数据库概论.陈立军.04.SQL 简介
SQL 简介
- SQL:StruceuredQuery Languang
- 1974年,由 Boyce 和 Chamber 提出
- 1975-1979年,在 System R 上实现, 由 IBM 的 San Jose 研究室研制,称为 Sequel
SQL 语言的特点
- 语言简洁,易学易用
- 一体化:
- 集 DDL,DML,DCL 于一体
- 数据定义语言 DDL
- 数据操纵语言 DML
- 数据控制语言 DCL
- 单一的结构(关系),带来了数据操作符的统一
- 集 DDL,DML,DCL 于一体
- 面向集合的操作方式
- 一次一集合
- 高度非过程化
- 用户只需提出“做什么”,无须告诉“怎么做”,不必了解存取路径
- 两种使用方式,统一的语法结构
- 既是自含式的(用户使用)
- 又是嵌入式的(程序员使用)
SQL 的标准化
- SQL-86:“数据库语言SQL”
- SQL-89:“具有完整性增强的数据库语言SQL”,增加了对完整性约束的支持
- SQL-92:“数据库语言SQL”
- 是 SQL-89 的超集,增加了新的数据类型,更丰富的数据操作,更强的完整性、安全性支持等
- SQL:1999:增加对面向对象模型的支持
- SQL:2003:XML、Merge
- SQL:2008:truncate table、insteadof
- SQL:2011:分析函数
SQL 主要操作符
| SQL 功能 | 操作符 |
|---|---|
| 数据定义 | create, alter, drop |
| 数据查询 | select |
| 数据修改 | insert, update, delete |
| 数据控制 | grant, revoke |
SQL:数据访问的事实标准
- SQL 成为很多数据库都会提供的一些接口
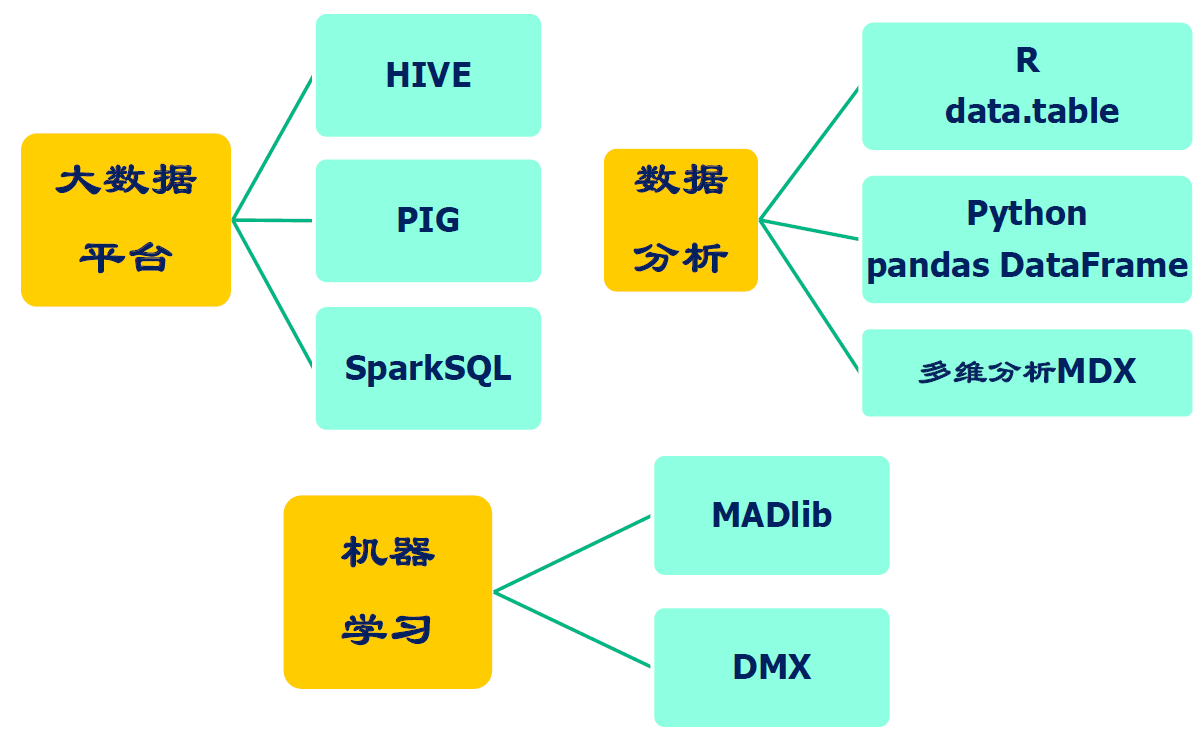
- 约定俗成的提供一个类 SQL 接口
- 自然语言转化为 SQL
SQL 模式定义
- 主要语法都是 MySQL 的语法,标识了的才是其他的,例如 SQL Server
SQL 数据定义特点
- SQL 中,任何时候都可以执行一个数据定义语句,随时修改数据库结构
