/* 生成 10000 行数据 */ select R1.* from R R1, R R2, R R3, R R4, R R5
但是真正要用于生成数据的话应该使用数据库提供的工具,指定概率分布生成随机数据
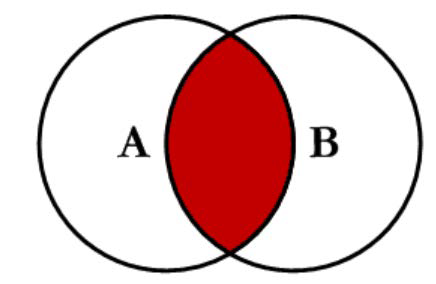
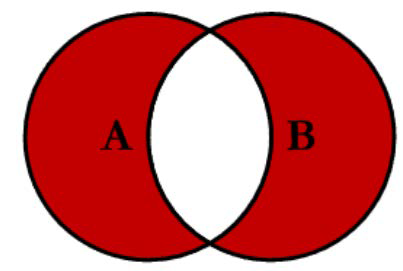
理解笛卡尔积
如下 sql 语句选择出来的结果是所有学生
1 2 3 4 5 6 7 8 9
/* 所有的学生 */ select sname, dname from S, DEPT where dname ='计算机系'
/* 计算机系的学生 */ select sname, dname from S, DEPT where dname ='计算机系'and S.dno = DEPT.dno
select子句
select xx
xx 可以为
列名
*:表示所有的属性
算术表达式
聚集函数
给出学生的所有信息
1
select*from S
* 对性能的影响
丧失使用组合索引技术的可能
中间表的规模很大
算术表达式
给出所有学生的姓名及出生日期
存储年龄并不是一个好的设计,好的设计应该是存储出生日期
把年龄作为出身日期的派生属性
1 2
select sname, 2020-age from S
将多个列组合成一个目标列
可以用作 web 前端(智能客服)
1 2
select pname +'老师的工资是'+ salary +',年龄是'+ age +',职称是'+ title from professor
from子句
from 子句列出查询的对象表
对象表
做笛卡尔积
当目标列取自多个表时,需要显式指明来自哪个关系
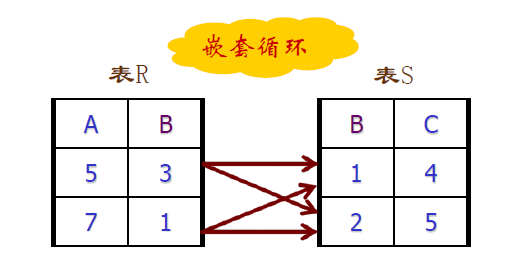
写出与 \(R(A,B)\bowtie S(B,C)\)
等价的 SQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/* 错误, 无法分辨 B 来自于哪一个表 */ select A, B, C from R, S where R.B = S.B
/* 不正确, 输出结果为 R.A, R.B, S.A, S.B */ select* from R, S where R.B = S.B
/* 正确 */ select A, R.B, C from R, S where R.B = S.B
where子句
比较运算符
1
<、<=、>、>=、=、<>
逻辑运算符
1
and、or、not
虽然不同的表达式可以表示相同的结果,但是使用不同的表达方式效率上可能不一样
某些写法,系统可能会使用索引,但是针对其他写法,系统可能不使用索引
between 子句
判断表达式的值是否在某范围内
列出工资在500~800之间的老师姓名
1 2 3
select pname from PROF where salary between500and800
between 前后两个词的大小关系
SQL Server:都可以
其他:一般得满足前面小于后面
得看数据库的具体实现
优化小窍门:使用 between 合并两个比较谓词
使用 between 来写,可能让系统有使用索引的机会
重复行的处理
SQL 缺省为保留重复行(多集),也可用关键字 all 显式指明
若要去掉重复行,可用关键字 distinct 指明
找出所有选修课程的学生
1 2
selectdistinct sno from SC
优化小窍门:只在必要的时候去重
开销比较大
怎么去重:排序,哈希
必要:业务要求
如果能够明确知道不会有重复的结果,则不需要加 distinct
优化问题
两个表
R(A,B)、S(A,C),其中A是这两个表的主码,哪些查询中的distinct可以去掉?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/* 可以去掉 */ selectdistinct R.A, S.A from R,S where R.B = S.C
/* 不能去掉 */ selectdistinct R.A from R,S where R.B = S.C
/* 可以去掉 */ /* 一行 R 最多和一行 S 对应, 否则不满足 A 为 S 的主码 */ selectdistinct R.A from R,S where R.B = S.A
输出显示顺序
order by
1
orderby 列名 [asc|desc]
按年龄升序列出学生信息,相同年龄学生按姓名降序排列
1 2 3
select* from S orderby age asc, sname desc
order by 后面出现数字,表示 select
后的第几个属性
