0%
并发控制
两段锁协议
封锁的定义
- 封锁就是一个事务对某个数据对象加锁,取得对它一定的控制,限制其它事务对该数据对象使用
- 要访问一个数据项 \(R\),事务 \(T_i\) 必须先申请对 \(R\) 的封锁,如果 \(R\) 已经被事务 \(T_j\) 加了不相容的锁,则 \(T_i\) 需要等待,直至 \(T_j\) 释放它的封锁
- 例子:信号灯
- 封锁性能
- 一些其他的指标
- 数据库追求的目标:在避免冲突的前提下,提高事务吞吐量(提高并发度)
锁持有期
- 长锁:保持到事务结束时才释放的锁
- 短锁:在事务中途就可以释放的锁
- 例子
- read uncommitted:不申请锁
- read committed:短 S 锁
- repeatable read:长 S 锁
两段锁协议
- Two-Phase Locking Protocol
- 事务加锁和解锁过程是严格分开的
- 增长阶段(Growing Phase)
- 缩减阶段(Shrinking Phase)
- 图示
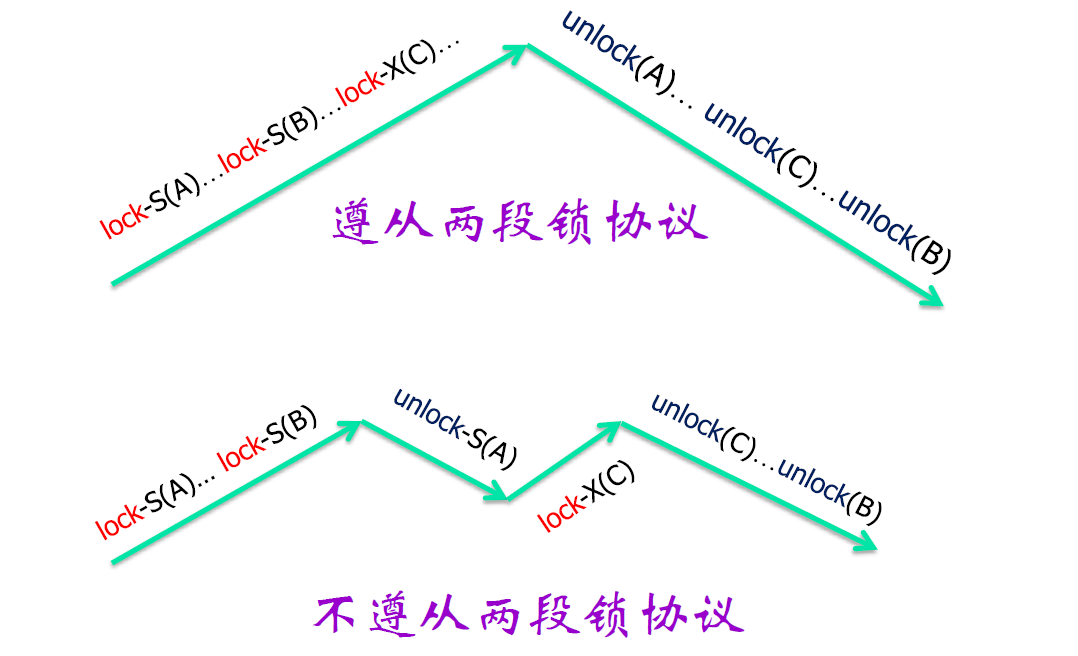
两阶段封锁协议的作用
- 若一组事务均服从两阶段封锁协议,则它们的调度一定是可串行化的
- 封锁点:事务获得其最后封锁的时间
- 事务调度等价于和其封锁点顺序一致的串行调度
- 例子
- 如下图,t1, t2, t3 满足 2PL 则等价的串行顺序是 t1, t3, t2
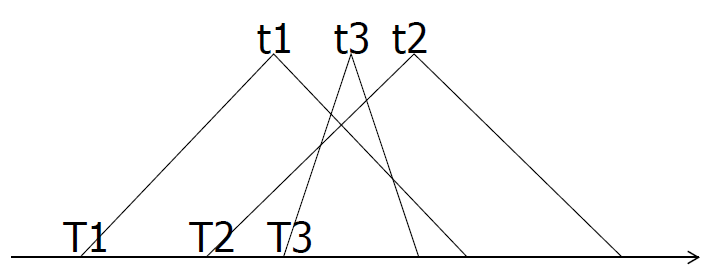
为什么两阶段封锁协议保证可串行化?
