数据库概论.陈立军.04.非关系型数据
SQL 非关系型数据
- 关系型数据库中的非关系数据
- 关系型数据库的目标:One Size Fits All
- 非关系数据
- 序列、树、图、XML、JSON、RDF
- ...
窗口函数
- 股票走势的指标
- 移动平均线
- MACD:指数平滑异同平均线
- KDJ
- BOLL
- K 线
- 需要窗口函数的支持
- 移动方式
- 滑动窗口:最近
- 跳动窗口:每隔
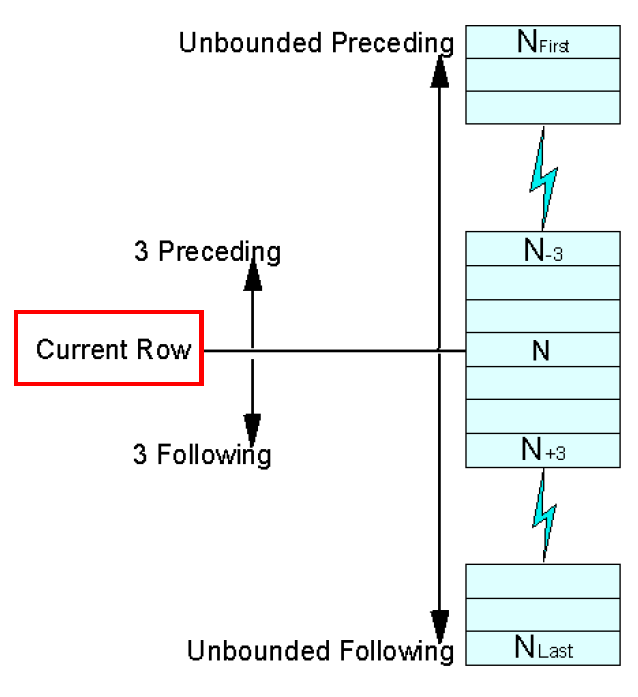
- 窗口范围
- 基于时间
- 基于行
- 基于值
- 基于行的滑动窗口
- 基准:current row
窗口函数声明
1 | function_name(<argument>, <argument>, ...) |
- Partition by:对表进行分区,类似group by
- Order by:排序
- Windowing:窗口函数
一个例子
1 | stock(stock_id, trade_day, open_price, high_price, low_price, close_price) |
1 | partition by stock_id |
- 应用例子
- 下面例子的边界情况
- 第一行没有前一行,那么就是当前行和下一行两行的平均
1 | select stock_id,trade_day,close_price, |
窗口函数类型
- 传统聚集函数:sum,avg,count,max,min
- 排名函数:rank,dense_rank,row_number
- 分布函数:percent_rank,cume_dist
- 逆分布函数:percent_cont,percentile_disc
- 偏移函数:lag,lead
示例表
| testid | studentid | score |
|---|---|---|
| Test ABC | Student E | 50 |
| Test ABC | Student C | 55 |
| Test ABC | Student D | 55 |
| Test ABC | Student H | 65 |
| Test ABC | Student I | 75 |