- 数据库定义不断增长(不必一开始就定义完整)
- 数据库定义随时修改(不必一开始就完全合理)
- 可进行增加索引、撤消索引的实验,检验其效率影响
- 在非关系型的数据库系统中,必须在数据库装入和使用前全部完成数据库的定义。若要修改已投入运行的数据库,则需停下一切数据库活动,把数据库卸出,修改数据库定义并重新编译,再按修改过的数据库结构重新装入数据
标准 SQL 中的数据定义对象
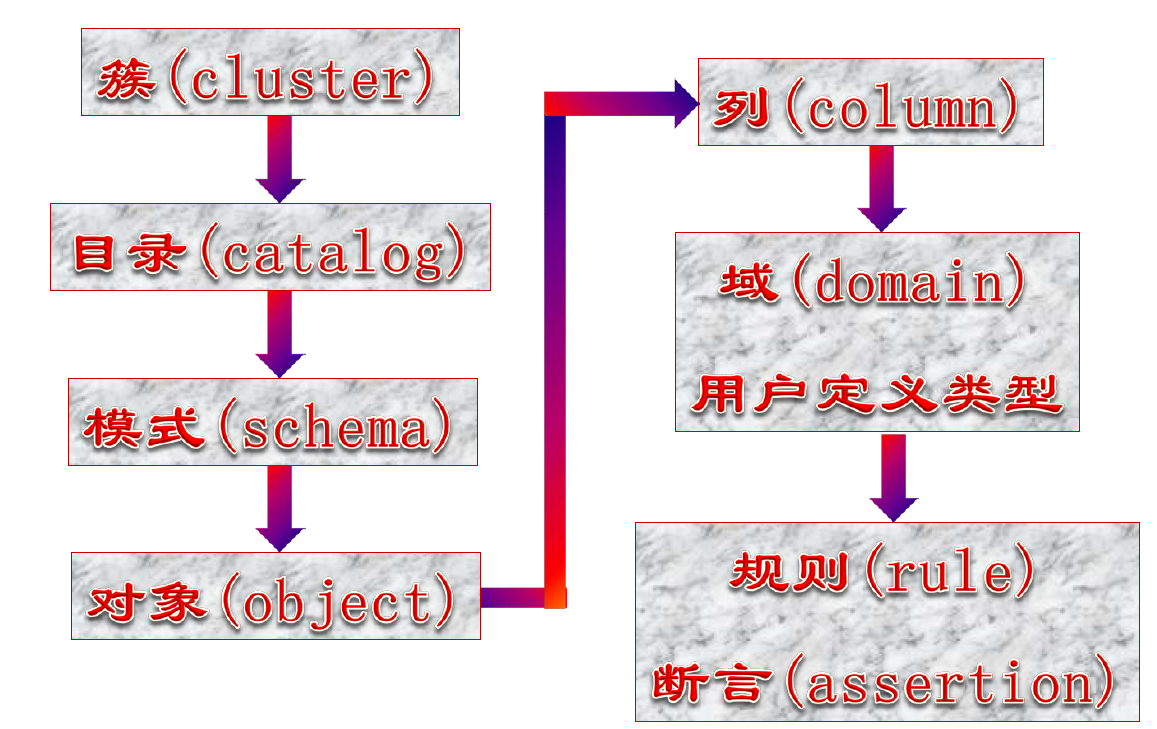
- 簇:物理概念,一个文件组
- 目录:数据库
- 模式:业务上挨得比较近的表放在一起
- 对象:表
SQL Server 定义对象
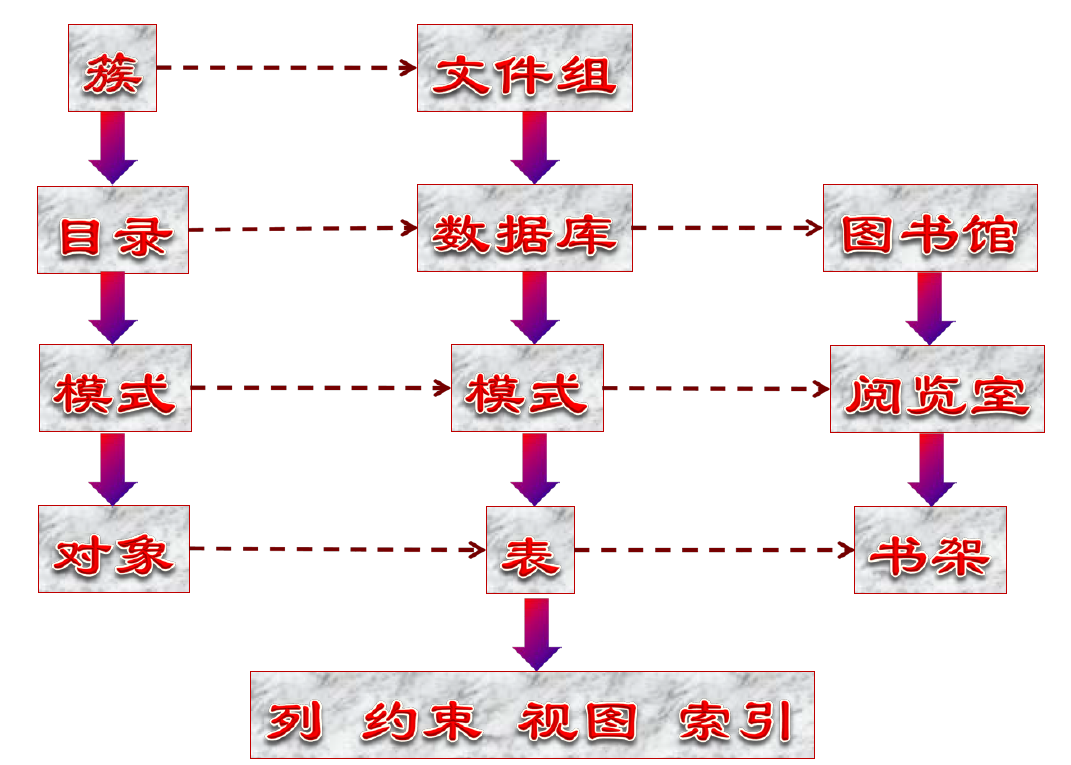
SQL Server 数据库定义
- 创建数据库
1 | create database <数据库名> |
- 最简单的创建数据库的命令
1 | create database University |
- 指定当前要使用的数据库
- 使用 use 命令,指定当前要使用的数据库
1 | use University |
SQL Server 模式定义
- 模式把对象和用户分离开来
- 对象是属于模式的,而不是属于用户的
- 创建模式
1 | create schema <模式名> |
- 对象命名
1 | <数据库>.<模式>.<表> |
MySQL 数据库定义
- MySQL 没有模式的概念
1 | create database<数据库名> |
- create database 等同于 create schema
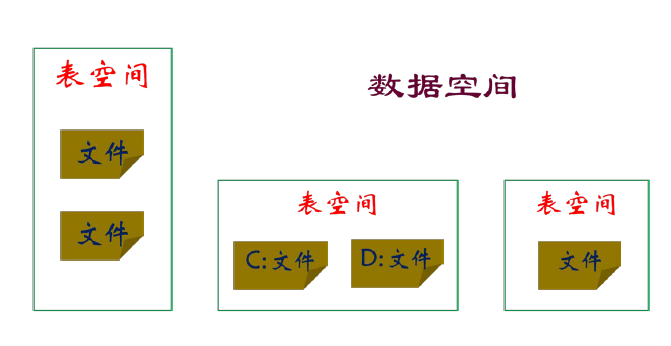
MySQL 表空间
- 逻辑概念,物理上由若干个磁盘文件构成
- 把相关的文件定义在一个表空间里
1 | /* 创建一个表空间, 存储引擎为 innodb(MySQL有两个存储引擎) */ |
- SQL Server 数据库建在文件组上面,表建在数据库上面
- MySQL 表建在表空间上面
创建基本表
1 | create table表名( |
- 创建表示例
1 | /* 学生表 */ |
SQL Server 表定义相关的字典表
