xv6-riscv-源代码阅读.虚存管理
XV6 源代码阅读——虚存管理
说明
- 阅读的代码是
xv6-riscv版本的 - 涉及到的文件如下
kernelkalloc.c、vm.c
问题 1
XV6 初始化之后到执行 main.c 时,内存布局是怎样的(其中已有哪些内容)?
xv6 的启动流程(main.c 之前)
- xv6 的启动过程在之前的进程线程源代码阅读中已经说过了,这里只展示和内存分布相关的部分
- kernel/kernel.ld
- 当 xv6 的系统启动的时候,首先会启动一个引导加载程序(存在 ROM 里面),之后装载内核程序进内存
- 引导加载程序把内核代码加载到物理地址为 0x8000000 的地方(0x0 - 0x80000000 之间有 I/O 设备)
- 设置 ENTRY 为_entry,开始执行 kernel/entry.S 的代码
- kernel/entry.S
- 注意由于只有一个内核栈,内核栈部分的地址空间可以是固定,因此 xv6 启动的时候并没有开启硬件支持的 paging 策略,也就是说,对于内核栈而言,它的物理地址和虚拟地址是一样的
- 在机器模式下,CPU 从 _entry 处开始执行操作系统的代码
- 首先需要给内核开辟一个栈,从而可以执行 C 代码
- 每一个 CPU 都应该有自己的栈(xv6 最多支持 8 个 CPU),开始每个内核栈的大小为 4096 byte,地址空间向下增长
- 最后设置调用 kernel/start.c 中的 start 函数
- kernel/start.c
- 主要是配置一些寄存器和机器状态等
- 例如打开时钟中断、设置中断等
- 跳转到 kernel/main.c
回答问题
- xv6 的内存分布如下
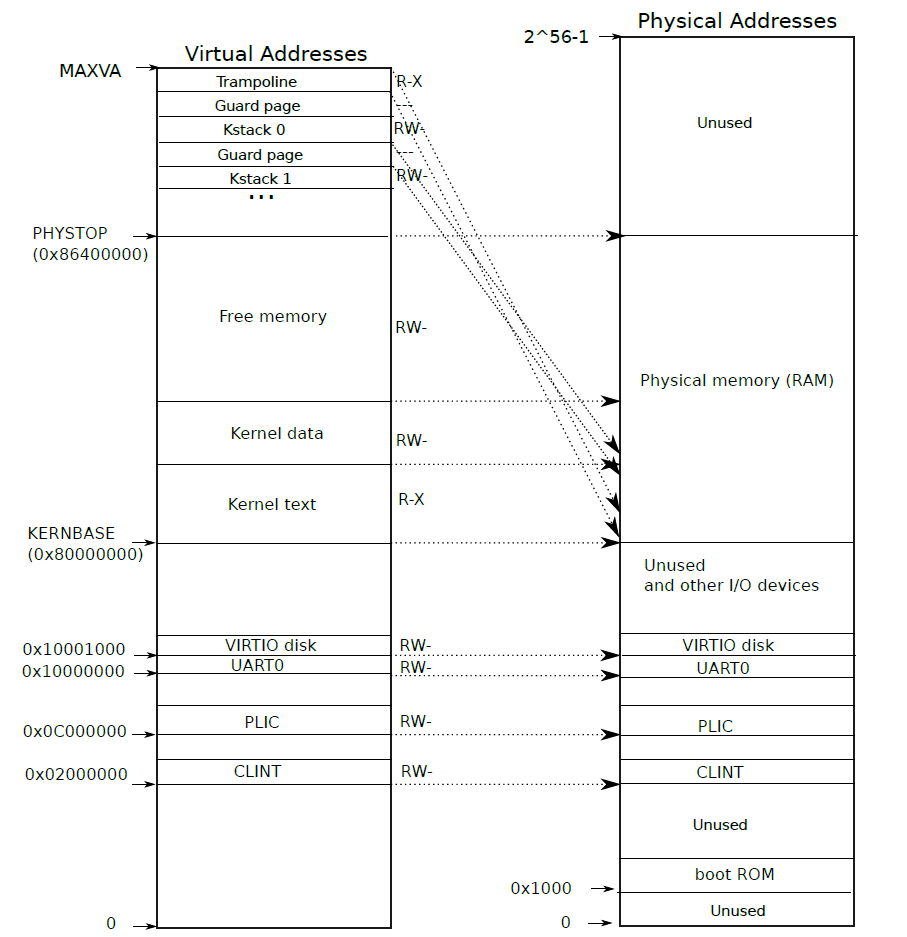
- 根据上面的描述,在执行到 main.c 之前,在内存中 Kernel text 、Kernel data、UART0、PLIC、CLINT、VIRTIO 是已经存在了的,通过引导程序加载进了内存
问题 2
XV6 的动态内存管理是如何完成的?有一个kmem(链表),用于管理可分配的物理内存页
(vend=0x00400000,也就是可分配的内存页最大为4Mb)
- xv6 的动态内存管理指的是怎么去管理物理内存
- xv6 将 Kernel data 以上,PHYSTOP
以下的区域用于作为物理内存的分配,将其划分为页的形式,然后保存在数据结构
kmem中,kmem中保存着一个链表,这个链表保存着所有空闲的物理内存 - xv6 的物理内存分配与回收都是按页进行的