| Test ABC | Student B | 80 |
| Test ABC | Student F | 80 |
| Test ABC | Student A | 95 |
| Test ABC | Student G | 95 |
| Test XYZ | Student E | 50 |
| Test XYZ | Student C | 55 |
| Test XYZ | Student D | 55 |
| Test XYZ | Student H | 65 |
| Test XYZ | Student I | 75 |
| Test XYZ | Student B | 80 |
| Test XYZ | Student F | 80 |
| Test XYZ | Student A | 95 |
| Test XYZ | Student G | 95 |
| Test XYZ | Student J | 95 |
一般聚合函数
1 | select testid, studentid, score, |
排名函数对比
1 | select studentid, score, |
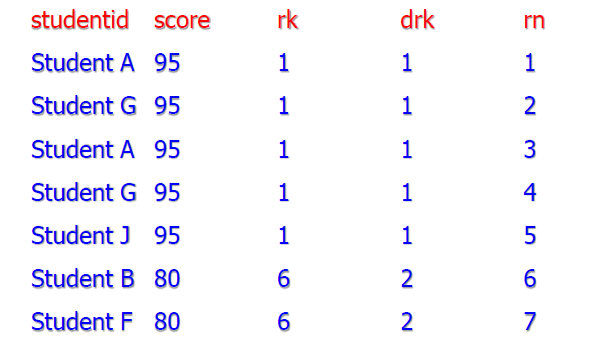
- 部分结果展示
- rank、dense_rank、row_number 区别如下
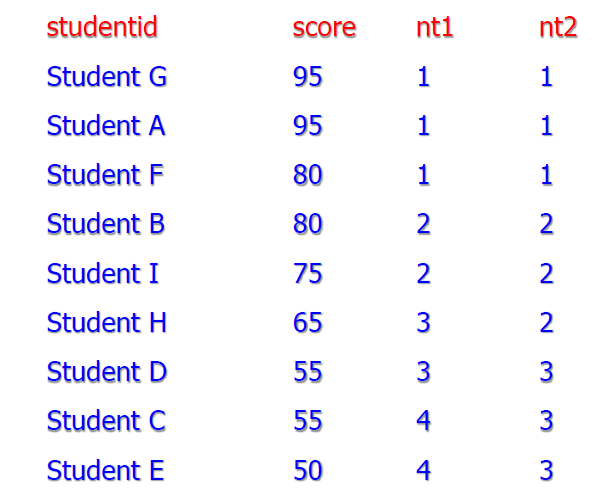
ntile
- 划档,尽可能让每个档中的人数相同
- 每条记录的返回值就是一个序号
1 | select studentid, score, |
- 参照效果如下(数据似乎和示例表有出入)
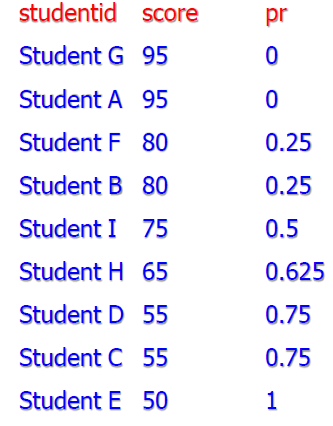
percent_rank
- 返回分位数
- 计算一个值在一组值当中的相对位置或排名
- rk:rank 排名
- nr:窗口内总行数
- \(\mathrm{percent\_rank=\dfrac{rk-1}{nr-1}}\)
1 | select studentid, score, |
cume_dist
- 与 percent_rank 类似
- 计算某个值一组值内的累积分布,也即计算某指定值在一组值中的相对位置
- 对于值 r,假定采用升序,r 的 cume_dist 是值低于或等于 r 的值的行数除以整个行数