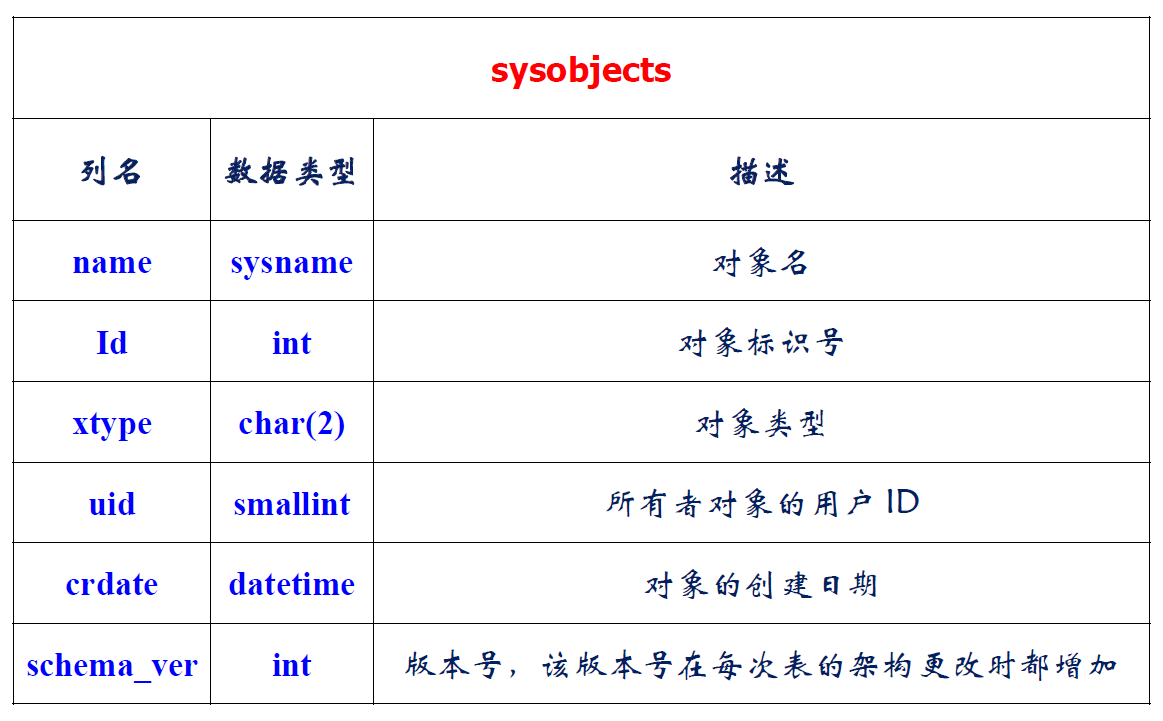
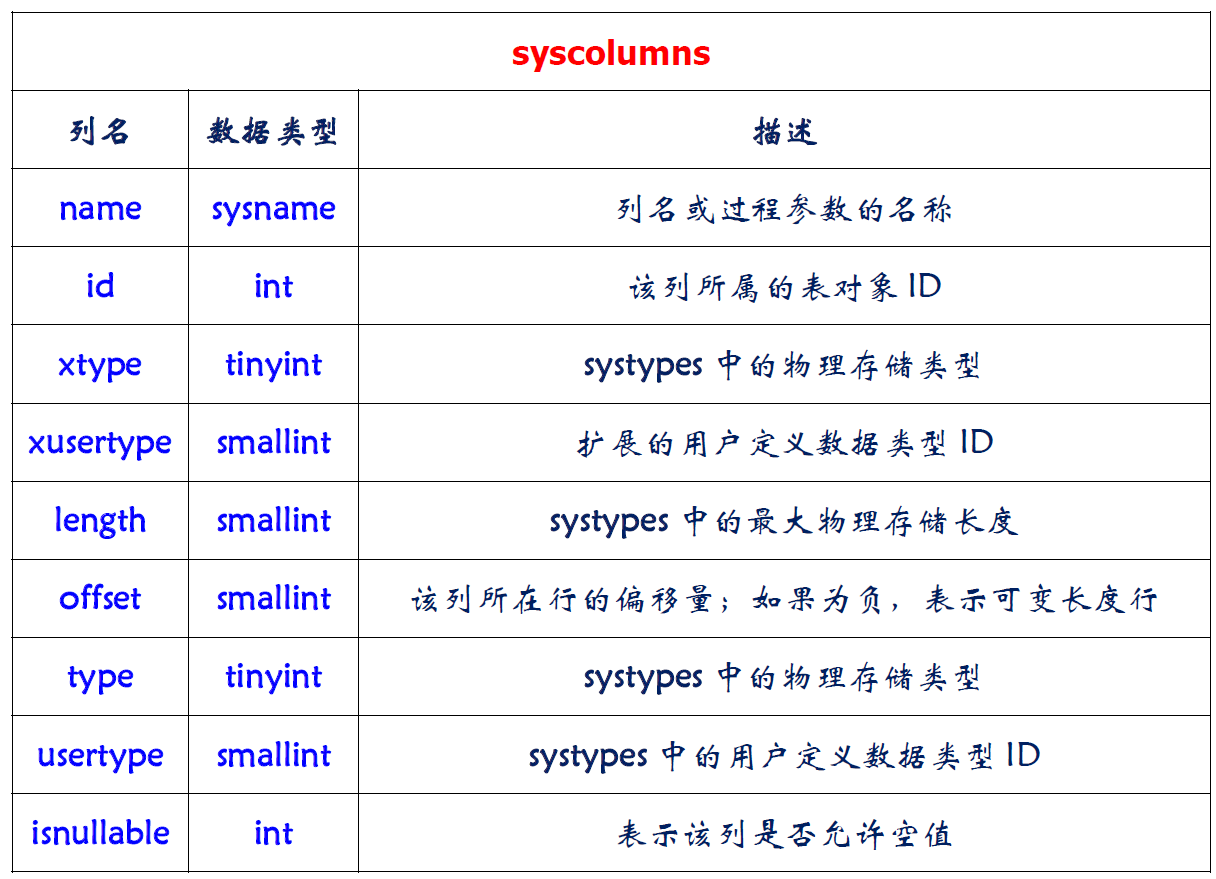
- 标准SQL中的信息视图
- 像查询普通的表那样查询数据字典
1 | INFORMATION_SCHEMA.SCHEMATA |
修改基本表
- 更改、添加、除去列和约束
1 | alter table 表名 |
- 一些问题
1 | /* 执行失败,添加的属性在原来的表里面不存在, not null 与之矛盾 */ |
- 如何定义两个相互参照的表
- 定义第一个表的时候声明外码的时候,数据库会判断外码的表是否存在
- 定义第一个表的时候先不加入参照,当建完第二个表后再加入参照

1 | create table emp(eno primary key...) |
删除表
1 | drop table 表名 |
- 删除表定义及该表的所有数据、索引、触发器、约束和权限规范
- 任何引用已删除表的视图或存储过程必须通过 drop view 或 drop procedure 语句显式除去
- drop table 不能删除由 foreign key 约束引用的表,必须先除去引用的
foreign key 约束或引用的表
- 例如上面的例子,如果删除第一个表,则会报错(第二个表在引用它)
- 所以要先去除约束
临时表与内存表
1 | /* 临时表 */ |
- 对比
| 临时表 | 内存表 | |
|---|---|---|
| 存储 | 表结构和数据都存储在内存中 | 表结构存储在磁盘中 表数据存储在内存中 |
| 会话 | 单个会话独享 | 多个会话共享 |
| 断开连接 | 表结构和表数据都没了 | 表结构和表数据都存在 |
| 服务重启 | 表结构和表数据都没了 | 表结构存在 表数据不存在 |
- 临时表可以作为临时变量存储,对于一致性要求没有那么高(并发控制可能速度更快)
- 临时表的有效范围是在一个连接之内
视图
- 创建视图
1 | create view csStudent as ( |
公共表表达式
- 只对这个查询有效
1 | with S-total(S#, value) as ( |
往表中载入数据
- 文本中载入数据
- 指定 replace,新行将代替相同码值的现有行