- 令 \(\{T_0,T_1,\cdots,T_n\}\)
是参与调度 \(S\) 的事务集
- 如果 \(T_i\) 对数据项 \(R\) 加 \(A\) 型锁,\(T_j\) 对数据项 \(R\) 加 \(B\) 型锁,且 \(\mathrm{comp(A,B)=false}\)(不相容的锁),若
\(T_i\) 先获得锁,则 \(T_i\) 先于 \(T_j\),记作 \(T_i\to T_j\),得到一个优先图
- 设 \(t_i\)是 \(T_i\) 的封锁点,若 \(T_i\to T_j\),则必然有 \(t_i<t_j\)
- 事务 \(T_j\) 需要等待 \(T_i\)
释放不相容的锁之后,才能获得锁,不妨设这个时间为 \(t_m\)
- \(t_i<t_m\le t_j\)
- 若 \(\{T_0,T_1,\cdots,T_n\}\)
不可串行化,则在优先图中存在环,不妨设为 \(T_0\to T_1\to\cdots\to T_n\to T_0\),则
\(t_0<t_1<\cdots<t_n<t_0\),时间不可能成环,矛盾
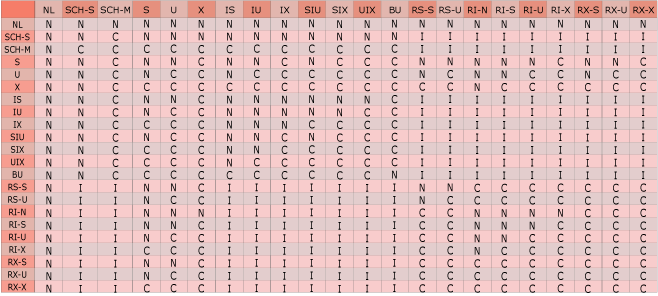
封锁类型
- 基本锁类型:X 锁、S 锁、U 锁
- 意向锁:IS、IX、IU、SIX
- 码范围锁:RangeS_S、RangeI_N…
- 其他锁:模式锁、闩锁、BU锁
基本锁类型(排他锁、共享锁、更新锁)
排他锁与共享锁
- 排它锁(X 锁,eXclusive lock)
- lock-X(R):又称写锁,持有 X 锁可以读写数据项
- 事务 T 对数据对象 R 加上 X 锁,则其它事务对 R
的任何封锁请求都不能成功,直至 T 释放 R 上的 X 锁
- 共享锁(S 锁,Share lock)
- lock-S(R):又称读锁,持有 S 锁只能读取数据项
- 事务 T 对数据对象 R 加上 S 锁,则其它事务对 R 的 X
锁请求不能成功,而对 R 的 S
锁请求可以成功
- 封锁的相容矩阵 \(\mathrm{comp(A,B)}\)
| S |
\(\checkmark\) |
\(\times\) |
| X |
\(\times\) |
\(\times\) |
先读后写场合中的锁转换
- 两个事务 T1, T2
- T1: read(a1); read(a2); ...; read(an); write(a1)
- T2: read(a1); ...
