0%
SQL 索引
SQL 索引定义
为什么需要索引
- 关系表是个无序集合
- 如果想要找到某一条记录需要逐行的进行扫描,开销非常大
- 连接操作是嵌套循环的,开销为 \(n^2\) 的
- 索引:希望建立起一个有序结构
- RowID:(文件号,页面号,页内偏移号)
- 索引实现的直观解释
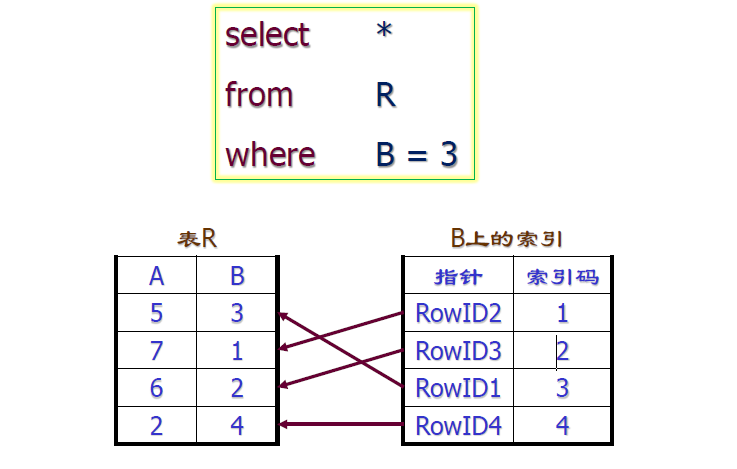
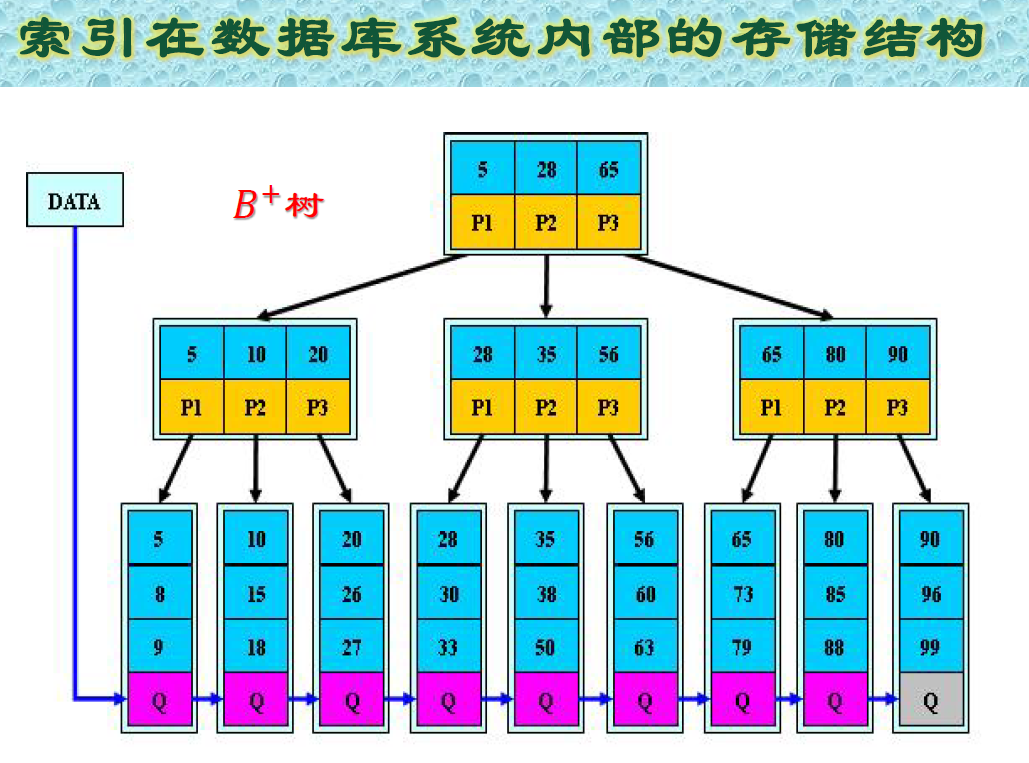
索引的作用
- 查找元组
- 表连接
- 排序
- 分组
- 保证唯一性
- 声明一个列是唯一的,系统在内部会自动创建一个唯一的索引来支持它
- 有序结构中插入元素,判断是否唯一很快
索引的定义
1
2
3
| create [unique ] index 索引名
[ using{ btree| hash } ]
on 表名(列名[asc/desc] [ , 列名 asc/desc]...)