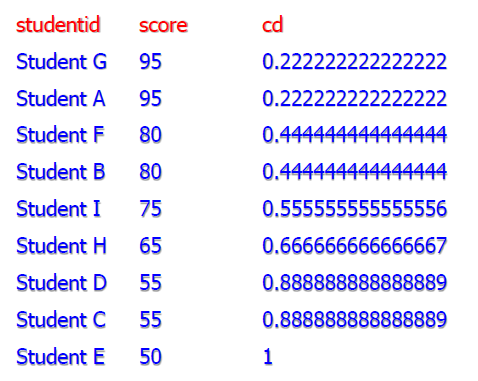
逆分布函数
- percentile_disc:离散百分位
- 找到的结果一定是数据中存在的
- percentile_cont:连续百分位
- 找到的结果不一定是数据中存在的
1 | select distinct testid, |

偏移函数
1 | lag(表达式,偏移量,缺省值) over(...) |
1 | select lag(score,1,0) over(order by score) as pre_score, |
树
层次结构
- 数据结构
- 树:职工之间的领导联系
- 有向图:零件之间的构成联系
- 无向图:交通网络
- 操作需求
- 返回指定节点的所有子(父)节点,显示格式
- 改变隶属关系
- 环路检测
- 生成传递闭包
- 最短路径
层次结构的例子
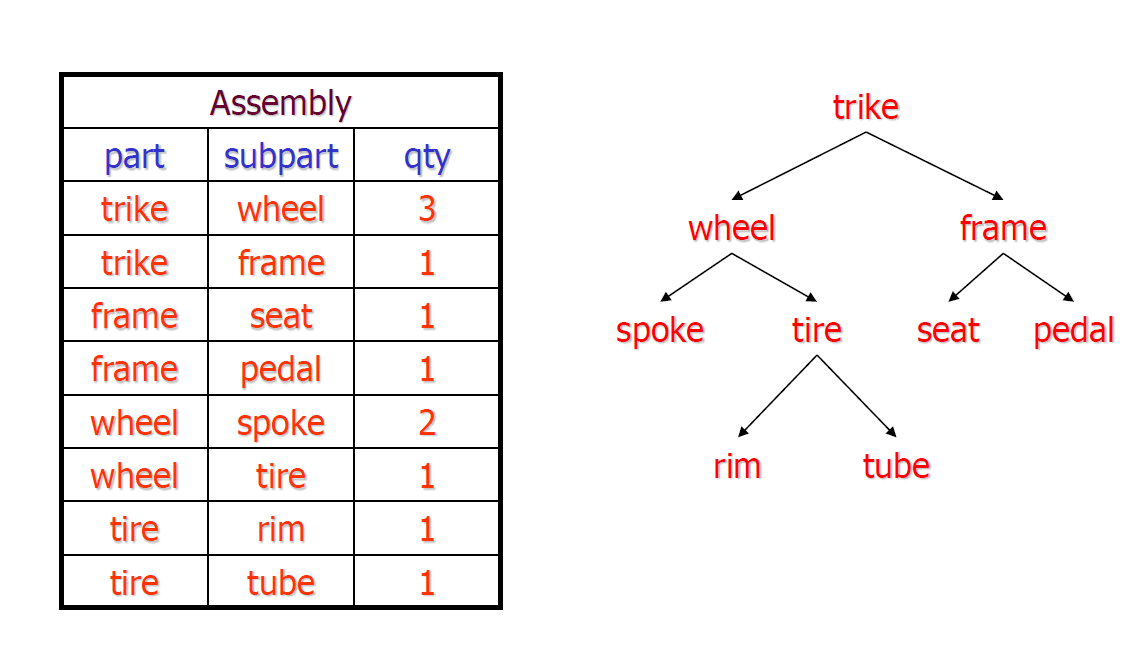
层次结构的关系表示方法
- 对于树、图等数据结构,其关系存储有以下三种方式
graph TD; A-->B; A-->C; B-->D; B-->E; C-->F
邻接表
- adjacent(child,parent)
| child | parent |
|---|---|
| B | A |
| C | A |
| D | B |
| E | B |
| F | C |
物化路径
- 记录所有的路径
- materialize_path(node,path)
| node | path |
|---|---|
| A | .A |
| B | .A.B |
| C | .A.C |
| D | .A.B.D |
| E | .A.B.E |
| F | .A.C.F |
嵌套集合
- 子结点的范围是父结点的一个细分
- nested_net(node,left_value,right_value)
| node | left_value | right_value |
|---|---|---|
| A | 1 | 12 |
| B | 2 | 7 |
| C | 8 | 11 |
| D | 3 | 4 |
| E | 5 | 6 |
| F | 9 | 10 |