- T1 需要对 a1 加 X 锁(因为后面要写)
- 更好的并发方式
- T1 在 read(a1) 上加 S 锁,在执行 write(a1) 之前升级锁(upgrade)为 X
锁
- 升级的时候要求没有事务在 a1 上持有锁
- 如下左图等价于串行调度 T1,T2,右图等价于串行调度 T2,T1

带有锁转换的两段锁协议
- 增长阶段
- 可获得 lock-S
- 可获得 lock-X
- 可将 lock-S 升级为 lock-X(upgrade)
- 缩减阶段
- 可释放 lock-S
- 可释放 lock-X
- 可将 lock-X 降级为 lock-S(downgrade)
锁升级与重新申请锁
- 升级锁和重新申请锁的区别
- 申请锁是维护一个队列的
- 重新申请锁则会排在队列的最后
- 升级锁则会排在队列的前面,可能更早考虑
- 在那个隔离性级别下会出现锁升级
- repeatable read
- read committed 不会,因为是短 S 锁
锁转化带来的问题
- 死锁
- 两个事务都是先读后写
- 如下例子
- repeatable read 情况下(read 为长 S 锁)
- T1 在 write(a1) 时需要锁升级,但是如果此时 T2 已经执行到了 read(a1)
之后,此时 T1 等待
- 同样的道理 T2 也等待,导致死锁
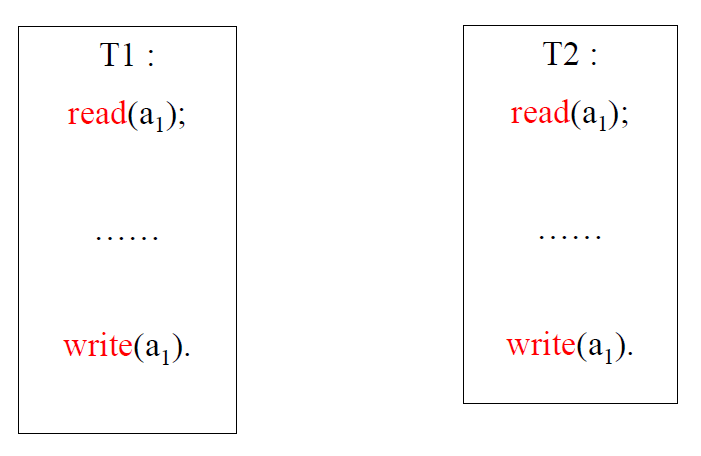
怎么避免锁转换导致的死锁
更新锁
- U 锁,Update lock
- 当一个事务查询数据以便将来要进行修改时,可以对数据项施加更新锁
- 如果事务修改资源,需将更新锁转换为排它锁(X 锁)
- 一次只有一个事务可以获得资源上的更新锁
- 这样就避免了死锁
- U 锁和 U 锁不相容,因此上面的例子
更新锁的相容矩阵
| S |
\(\checkmark\) |
\(\times\) |
\(\checkmark\) |
| X |
\(\times\) |
\(\times\) |
\(\times\) |
| U |
\(\checkmark\) |
\(\times\) |
\(\times\) |
封锁粒度
- 封锁对象
- 属性值、属性值集合、元组、关系、索引项、整个索引、整个数据库、物理页、块
- 不同封锁粒度
- 封锁粒度大,则并发度低,开销小
- 封锁粒度小,则并发度高,开销高
- 一个锁在数据库中大概占据 100 来个字节
- 事务的完整性相关域:
封锁粒度与查询性能