- 指定 ignore,跳过和现有码值相同的新行输入
- 不指定任何一个选项,出现重复码时,报错并终止
1 | load data infile 'file_name' |
SQL 数据类型
- SQL数据类型
- 数值
- 整数
- 浮点数
- 精确数
- 字符
- 定长
- 变长
- 日期
- 二进制
- 数值
整形
- tinyint(1)、smallint(2)、mediumint(3)、int(4)、bigint(8)
- int,unsigned int
1 | create table test_int( |

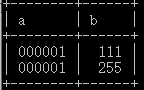
1 | insert into test_int values(1,111) |
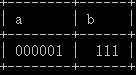
1 | select a-b from test_int |
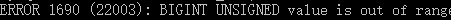
1 | /* 模式 */ |
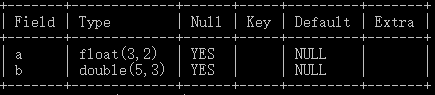
定点数与浮点数
- float(m, d):4 字节
- m 是总位数,d 是小数点后位数
- double(m ,d):8 字节
- decimal(m, d) / numeric:精确小数
- 最大位数 m 为 65,最大支持小数 d 为 30
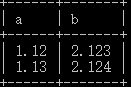
1 | create table test_float( |
1 | insert into test_float values(1.125,2.123) |
1 | create table test_decimal( |

money 数据类型
- money 使用 4 位小数存储数据,所以很容易发生小数的舍入错误
- 基本上被废弃
- 对精度敏感,则使用 decimal
字符型
- char(n),0~255,定长字符串,n字节
- varchar(n),0~65535,变长字符串,实际字符串长度
- tinytext:\(2^8\)
- text:\(2^{16}\)
