数据库概论.陈立军.04.SQL 数据查询(2)
SQL 数据查询
1 | Select ... |
在线资源
- http://sqlfiddle.com
分组
1 | group by 列名 [ having 条件表达式 ] |
- group by 将表中行按指定列上值相等的原则分组,然后在每一分组上使用聚集函数,得到单一值
- having 对分组进行选择,只将聚集函数作用到满足条件的分组上
需求
- 统计每个同学的平均成绩
- 统计每个课程的平均成绩
使用
- 目标列必须是分组属性
- select 语句后面的列必须是 group by 后面的列
- 因为在 group by 之后,对每一个 group
会输出一条记录,使用其他的属性会导致每一个属性有多个值,不满足原子性
- MySQL 测试好像是可以的,不过只输出第一条记录
- 因为在 group by 之后,对每一个 group
会输出一条记录,使用其他的属性会导致每一个属性有多个值,不满足原子性
- 如果其他属性使用的是聚集函数,那么是可以的
- 列出每个学生的最高、最低、平均成绩
1 | select sno, max(grade), min(grade), avg(grade) |
- having 是对分组进行过滤
1 | /* 列出没有挂科经历同学的平均成绩 */ |
分组查询中各子句的顺序
- 列出每一年龄组中男学生(超过50人)的人数
1 | select age, count(sno) |
- 执行顺序
- where、group by、having
- 先过滤、再分组、在对分组进行选择
group_concat
1 | select dname, |
- 串接字符串的功能
- 例如上面的 select 之中的列如果不是 group by 中的属性列,把
group_concat 当作一个聚集函数,作用是把这一组内的所有数据用
,拼接成字符串
cube
- 对 group by 的扩展
- 所有的 group by 进行一个预先计算,把结果保存起来,这样在之后机型 group by 的操作的时候,很快就可以得到结果
\[ \mathrm{Cube}=\bigcup_{A_i\in A}\mathrm{group\ by} A_{i} \]
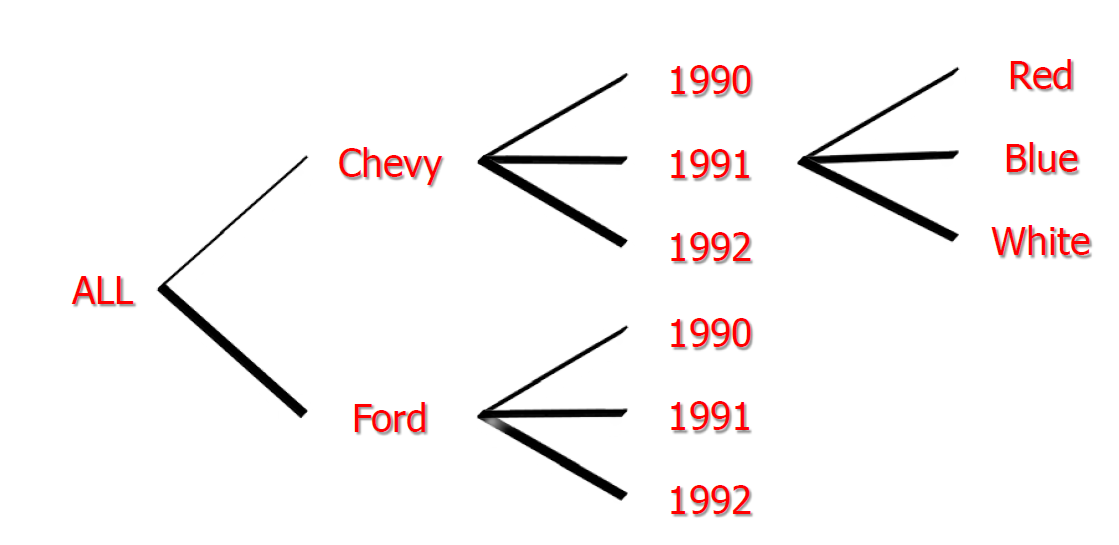
- n 个属性的 group by,一共有 \(2^n\) 个
1 | select Model,Year,Color,sum(Sales) |
- 行数计算
- (model值个数+1) x (year值个数+1) x (color值个数+1)
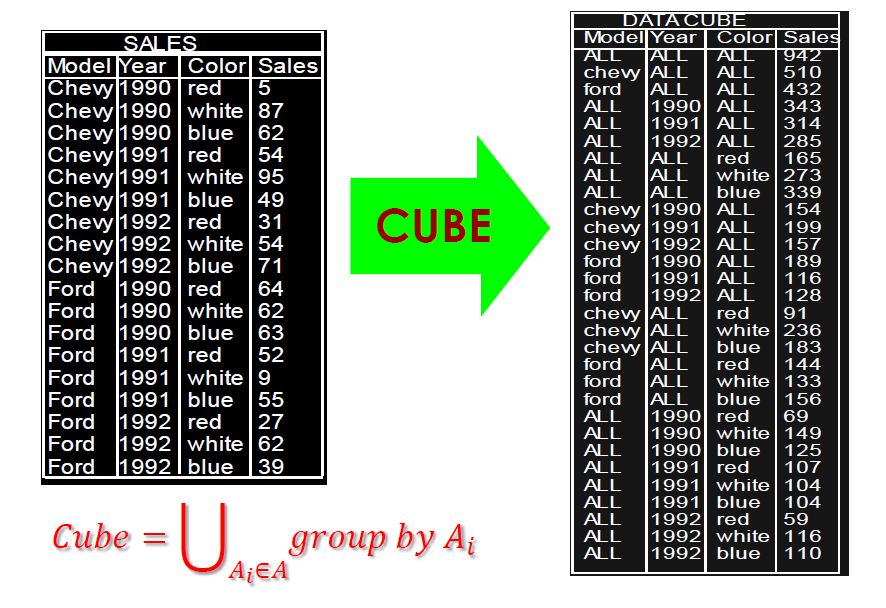
- cube 在实际过程中并不是生成 All,而是为每条记录生成一个 null
- 问题来了,怎么区分原来的 null 和生成的 null(我们需要处理成 All)
- grouping
grouping
- grouping 是一个聚合函数
- 它产生一个附加的列,当用 cube 或 rollup 运算符添加行时,附加的列输出值为 1,否则为 0
1 | select 'TotleSold' = sum(sales), |