- 一份早期的数据,数据表五道口技工学院中性别为女的记录非常少
- 满足条件的数据非常少时,最佳粒度为行锁
1
2
3
| select *
from 五道口技工学院
where 性别='女'
|
1
2
3
| select *
from 五道口技工学院
where 性别='男'
|
多粒度封锁中的隐含冲突
1
2
3
| select *
from 五道口技工学院
where 性别='男'
|
1
2
3
| select *
from 五道口技工学院
where 性别='女'
|
- T1 和 T2 的冲突是能够检测出来的
- 事务 T2 和 T3 的冲突无法检测
- 冲突无法检测的原因:大集合中包含小集合,存在包含冲突
- 在分层封锁中,封锁了上层节点就意味着封锁了所有内层节点
- 如果有事务 T3 对某元组加了 S 锁,而事务 T2 对该元组所在的关系加了 X
锁,因而隐含地 X 封锁了该元组,从而造成矛盾
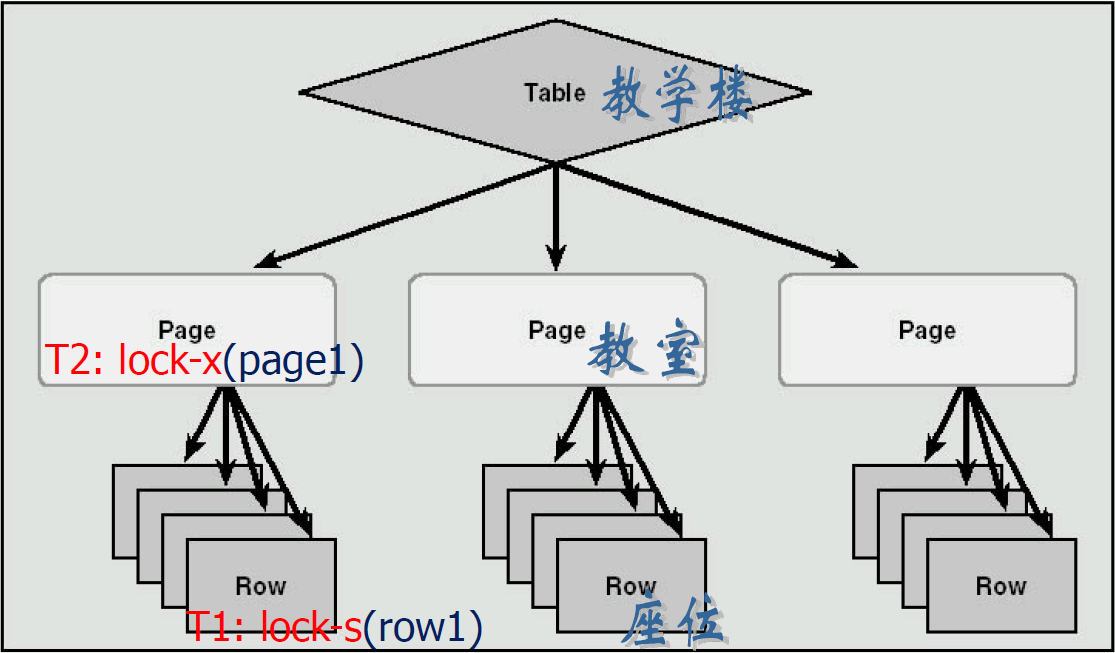
- 在对某个粒度加锁的同时,在其父节点贴上告示条,表示被占用
- 告示条和告示条之间不冲突
- 告示条告诉别人不能直接加锁
- 告示条只起到提示作用
- 引入意向锁(起到告示条的作用)
意向锁
意向锁 I(Intend)
- 引入意向锁 I(Intend)
- 当为某节点加上 I
锁,表明其某些内层节点已发生事实上的封锁,防止其它事务再去显式封锁该节点
- I
锁的实施是从封锁层次的根开始,依次占据路径上的所有节点,直至要真正进行显式封锁的节点的父节点为止
意向锁 I 的相容性
| S |
\(\checkmark\) |
\(\times\) |
\({\color{red}\times}\) |
| X |
\(\times\) |
\(\times\) |
\(\times\) |
| I |
\({\color{red}\times}\) |
\(\times\) |
\({\color{red}\checkmark}\) |
意向锁 I 的不足之处
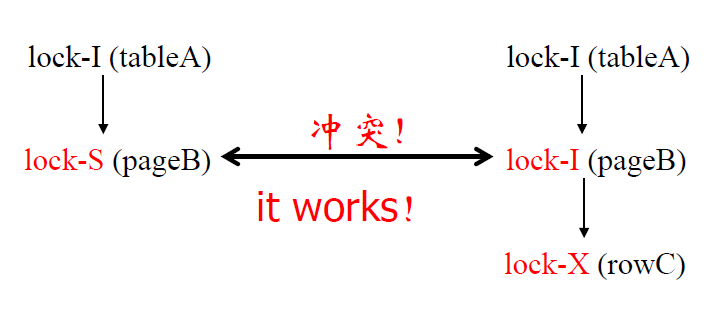
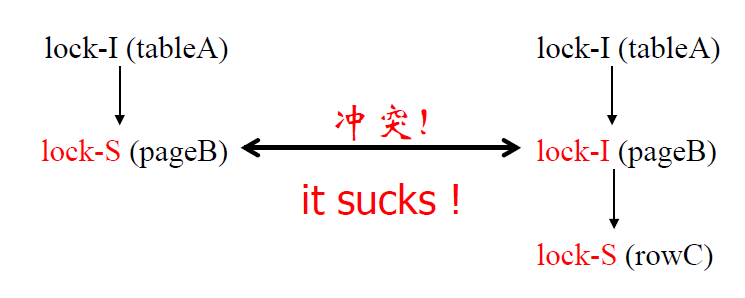
- 降低了并发度
- 根本原因:I 锁没有告诉我们内层加的锁的类型
- 引入意向锁 IS 锁,IX 锁
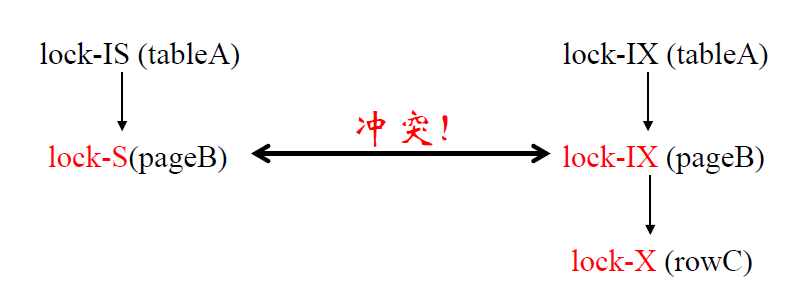
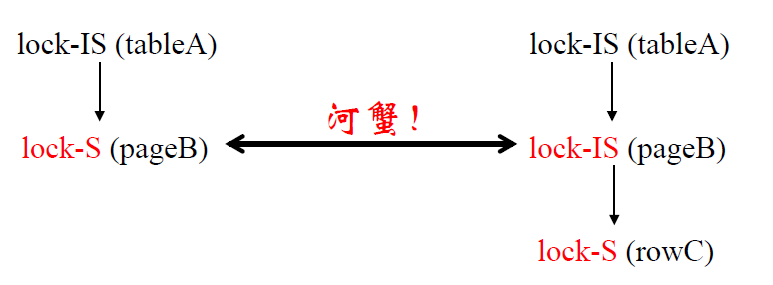