- mediumtext:\(2^{24}\)
- longtext:\(2^{32}\)
枚举型
- enum('v1','v2',...):只能取一个值
- set('v1','v2',...):可以取多个值
1 | create table test_enum( |
字符集
- 字符集(characterset):字符 + 编码
- 字符序(collation):字符的比较规则
- 需要自己定义字符序,例如
- 字符按其编码比较大小
- 如果两个字符为大小写关系,则它们相等
- 需要自己定义字符序,例如
- 设置字符集
1 | show character set like 'UTF*' |
1 | use information_schema |
- 查看当前数据库的字符集
1 | show variables like 'character*' |
- 如果两个列的字符集不同,对他们作比较的时候可能会报错
1 | /* 为列和表指定字符集 */ |
二进制类型
- binary(n):255
- varbinary(n):16384
- tinyblob, blob, mediumblob, longblob
- 256, 16K,16M, 4G
1 | create table test_binary(abinary(30)) |
日期类型
| 类型名称 | 日期格式 | 日期范围 | 存储需求 |
|---|---|---|---|
| year | YYYY | 1901 2155 |
1 个字节 |
| time | HH:MM:SS | -838:59:59 838:59:59 |
3 个字节 |
| date | YYYY-MM-DD | 1000-01-01 9999-12-3 |
3 个字节 |
| datetime | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 9999-12-31 23:59:59 |
8 个字节 |
| timestamp | YYYY-MM-DD HH:MM:SS | 1980-01-01 00:00:01 UTC 2040-01-19 03:14:07 UTC |
4 个字节 |