rollup
1 | group by Model,Year,Color with rollup |
- 顺序不一样,结果就不一样
1 | group by A, B, C with rollup |
行数计算
- \(|colA|=a,|colB|=b,|colC|=c\)
- 求
group by colA, colB, colC with rollup的行数是多少 - \(a*(b*(c+1)+1)+1\)
- 相当于每一个属性增加了一个 All
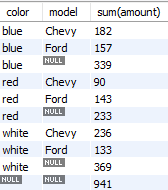
- 一个例子
1 | select color,model, sum(amount) |
如何生成多个分组语句的合并报表
1 | select model, year, null as color, sum( sales) |
- 繁琐
- 代码繁琐
- 低效
- car_sale 访问 4 遍
- 如果 group by 之间有包含关系的话,可以在另外一个基础上进行操作
- 例如
group by A在group by A, B的基础上进行
- 例如
分组属性集
- grouping sets
1 | group by grouping sets ((分组属性集1), (分组属性集2), ..., (分组属性集n)) |
- 系统可以只扫描一次,如果包含包含关系的话系统可以更加高效的执行
- 例子
1 | select model,year,color,sum(sales) |
产生分组属性集的代数操作
1 | cube(a,b) = grouping sets( |
1 | rollup(x, y, z) = grouping sets( |
1 | group by cube(a,b),rollup(x,y,z) |
如何标识合并报表中行的分组归属
- grouping_id() 函数可以标示每一行到底和哪个 group by 相关联
- 这是通过为不同的分组分配不同的整数来做到的(二进制位表示)
- 例子
- 对于grouping_id(A, B, C, D)
- 分组 (A,B,C,D) 的标识为 \(8\ast0+4\ast0+2\ast0+1\ast0=0\)
- 分组 (C) 的标识为 \(8\ast1+4\ast1+2\ast0+1\ast1=13\)
嵌套子查询
- 集合成员资格(in子查询)
- 集合之间的比较(some/all子查询)
- 集合基数的测试(exists子查询)
集合成员资格(in子查询)
1 | 表达式 [not] in (子查询) |
- 判断表达式的值是否在子查询的结果中
应用
- 列出张军和王红同学的所有信息
1 | select * |
- 列出选修了c1号课程的学生的姓名
- 效果上是等价的
- 连接操作一定不会比 in 子查询差
- 一般的数据库会试图将 in 子查询转换为连接操作
- in 子查询效率不高
- 在执行完 in 之后的操作之后,会进行一个排序的工作实现高效的查找
- 排序是个比较大的开销
1 | /* 连接操作 */ |
- 列出选修了 c1 号和 c2 号课程的学生的学号
1 | select sno |