更为精细化的意向锁(IS 锁,IX
锁)
- IS 锁:如果对一个数据对象加 IS
锁,表示它的后裔节点拟(意向)加 S 锁
- IX 锁:如果对一个数据对象加 IX
锁,表示它的后裔节点拟(意向)加 X 锁
- 本质还是意向锁,起到告示条的作用
意向锁 IS/IX 的相容性
| S |
\(\checkmark\) |
\(\times\) |
\({\color{red}\checkmark}\) |
\({\color{red}\times}\) |
| X |
\(\times\) |
\(\times\) |
\(\times\) |
\({\color{red}\times}\) |
| IS |
\({\color{red}\checkmark}\) |
\(\times\) |
\({\color{red}\checkmark}\) |
\({\color{red}\checkmark}\) |
| IX |
\({\color{red}\times}\) |
\({\color{red}\times}\) |
\({\color{red}\checkmark}\) |
\({\color{red}\checkmark}\) |
实际例子
共享与意向排他锁 SIX
- 共享、意向排他
- 解决如下事务的加锁问题
- 在表的级别应该加什么锁呢?
- IX 和 S 单独都不能支持这个操作
- X 锁并发性很低
1
2
3
4
5
6
| set transaction isolation level repeatable read
begin tran 'audit'
select * from bigtable
update bigtable
set col = 0
where keycolumn = 100
|
- 在表上加 SIX 锁,则表示该事务要读整个表(S
锁),同时会更新个别元组(IX 锁)
- SIX 锁只和 IS 锁相容
相容矩阵
| S |
\(\checkmark\) |
\(\times\) |
\(\checkmark\) |
\({\color{red}\checkmark}\) |
\({\color{red}\times}\) |
\(\times\) |
| X |
\(\times\) |
\(\times\) |
\(\times\) |
\(\times\) |
\({\color{red}\times}\) |
\(\times\) |
| U |
\(\checkmark\) |