|
asc/desc
- 索引表中索引值的排序次序,缺省为 asc
- 降序索引的用处
1
2
3
| select A, B from R order by A asc, B desc
create index my_idx on R(A asc, B desc)
|
unique
- 唯一性索引
- 不允许表中不同的行在索引列上取相同值
- 若已有相同值存在,则系统给出相关信息,不建此索引
- 系统拒绝违背唯一性的插入、更新
1
2
3
4
5
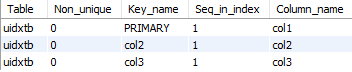
| create table uidxTb(
col1 int primary key,
col2 int unique,
col3 int unique index (col3)
)
|
InnoDB_fill_factor
- fill_factor
指定在创建索引的过程中,各索引页的填满程度
- 为何索引页要预留空间?
- 如果某个索引页填满,系统就必须花时间拆分该索引页,以便为新行腾出空间,这需要很大开销并造成索引碎片
- 新来的索引码如果恰好在某个填满的索引页,则需要进行拆分,开销比较大
索引碎片
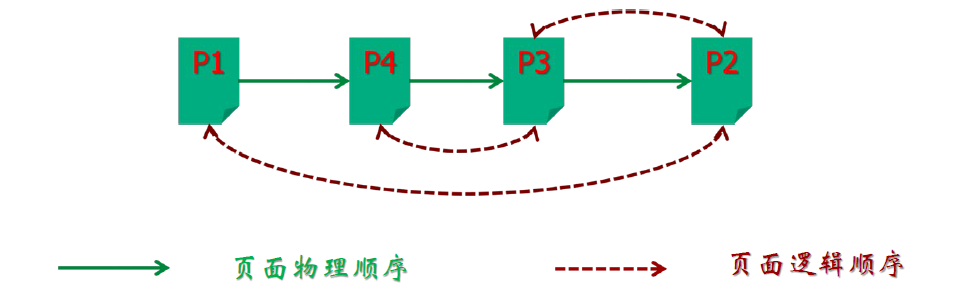
- 由于经常性的拆分操作,会导致页面逻辑顺序和物理顺序不一致的情况
- 索引碎片的负面影响?
- 如何消除索引碎片?
聚簇索引
- cluster:聚簇索引
- 表中元组按索引项的值排序并物理地聚簇在一起
- 一个基本表上只能建一个聚簇索引