1 | create table test_date(a date) |
1 | create table test_datetime(a datetime) |
1 | create table test_time(atime) |
SQL Server 的日期类型
- date
- 0001-1-1
- 9999-12-31
- smalldatetime
- 1900-1-1
- 2079-6-6
- datetime
- 1753-1-1
- 9999-12-31
- datetime2:由于设计问题,datetime 从 1753 开始不够用
- 0001-1-1
- 9999-12-31
- 为什么 datetime 从 1753 开始
- 英国从 1753 年开始,用的日历才和欧洲大陆统一起来
特殊类型
- XML、Json、空间数据
- 数据类型决定了数据库的适用范围,数据库支持的数据类型越多,能够支持的应用场景也越多
rowversion
- rowversion 数据类型
- 如果表中有一列被声明为 rowversion,那么只要一行被修改,该行的 rowversion 列就会发生改变 它是跨表唯一的,也即任何表的修改都会使该值递增
1 | create table verTb(val char(10),ver rowversion) |
- 作用,判断某一行是否发生修改
uniqueidentifier
- uniqueidentifier 数据类型
- 128位
- uniqueidentifier 产生跨数据库和服务器的全局唯一标识符(GUID)
- newid() 函数产生 uniqueidentifier 类型的值
- newsequentialid() 产生的 GUID 总是大于先前通过该函数生成的 GUID
- select newid() 的输出结果:DD64B592-D477-4114-8131-32E9FCB540FA
显式数据类型转换
- 将一种数据类型转换为另一种
1 | cast(表达式 as 数据类型[(数据长度)] ) |
1 | select cast(123.45 as decimal(10,4)) |
隐式数据类型转换
- 如果不指定显式的类型转换,那么在对两个不同数据类型的列值进行运算时,系统会进行隐式的类型转换,也即先将它们转换为同一个数据类型,然后再进行运算