\(\times\) |
\(\times\) |
\(\checkmark\) |
\(\times\) |
\(\times\) |
| IS |
\({\color{red}\checkmark}\) |
\(\times\) |
\(\checkmark\) |
\({\color{red}\checkmark}\) |
\({\color{red}\checkmark}\) |
\({\color{red}\checkmark}\) |
| IX |
\({\color{red}\times}\) |
\({\color{red}\times}\) |
\(\times\) |
\({\color{red}\checkmark}\) |
\({\color{red}\checkmark}\) |
\(\times\) |
| SIX |
\(\times\) |
\(\times\) |
\(\times\) |
\({\color{red}\checkmark}\) |
\(\times\) |
\(\times\) |
SQL Server 的锁模式
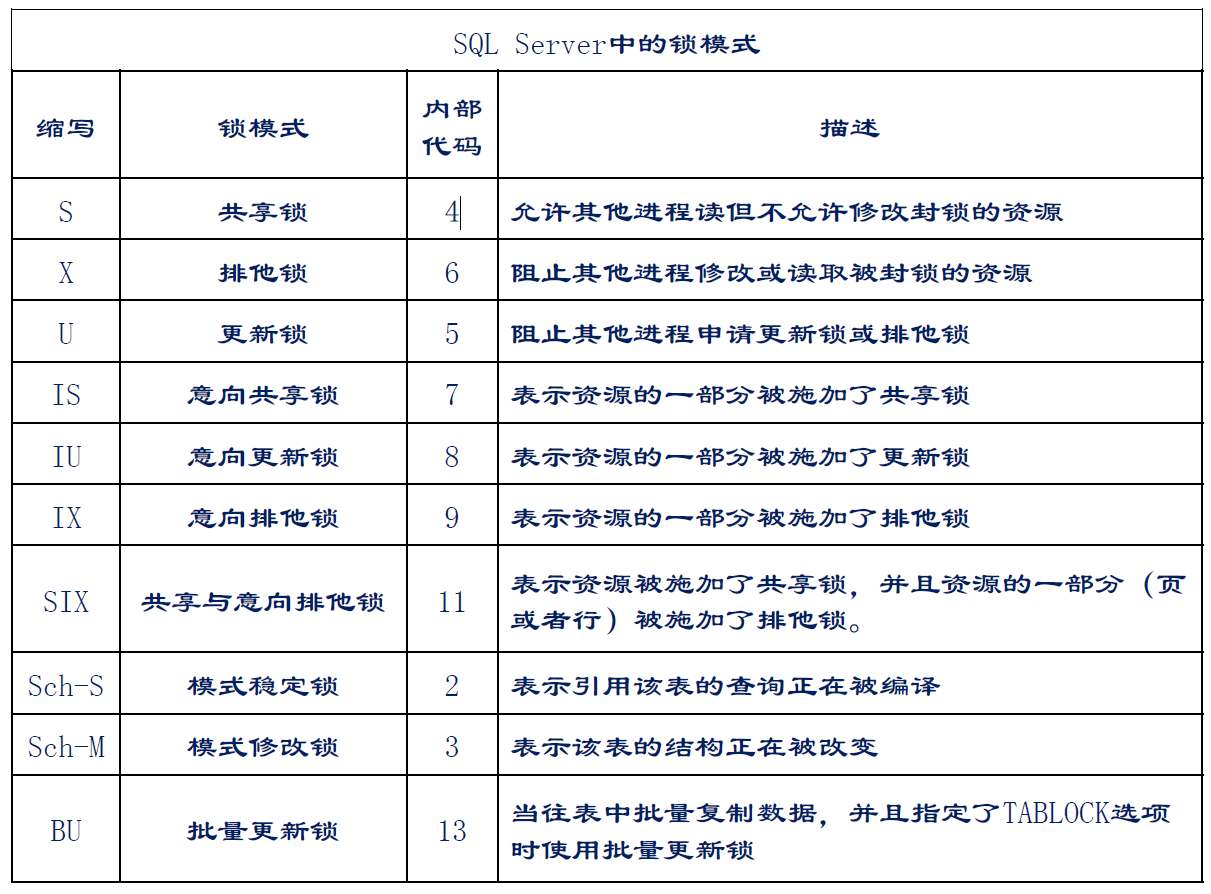
模式修改锁(Sch-M锁)
- 执行表的 DDL 操作时使用模式修改锁
- Sch-M 锁与所有锁模式都不相容
模式稳定锁(Sch-S锁)
- 当编译查询时,使用模式稳定锁
- Sch-S 锁与除了 Sch-M 锁之外所有其它锁模式相容
- 此时其它事务都能继续运行,但不能对表执行 DDL 操作
SQL Server中的大容量更新锁
- BU 锁,Bulk update lock
- 当使用
bulk insert 命令或 bcp
工具将数据大容量复制到表,且指定了 TABLOCK 提示或者使用
sp_tableoption 设置了 table lock on bulk
表选项时,将使用大容量更新锁
- 大容量更新锁允许多个进程将数据并行地大容量复制到同一表,同时防止其它不进行大容量复制数据的进程访问该表
SQL Server 码范围锁
- 如何避免幻象的产生
- 只封锁现有数据是无效的
- 查询例子
1
| select * from R where A>=10 and A<=20
|
- 应该防止其他事务往区间 \([10,20]\)
插入数据
- 如何找到这样一个区间?
- 表本身是无序的集合,只能用整个表覆盖这个区间,也即需要申请表级锁,并发度极低
- 数据库中什么对象是有序的?