1 2 3 4
/* 对教工按缴纳所得税的多少排序 */ select pname, salary*0.2 from PROF orderby2
允许排序的属性不是目标列
1 2 3 4
/* 按年龄顺序输出学生姓名 */ select sname from S orderby age
table
1 2 3 4 5 6 7 8 9 10 11
createtable t1 (r1 int, r2 int) insertinto t1 withrecursive aa(a,b) as ( select1, 1/* 先插入 1,1 */ unionall select a+1, cee(rand()*20) from aa where a <10 ) select*from aa
1 2 3
createtable t2 like t2 /* 表形式统一 */ insertinto t2 table t1 /* 插入数据 */ select*from t2 where (r1,r2) in (table t1) /* t2 中在 t1 内的行 */
values/row
values 表值构造器
row 行值构造器
用于简单的生成行或者表
1 2 3 4 5 6 7
/* ex 1 */ valuesrow(1,2,3), row(2,3,4)
/* ex 2 */ valuesrow(1,2,3), row(2,3,4) unionall valuesrow(3,4,5), row(4,5,6)
更名运算
1
old_name as new_name
为关系和属性重新命名
可出现在 select 和 from 子句中
as 可选
属性更名(列)
1 2 3 4
/* 输出的时候吧英文转化为中文 */ select sname '姓名' ,sex '性别', 2019-age '出生日期' from S orderby 出生日期 /* 或者 order by 3 */
关系更名(表)
例如:表的自连接
找出比 s1 学生选修 c1 课程成绩高的学生号
1 2 3 4 5 6
select S2.sno from SC as S1, SC as S2 where S1.sno ='s1' and S1.cno ='c1' and S2.cno ='c1' and S1.grade < S2.grade
连接操作
连接成分
包括两个输入关系、连接条件、连接类型
连接条件
决定两个关系中哪些元组相互匹配,以及连接结果中出现哪些属性
连接类型
决定如何处理与连接条件不匹配的元组
SQL
连接类型
inner join
left outer join
right outer join
full outer join
连接条件
on <谓词>
(R cross join S) as T
两个关系的笛卡儿积
列出所有老师的教工号、姓名、工资、所教课程号
需要保留没有授课的老师
1 2
select pno, pname, salary, cno from prof leftjoin PC on PROF.pno=PC.pno
如果不支持外连接,实现方式
1 2 3 4 5 6 7 8
/* 有教授课程的老师 + 没有教授课程的老师 */ select pno, pname, salary, cno from PROF, PC where PROF.pno=PC.pno union select pno, pname, salary, null from PROF where pno notin (select pno from PC)
注意 SQL 不删除重复列(因为 on 的条件可能不是等于)
inner join
1 2
select* from tbA innerjoin tbC on tbA.b=tbC.b
left join
1 2
select* from tbA leftjoin tbC on tbA.b=tbC.b
right join
1 2
select* from tbA rightjoin tbC on tbA.b=tbC.b
left join excluding inner
join
1 2 3
select tbA.* from tbA left tbC on tbA.b=tbC.b where tbC.b isnull
full join excluding inner
join
1 2 3 4 5 6 7
select* from tbA left tbC on tbA.b=tbC.b where tbC.b isnull union select* from tbA right tbC on tbA.b=tbC.b where tbA.b isnull
cross join
做笛卡尔积
1 2 3 4 5