- 当需要申请一块物理内存的时候,我们调用
kalloc()从kmem中申请一页(链表头部申请一页),当需要时放一块内存的时候,我们调用kfree()将内存还给kmem(插入到链表的开头)
问题 3
XV6 的虚拟内存是如何初始化的?画出 XV6 的虚拟内存布局图,请说出每一部分对应的内容是什么
见 memlayout.h 和 vm.c 的 kmap 上的注释
- 虚拟内存的初始化是在
main.c中实现的 - 内存分布图如上
main.c 的操作
kinit()
- 调用
kinit()对物理页进行一个组织- 将 Kernel data 以上,PHYSTOP 以下的区域用于作为物理内存的分配
- 因为 xv6
分配物理页是按页分配的,需要将这个区域两端取整,然后按页划分,保存在结构体
kmem的freelist中
1 | struct { |
kvminit()
- 调用
kvminit()对内核的页表进行初始化,调用kvmmake()实现 - 直接映射(物理地址和虚拟地址相同)生成如下的页表(为了使用统一的页表映射策略)
- UART0:Universal Asynchronous Receiver/Transmitter
- VIRTIO0:virtio disk
- PLIC:Platform-Level Interrupt Controller
- Kernel text(内核代码段)
- Kernel data(内核数据段)
- 对
TRAMPOLINE进行虚拟映射 - 映射内核栈,为每一个进程分配一个页的内核栈,在两个内核栈之间分配一个 guard page,用于检测栈溢出
- 接下来就是初始一些数据结构
proc等 - 以上的建立起虚拟地址和物理地址的映射是通过函数
mappages()实现的,实现的大致逻辑如下- 首先通过
walk()在已经存在的页表项中检索,如果找到一个有效的页表项,则报错remap - 如果找不到(正常的情况下应该是找不到),此时建立起映射即可,也就是在页表项(第 3 级页表)设置 PPN 的值和物理页的基地址相同,同时设置权限位
- 首先通过
问题 4
关于XV6 的内存页式管理。发生中断时,用哪个页表?一个内页是多大?页目录有多少项?页表有多少项?最大支持多大的内存?画出从虚拟地址到物理地址的转换图。在XV6 中,是如何将虚拟地址与物理地址映射的(调用了哪些函数实现了哪些功能)?
3 级页表
- xv6 的页式管理,xv6 通过 3 级页表实现,具体实现如下图
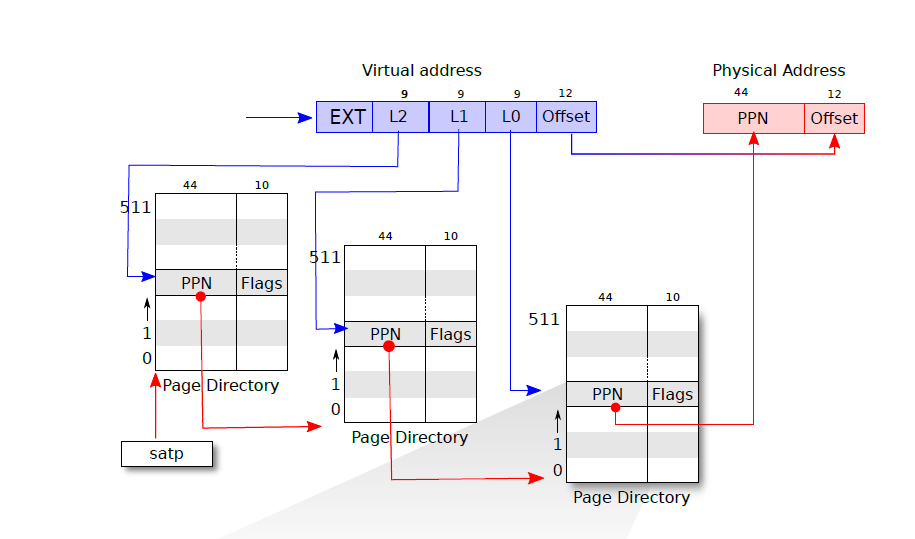
