH) < 0 || argstr(1 , new, MAXPATH) < 0 ) return -1 ; begin_op(); if ((ip = namei(old)) == 0 ){ end_op(); return -1 ; } ilock(ip); if (ip->type == T_DIR){ iunlockput(ip); end_op(); return -1 ; } ip->nlink++; iupdate(ip); iunlock(ip); if ((dp = nameiparent(new, name)) == 0 ) goto bad; ilock(dp); if (dp->dev != ip->dev || dirlink(dp, name, ip->inum) < 0 ){ iunlockput(dp); goto bad; } iunlockput(dp); iput(ip); end_op(); return 0 ; bad: ilock(ip); ip->nlink--; iupdate(ip); iunlockput(ip); end_op(); return -1 ; }
问题 1
了解UNIX 文件系统的主要组成部分:超级块(superblock),i
节点(inode),数据块(data block),目录块(directory
block),间接块(indirection block)。分别解释它们的作用。。
超级块:指的是 Unix
文件系统存储的源信息,包括具体的物理内存分布情况,每一块区域占据的大小等
i 节点:保存文件系统的树形结构
数据块:保存文件的具体数据
Unix 文件系统的文件夹保存目录项,前 12
个目录项为直接索引,保存的是文件的起始块的地址,接着是一级索引块、二级索引块、三级索引块。
目录块指的是文件夹保存的块,保存在 i 节点区
间接块指的是索引块,保存在文件和目录区
问题 2
阅读文件 ide.c。这是一个简单的 ide
硬盘驱动程序,对其内容作大致了解。
xv6-riscv 中没有这个文件
mkfs.c 中是文件系统启动时运行的,保存在引导块中的代码
xv6-riscv 中由 7
层结构组成,每一层实现一些具体的功能,然后为上层结构提供一些接口
File Discriptor
Pathname
Directory
Inode
Logging
Buffer cache
Disk
问题 3
阅读文件buf.h、bio.c。了解XV6 文件系统中buffer cache
层的内容和实现。描述 buffer 双链表数据结构及其初始化过程,了解 buffer
的状态,了解对 buffer 的各种操作。
xv6-riscv 的 buffer 一共 30
个,组织成一个双向链表的结构(虚拟头节点,虚拟头节点的 prev
指针指向最后一个节点)
初始化部分就是把 buffer 数组组织成一个双向链表,buffer 字段初始化为
0
更加细节的答案部分见上面的阅读笔记部分,以下是上面部分的超链接(点击可以跳转到上面)
问题 4
阅读文件 log.c,了解XV6 文件系统中的 logging 和 transaction
机制。
简单的来说,xv6-riscv 在磁盘中预留了一大块区域用于 log
机制,这是用于故障恢复的
主要过程如下
对于磁盘块的写操作,我们不直接写磁盘,像将其写入 log
块中,写完之后将 log 的 header 信息写入磁盘
这个时候所有数据已经写入 log 磁盘了,此时可以进行真正的写操作
我们将这些块从 log
区域读取出来,接着将其写入原来要写入的磁盘块中
以上的操作保证了对于磁盘块的写是全或无的,不会出现不一致性
更加细节的答案部分见上面的阅读笔记部分,以下是上面部分的超链接(点击可以跳转到上面)
问题 5
阅读文件 fs.h、fs.c,了解 XV6 文件系统的磁盘布局
boot loader 占据一块
superblock 占据一块
log 占据 31 块(1 个头和 30 个log 块)
更加细节的答案部分见上面的阅读笔记部分,以下是上面部分的超链接(点击可以跳转到上面)
大小(make qemu 输出)
1 2 3 4 5 6 7 8 9 nmeta 70 ( boot, super, log blocks 30 inode blocks 13, bitmap blocks 25 ) blocks 199930 total 200000
问题 6
阅读文件 file.h、file.c,了解 XV6 的 “文件” 有哪些,以及文件、i
节点、设备相关的数据结构。了解 XV6 有哪些文件的基本操作?XV6
最多支持多少个文件?每个进程最多能打开多少个文件?
1 2 enum {
1 2 3 4 5 6 7 8 9 10 11 struct file { enum { int ref; char readable; char writable; struct pipe *pipe ; struct inode *ip ; uint off; short major; };
inode 的数据结构有两个
一个是保存在磁盘上的 inode,保存的是元数据
另一个是保存在内存中的数据结构,包含上面的部分,同时添加了一些内核为了管理文件需要维护的字段
具体内容
pipe 的数据结构如下
内容很直白,两个 fd,两个数字记录读写的字节数,一个缓冲区
1 2 3 4 5 6 7 8 9 struct pipe { struct spinlock lock ; char data[PIPESIZE]; uint nread; uint nwrite; int readopen; int writeopen; };
文件的基本操作
filealloc():分配一个新的文件 entry(打开或者新建文件使用)
filedup():复制文件
fileclose():关闭文件
filestat():获取文件的元数据信息
xv6-riscv 最多支持同时打开 100 个文件(NFILE)
每一个进程最多支持打开 16 个文件(NOFILE)
1 2 3 #define NOFILE 16 #define NFILE 100
问题 7
阅读文件
sysfile.c,了解与文件系统相关的系统调用,简述各个系统调用的作用
一个具体实现的例子如上 (sys_link())
一些与文件系统相关的系统调用的含义
sys_pipe():打开一个管道,并将结果保存到 proc 数据结构的 ofile
中
sys_chdir():切换当前目录
sys_mknod():创建字符设备文件和块设备文件
sys_mkdir():新建文件夹
sys_open():打开文件
sys_unlink():删除这个文件引用
sys_link():将 new 指向 old,指向同一个文件
sys_fstat():获取文件元数据信息
sys_close():关闭文件
sys_write():王文件中写数据
sys_read():从文件中读取数据
sys_dup():复制文件
参考资料
https://pdos.csail.mit.edu/6.828/2020/xv6/book-riscv-rev1.pdf
https://github.com/mit-pdos/xv6-riscv