- 聚簇索引使得逻辑访问顺序和物理存储顺序尽可能一致
- 聚簇索引的好处
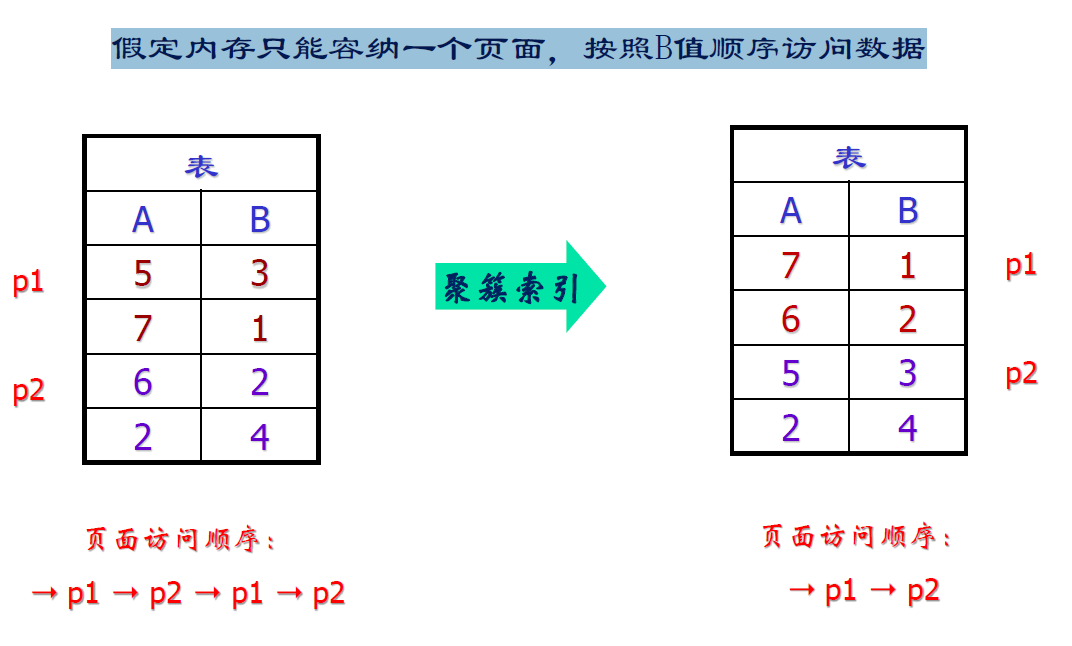
- 如果建立了聚簇索引,那么原来的表就没了,数据存储在聚簇索引的叶结点上
索引的选择度
理想选择度
- 索引的理想选择度 = 1 / 索引列的唯一值个数
- 集势:cardinality(NUM_DISTINCT)
- 选择度越小,越适合建索引
- 例如某一列上只有两个值,对其建索引只能排除一半的数据,效率不高
实际选择度
- 针对特定的查询,系统会通过评估来确定是否启用现有的索引
- 如果满足条件的行太多了,则没必要启用索引
- 索引中的行一定比原表少,但是对表查询和用索引查询效率是不一样的
- 对表查询是顺序扫描磁盘,对索引查询是随机读
- 顺序读性能比随机读高很多
- 索引的实际选择度 = 查询结果行数 / 总行数
- 早期 Oracle 设定的选择度阈值为 20%
- 现在:2%
- 估计选择度
- “=” 的索引选择度为 1 / NUM_DISTINCT
- “<>” 的索引选择度是多少?
- “>=” 的索引选择度是多少?
- 在分布不均匀的情况,如何估计选择度的大小?
- 事先做一个直方图
组合索引
- 组合索引:建立在多个属性列上的索引
- 如何排序?按照哪一个索引来排序
- 组合索引建立在 A, B, C 上, 索引码该如何排序?
- 该索引只对检索条件中包含 A 列的查询起作用
- 根据组合索引的排序原则看出来
- 只是对 A 有序,对 B、C 是无序 的
- 那为什么需要组合索引呢?