select* from tbA crossjoin tbC /* 等价于 */ select* from tbA, tbC
natural join
去除重复(公共)列
1 2 3 4 5 6 7
/* ex 1*/ select* from tbA naturaljoin tbC
/* ex2 */ select* from tbA join tbC using(b)
straight_join
嵌套循环
1 2
select* from R straight_join S
多表连接
1 2 3
select* from tbA A innerjoin tbA B on A.b=B.b innerjoin tbA C on A.b=C.b
1 2 3 4
select* from tbA A join(tbA B, tbA C) on(A.b=B.b and A.b=C.b)
集合操作
默认去重,显式声明 all 才表示不去重
集合并:union(all)
集合交:intersect(all)
集合差:except(all)
优先级
intersect 的优先级高于其他集合操作的优先级
1 2
S1 intersectall S2 S1 intersect S2
求工资大于1000或者年龄大于60的教工
1 2 3 4 5 6 7
(select pno from PROF where sal>1000) unionall (select pno from PROF where age >60)
1 2 3 4
(select pno from PROF where sal>1000 or age >60)
union all 不去重
效率
第一种写法可能会让数据库使用索引
第二种写法,很多数据库看到 or 直接就不使用索引了
用集合运算实现除法
选修了所有课程的同学
1 2 3 4 5 6 7 8 9 10 11 12 13 14
select sno from S S1 where ( /* 所有的课程 */ select cno from C except /* S1 同学选修的所有课程 */ select cno from SC where S1.sno=SC.sno ) isnull
空值
很麻烦但是是必要的
1 2 3
No cat has 12 tails. A cat has one more tail than no cat. Therefore, a cat has 13 tails.
谬论,no cat 不是一个实体
C.J Date
null 是标识,不是值
包含 null 违反了关系定义
Codd 提出了两类 null
A-Mark null:未知的
T-Mark null:不适用的
但是数据库没有办法区分这两类 null
空值的逻辑计算
and
true
false
unknown
true
true
false
unknown
false
false
false
false
unknown
unknown
false
unknown
or
true
false
unknown
true
true
true
true
false
true
false
unknown
unknown
true
unknown
unknown
强度:true > unknown > false
问题
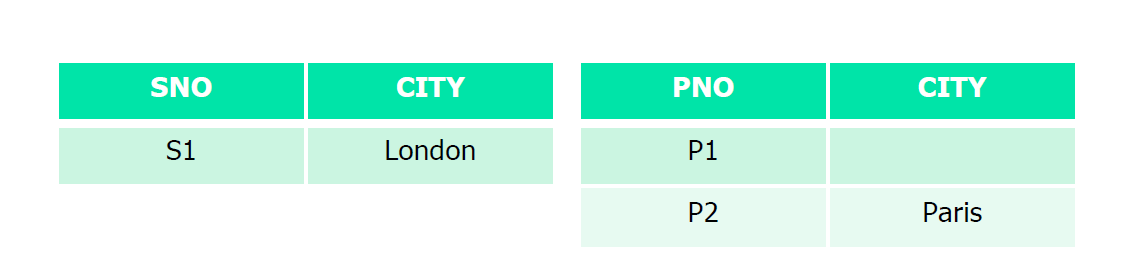
列出满足如下条件的(SNO, PNO)对:
或者供应商和零件的所在城市不同,或者零件所在城市不是 Paris
1 2 3 4
select S.SNO, P.PNO from S, P where S.CITY <> P.CITY or P.CITY <>'Paris'
返回结果为 S1, P2
不会返回结果 S1,P1
(S1.CITY = P1.CITY) 返回 null(unknown)
(P1.CITY = 'Paris') 返回 null(unknown)
而数据库只返回结果为 true 的行
问题:P1.CITY虽目前未知,但肯定是或不是Paris,总会满足查询条件之一
应该输出 S1,P1
空值测试
1
is [not] null
空值的查询
除 is [not] null 之外,空值不满足任何查找条件
如果 null 参与算术运算,则该算术表达式的值为 null
如果 null 参与比较运算,则结果可视为 unknown
例子
表中存在两行(1, 2, null), (1, 2, null)
请问 select distinct * 的输出结果是?
输出一行
可能底层的判断并不是简单的 =
找出成绩值为空的学生号
1 2 3 4
select sno from SC where grade isnull /* 不可写为 where grade = null */