- 如果在 A 上存在索引,则可以找到一个紧凑区间
码范围锁:范围扫描查询
- 码范围锁定原理解决了幻像并发问题
- 码范围锁通过覆盖索引行和索引行之间的范围来工作,因为第二个事务在该范围内进行任何行插入、更新或删除操作时均需要修改索引,而码范围锁覆盖了索引项,所以在第一个事务完成之前会阻塞第二个事务的进行
- 要求(同时满足)
- 必须在查询项上存在索引
- 隔离性级别为 serializable
码范围锁模式
- 码范围锁包括范围组件和行组件
- 前者表示保护两个连续索引项之间范围的锁模式(RangeT)
- 后者表示保护索引项的锁模式(K),这两部分用下划线连接,如
RangeT_K
| RangeS |
S |
RangeS_S |
共享范围,共享资源锁;可串行范围扫描 |
| RangeS |
U |
RangeS_U |
共享范围,更新资源锁;可串行更新扫描 |
| RangeI |
NULL |
RangeI_N |
插入范围,空资源锁;用于在索引中插入新码之前测试范围 |
| RangeX |
X |
RangeX_X |
排它范围,排它资源锁;用于更新范围中的码 |
码范围锁的相容矩阵
| 共享(S) |
\(\checkmark\) |
\(\checkmark\) |
\(\times\) |
\(\checkmark\) |
\(\checkmark\) |
\(\checkmark\) |
\(\times\) |
| 更新(U) |
\(\checkmark\) |
\(\times\) |
\(\times\) |
\(\checkmark\) |
\(\times\) |
\(\checkmark\) |
\(\times\) |
| 排它(X) |
\(\times\) |
\(\times\) |
\(\times\) |
\(\times\) |
\(\times\) |
\(\checkmark\) |
\(\times\) |
| RangeS_S |
\(\checkmark\) |
\(\checkmark\) |
\(\times\) |
\(\checkmark\) |
\(\checkmark\) |
\(\times\) |
\(\times\) |
| RangeS_U |
\(\checkmark\) |
\(\times\) |
\(\times\) |
\(\checkmark\) |
\(\times\) |
\(\times\) |
\(\times\) |
| RangeI_N |
\({\color{red}\checkmark}\) |
\(\checkmark\) |
\({\color{red}\checkmark}\) |
\({\color{red}\times}\) |
\(\times\) |
\(\checkmark\) |
\(\times\) |
| RangeX_X |
\(\times\) |
\(\times\) |
\(\times\) |
\(\times\) |
\(\times\) |
\(\times\) |