- 虚拟地址中首先保存着 4 个偏移量 L2、L1、L0、Offset
- 通过 satp 寄存器读取到第一级页表的基地址,通过 L2 找到 PPN1
- PPN1 中记录的第二级页表的基地址,通过 L1 找到 PPN2
- PPN2 记录着第三级页表的基地址,通过 L2 找到 PPN
- PPN 和 页内偏移量 Offset 组合形成最终的物理地址
- 具体是通过函数
walkaddr()实现的,其中三级页表的翻译是通过walk()实现的
1 | /* 判断是否合法并返回物理页的基地址 */ |
1 | /* 找到最后一级页表(第3级页表)对应的 PTE */ |
中断
- 发生中断时,将 CPU 上进程的第一级页表的及地址存入 stap 寄存器,同时清空 TLB
- 也就是说,将当前页表替换为触发中断的进程的页表,紧接着之后的查找都是在新的页表上执行,具体的翻译步骤就是通过上面的 3 级页表翻译
- 其中每一级页表都有 512 个页表项,支持内存大小可达 \(2^{39}\)
- 清空 TLB 的操作是由如下命令执行的
1 | static inline void sfence_vma() { |
其他
虚拟地址空间设计
- xv6-riscv 的设计和其他的设计不太一样,xv6
的设计中内核态拥有自己的一个页表,这就是说对于 xv6
来说,用户态和内核态的虚拟地址空间都可以达到 0 -
MAXVA,这样的设计的好处似乎还挺多
- 首先我们可以看到,可以分配的空间变大了
- 在内核态分配空间的时候不需要考虑和用户态是否有交集了
- 当然直接将内核态和用户态分离开也能马上实现没有交集的效果
- 当然也存在一些问题,比在在陷入内核、退出内核的时候都需要对 TLB 进行一个清空的操作,这样增大了 TLB miss 的概率,导致效率有所下降
- 用户空间的虚拟地址范围如下
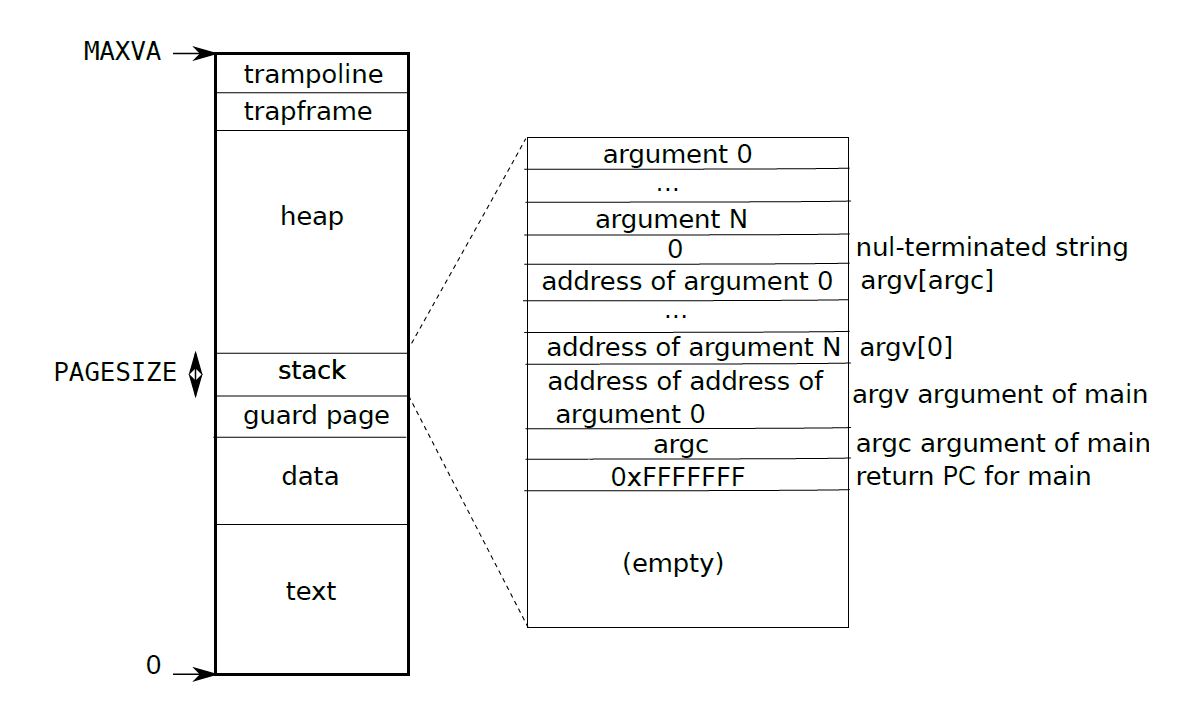
内核态的 CPU 栈与内核栈
- 一开始系统启动的时候为每一个 CPU 都分配了一个栈,这个栈是为了每个 CPU 的前期初始化操作以及调度程序准备的
- 我们可以认为在内核态下,其实是存在两个线程的,一个线程是调度线程,一个线程是由用户态的 trap 进入的
- 因此这两个线程也是需要有自己的栈的
- 所以这样的设计是没有问题的,而且在一定程度上讲确实得这么设计
参考资料
- https://pdos.csail.mit.edu/6.828/2020/xv6/book-riscv-rev1.pdf
- https://github.com/mit-pdos/xv6-riscv