应用场景
1
| select B from R where A > 10
|
- 加快查询:对 A 建索引,而不是 B
- 更快:组合索引 A,B
- 组合属性不需要回到原表中获取第二个属性,可以直接通过属性获取到
1
| select * from R where A > 10 and B = 20
|
覆盖索引
- 把 select
中的列也包含进索引中,这样就可以完全基于索引回答查询,避免对表的访问
1
| create index my_idx on R(A) include B
|
- 与组合索引的区别
- B 值不出现在索引的中间结点上,只在叶结点上出现(B
值不参与排序)
过滤索引
- 在索引的定义中加入 where
语句,索引中只包括那些满足过滤条件的列值
- 例如在数据分布不均匀的条件下,对数据少的部分建索引
- 例子:女生很少的场景
1
| create index my_idxon S(sex) where sex = 'F'
|
- 可以用
where is not null 使得索引中不包括 null
函数索引
1
2
3
4
5
6
7
8
9
10
11
12
|
create index idx1 on S(sname)
select from S where sname='tOm'
select from S where UPPER(sname)='TOM'
create index idx2 on S(UPPER(sname))
|
1
2
3
4
5
6
7
8
9
10
11
12
| create table myTb(
x int,
y int,
index func_idx (sqrt(power(x,2)+power(y,2)))
)
create table myTb(
id char(18),
index idx1(substring(id,7,8))
)
select id from myTb
where substring(id,7,8)='20000101'
|
索引的删除
- drop index 语句不适用于通过定义 primary key 或 unique
约束创建的索引,它们必须通过除去约束来撤销
- 只能够删除用户定义的索引
索引的使用说明
- 一个表上可建多个索引
- 可以动态地定义索引,随时建立和删除索引
- 索引可以提高查询效率
- 理想化状态:不允许用户在数据操作中引用索引
- 数据的物理独立性:索引如何使用完全由系统决定
- 强行让系统使用索引
- select ... from MyTb force index(idx_name)
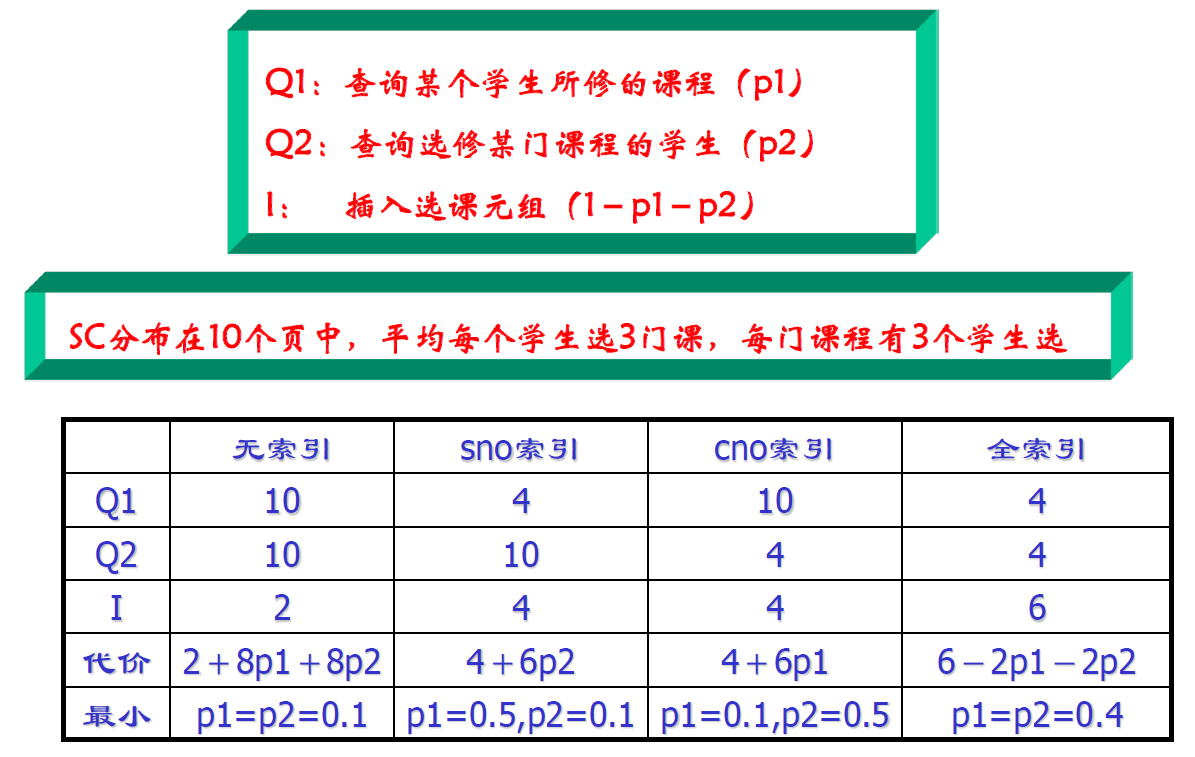
索引的选择
- 工作负载集:首先确定在这个数据集经常运行的命令
- 分析每一个查询在不同索引条件下的执行代价
- 推荐执行代价最小的索引