- 注意数据类型之间的优先级
1 | select 1+'1' /* 2 */ |
1 | select iff(1=1, 'A', 88.8) |
用户定义数据类型
- 标准数据库语法
1 | create domain 域名 数据类型 |
- SQL
1 | typedef ADDRESS_LIST { |
- SQL Server
1 | create type user_DT from Sys_DT |
如何选择数据类型
定长与变长
- 变长之利:减少存储开销+元组数/页高
- 变长之弊:查询计算偏移+更新挪移数据
- 空间不够需要挪移数据
- 如果当前页面没有空间空闲,留下一个指针,指针指向其他的具体页面
- 导致的后果是,在实际读取数据的时候,需要读取更多的物理页面
- 变长之用:长短显著不一+很少发生变化
主码的选择
- 主码不能太长
- 保证其惟一性必须进行字符匹配
- 一个表的主码经常是另外一个表的外码,而外码是对主码的复制,如果主码太长的话,加上外码则会占据很大的表空间
- 表连接一般是基于主外码的,为加快查询会在主外码上建立索引,太长的主码会使得一个页面里容纳很少的索引项,从而增加查找数据时的磁盘I/O数
- 如果没有一个很好的自然码作为主码,可以增设一个人工码
- MySQL
- auto_increment:自增的数据类型
1 | create table test_incr( |
- SQL Server 中的序列号:identity
- identity[( seed, increment) ]
- 为一些没有有效主码的表提供计数器
- 有一个起始数(种子),增量值(步长)
1 | create table customer1 ( |
1 | create table customer2 ( |
- SQL Server中的序列号:sequence
1 | create sequence sequence_name as 整型 [ start with] [ increment by ] [ cycle ] |
1 | create sequence mySeq as int start with 1 increment by 1 |