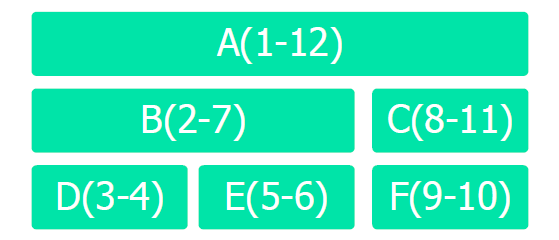
应用需求
- 找到某个结点的所有子孙节点
- 递归查询
递归查询
- 内部实现,多次连接直到最终形成的表为空
Oracle
- Connect By
1 | Select part, subpart |
SQL Server
- 基本事实:儿子是孩子
- 规则:儿子的孩子还是孩子
1 | WITH RecursiveCTE |
- 实际例子
1 | with Components(part, subpart) as ( |
- 从最基础的语法出发实现的递归查询
1 | create function dbo.fn_subordinates(@root as int) |
Hierachyid:SQL Server
- 可以存储树的结点,存储树形结构
- hierarchyid 表示层次结构中的位置,由应用程序来生成和分配 hierarchyid 值
1 | create table emp ( |
1 | declare @root hierarchyid, |
图
SQL Server
- 图 = 顶点表 + 边表
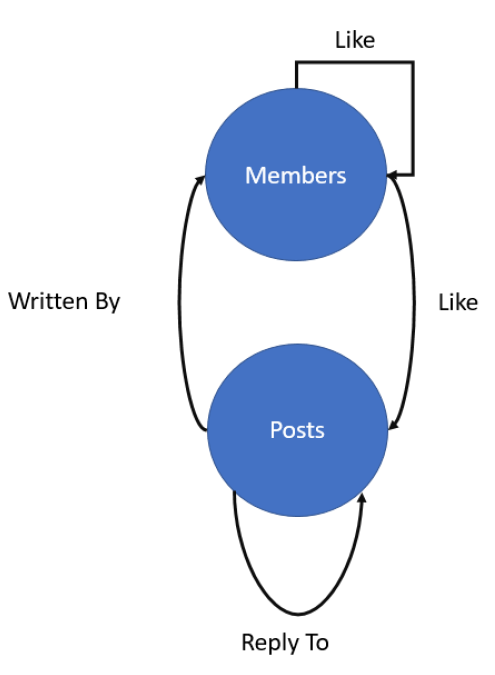
1 | create table (...) as NODE |
1 | create table ForumMembers( |
1 | insert ForumMembers values(1,'Mike') |
XML
MySQL
1 | set @xml=' |
1 | select ExtractValue(@xml, '//author') |
JSON
- 对象:{属性名:属性值,属性名:属性值 ...}
- 数组:[ value, value, value ...]
MySQL
1 | -- 解析为一个 JSON 数组 |
1 | create table tj10 (a json, b int) |
1 | create table jemp( |
RDF
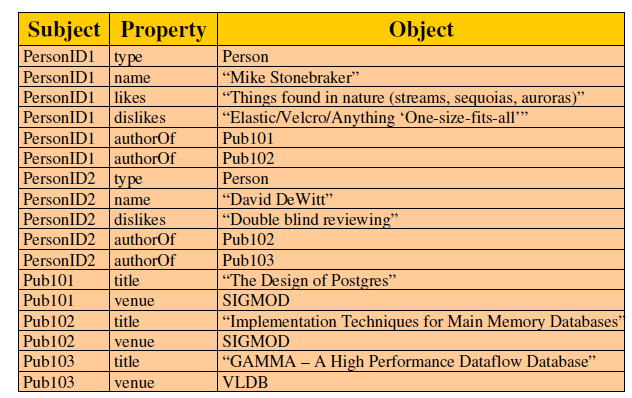
- 资源描述框架 RDF
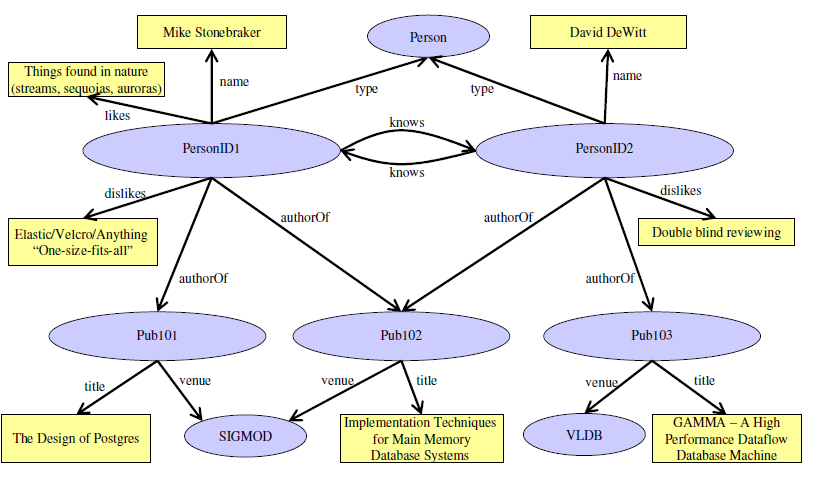
- 三元组
- <标识符,属性名,属性值>