集合之间的比较(some/all子查询)
1 | 表达式 比较运算符θ some(子查询) |
- 表达式的值至少与子查询结果中的一个值相比,满足比较运算符 θ
1 | 表达式 比较运算符θ all(子查询) |
- 表达式的值与子查询结果中的所有的值相比,都满足比较运算符θ
和 in 子查询的比较
- (\(\ne\)all) 等价于 not in
- (=all) 不等价于 in
- (=some) 不等价于 in
- (\(\ne\)some) 等价 not in
应用
- 找出平均成绩最高的学生号
1 | select sno |
- 求每个系平均成绩最高的同学
1 | select dno, X.sno |
集合基数的测试(exists子查询)
1 | [not] exists (子查询) |
- 判断子查询的结果集合中是否有任何元组存在
in 和 exists
- in 后的子查询与外层查询无关,每个子查询执行一次
- 而 exists
后的子查询与外层查询有关,需要执行多次,称之为相关子查询
- 实际查询数据库可能会做优化
- 如果有索引,并不慢
应用
- 列出选修了 c1 号课程的学生姓名
- 对每位同学探测他是否选修了 c1 课程
1 | select sname |
- 列出选修了 c1 号和 c2 号课程的学生的学号
- 先找到选修了 c1 的同学,然后再探测他是否也选修了 c2
1 | select sno |
反半连接:not in, not exists
- 集合减法
- 列出没有选修课程的学生的姓名
1 | /* not in */ |
except
1 | select sname |
left join
1 | select sname |
子查询中的属性解析匹配
- 就近匹配
- 两个表中表达相同含义的列,具有不同的名称
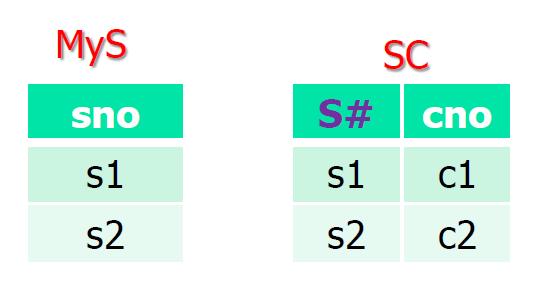
- 输出没有选 c01 课程的同学
- 错误解法
- 输出 null
1 | select sno |
not in/exists 与空值

- 如下查询返回空集(非真即假)
- in 做的是一个相等的判断
- t1 中的某个 a 元素和 null 做相等的判断,返回 null
- null 做 not 的判断,返回 null
- where 只会返回结果为 true 的值
- 因此最后返回空集
1 | select * |
- 如下查询返回 1,2(非假即真)
select * from t2 where a=b返回空
1 | select * |
- 用于实际数据库测试
1 | /* 建表 */ |
除法实现
- \(\forall \Leftrightarrow\) not
exists ... not exists
- 双重否定的形式
- 列出选修了全部课程的学生姓名
- 学生 s1 选修了所有课程
- 不存在任何一门课程 c1 所求学生 s1 没有选 c1
1 | select sname |
- 列出至少选修了 s1 号学生选修的所有课程的学生名
- s2 选修了 s1 选修的所有课程
- 不存在任何一门课程,s1 选修了但是 s2 没有选修
1 | select sname |