\(\times\) |
一个例子
- employees 表上存在 last_name 上的索引
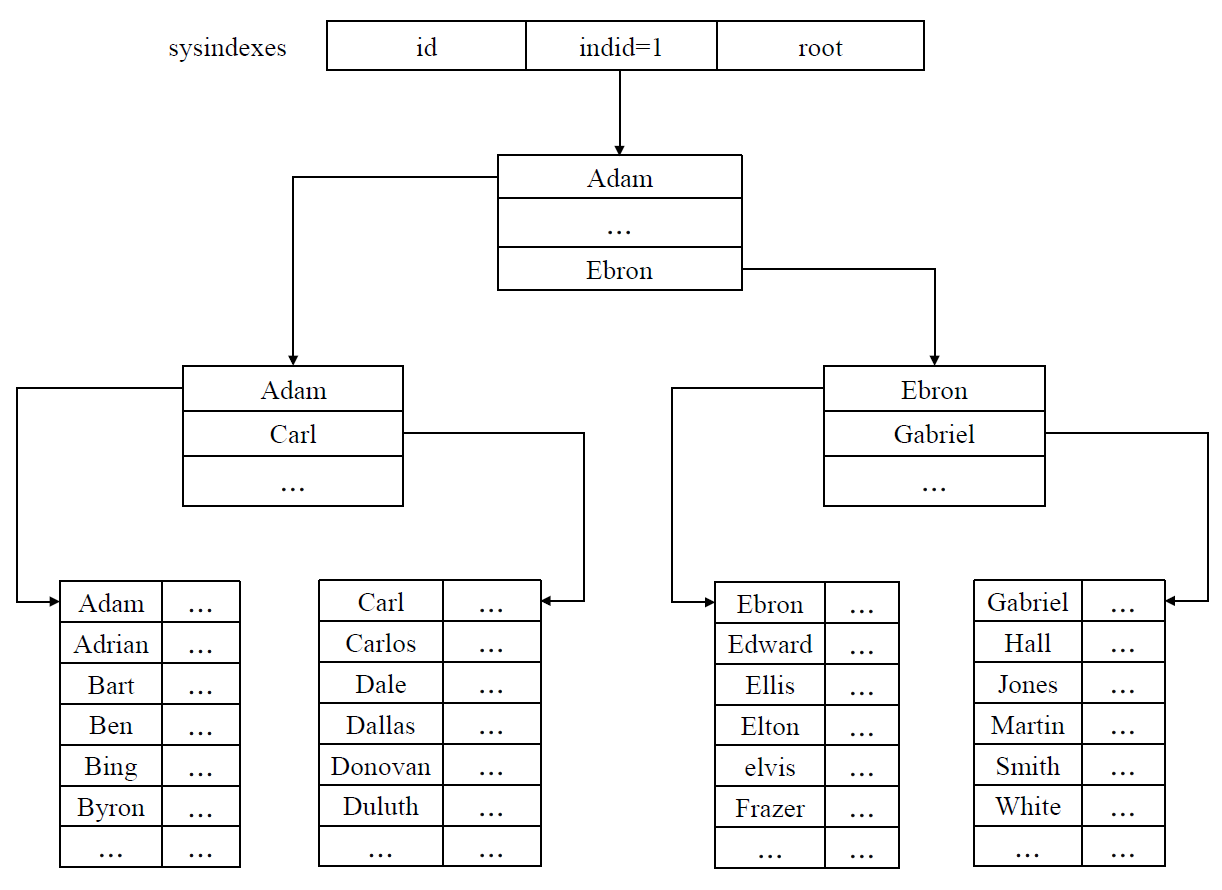
- 在 serializable 隔离性级别上执行如下查询
1
2
3
| select *
from employees
where last_name between 'Delaney' and 'DuLaney'
|
- 在索引上找到一个覆盖上面范围的最小区间 \(\mathrm{(Dallas,Duluth)}\)
- 如果 Dallas, Donovan 和 Duluth
是叶级的顺序索引码,前两个码将获得码范围锁 RangeS_S
- 码范围锁防止任何向以这两个码结束的区间插入数据
- 锁住了 Dallas 和 Donovan 后面的区间
- 没有大于 Dallas 且小于等于 Donovan 的行可以插入,也没有大于 Donovan
且小于等于 Duluth 的行可以插入
- 能否插入 Dashagua?
- 不能插入,虽然是在查询范围之外,但是在最小覆盖的索引范围内部
SQL Server 锁
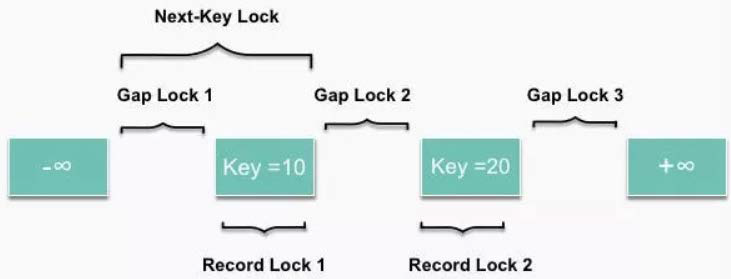
MySQL 中的行锁模式
- MySQL 的 innode
引擎,在建表的时候,默认会有一个隐含的自增字段,缺省的会在这个字段上建立聚簇索引
- 缺省的 MySQL 就是有序的表
- MySQL 中的行锁模式
- lock_rec_not_gap:只锁记录
- lock_gap:间隙锁,锁两个记录之间的gap,防止记录插入
- lock_ordinary:也称为Next-KeyLock,锁一条记录及其之前的间隙
- lock_insert_intension:插入意向gap锁,插入记录时使用,是lock_gap的一种特例
- 图示
| RECORD |
|
\(\checkmark\) |
|
\(\checkmark\) |
| GAP |
\(\checkmark\) |
\(\checkmark\) |
\(\checkmark\) |
\(\checkmark\) |
| NEXT-KEY |
|
\(\checkmark\) |
|
\(\checkmark\) |
| II GAP |
\(\checkmark\) |
|
|
\(\checkmark\) |
闩锁
- lock:保护逻辑对象
- latch:保护内存页
- 以下显示不对内存页加保护的结果

- 为什么不直接使用排他锁实现?
- 闩锁是自旋锁(spinlock)
- 使用序列号锁聚簇索引码的问题
- 由于自增 id,最新的页面会被很多进程同时写,闩锁竞争激烈
MySQL 的自增器
1
2
3
4
5
6
7
|
insert into t1 values (1),(2)
insert into t2 select * from t1
|
- 已知行数用闩锁(mutex),未知行数使用自增锁(auto-inc locking)
- 为了保证同一个事务插入的数据,自增 id 是连续的