XV6 源代码阅读——进程线程
说明
阅读的代码是 xv6-riscv 版本的
涉及到的文件如下
kernel
entry.S、start.c、main.c、kalloc.c、vm.c、proc.c、swtch.S、proc.h、printf.c、trap.c user
思考题
什么是进程,什么是线程?操作系统的资源分配单位和调度单位分别是什么?XV6
中的进程和线程分别是什么,都实现了吗?
进程管理的数据结构是什么?Linux、XV6
中分别叫什么名字?其中包含了哪些内容?操作系统是如何进行管理进程管理数据结构的?它们是如何初始化的?
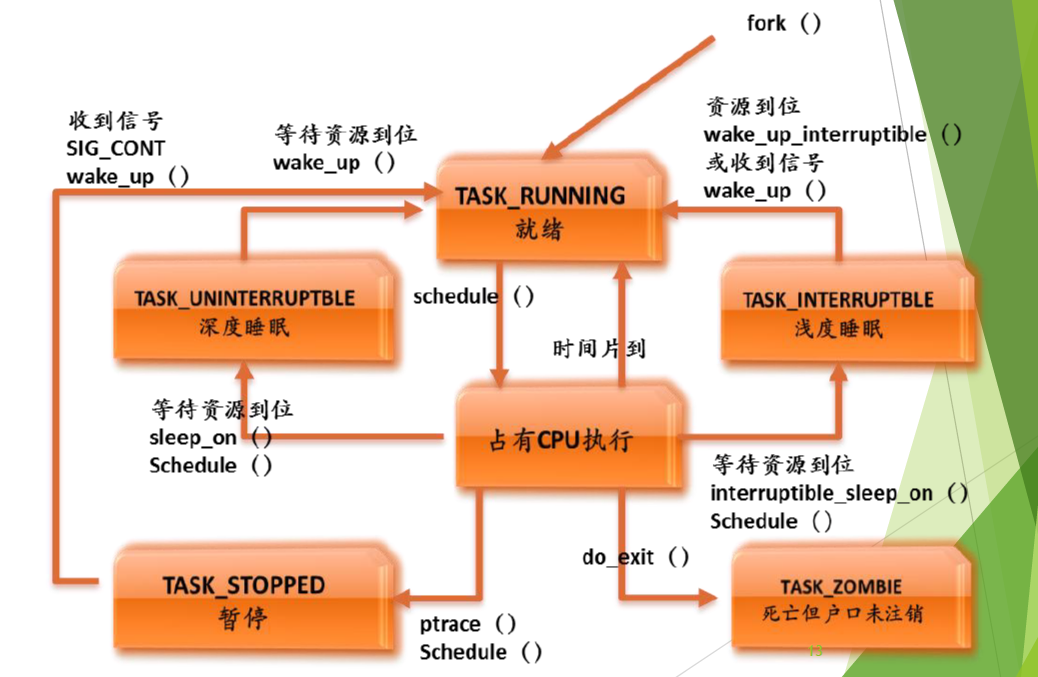
进程有哪些状态?请画出 XV6 的进程状态转化图。在Linux、XV6
中,进程的状态分别包括哪些?你认为操作系统的设计者为什么会有这样的设计思路?
如何启动多进程(创建子进程)?如何调度多进程?调度算法有哪些?操作系统为何要限制一个CPU
最大支持的进程数?XV6
中的最大进程数是多少?如何执行进程的切换?什么是进程上下文?多进程和多CPU
有什么关系?
内核态进程是什么?用户态进程是什么?它们有什么区别?
进程在内存中是如何布局的,进程的堆和栈有什么区别?
阅读报告
1. xv6 的启动流程
这一部分讲述 xv6 在启动过程中的配置以及 xv6 中第一个 shell
进程的创建过程
kernel/entry.S
当 xv6 的系统启动的时候,首先会启动一个引导加载程序(存在 ROM
里面),之后装载内核程序进内存
注意由于只有一个内核栈,内核栈部分的地址空间可以是固定,因此 xv6
启动的时候并没有开启硬件支持的 paging
策略,也就是说,对于内核栈而言,它的物理地址和虚拟地址是一样的
引导加载程序把内核代码加载到物理地址为 0x8000000 的地方(0x0 -
0x80000000 之间有 I/O 设备)
在机器模式下,CPU 从 _entry 处开始执行操作系统的代码
首先需要给内核开辟一个内核栈,从而可以执行 C 代码
每一个 CPU 都应该有自己的内核栈(xv6 最多支持 8 个
CPU),开始每个内核栈的大小为 4096 byte,地址空间向下增长
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # kernel/entry.S _entry: # 设置一个内核栈 # stack0 在 start.c 中声明, 每个内核栈的大小为 4096 byte # 以下的代码表示将 sp 指向某个 CPU 对应的内核栈的起始地址 # 也就是说, 进行如下设置: sp = stack0 + (hartid + 1) * 4096 la sp, stack0 # sp = stack0 li a0, 1024*4 # a0 = 4096 csrr a1, mhartid # 从寄存器 mhartid 中读取出当前对应的 CPU 号 # a1 = hartid addi a1, a1, 1 # 地址空间向下增长, 因此将起始地址设置为最大 mul a0, a0, a1 # a0 = 4096 * (hartid + 1) add sp, sp, a0 # sp = stack0 + (hartid + 1) * 4096 # 跳转到 kernel/start.c 执行内核代码 call start
kernel/start.c
start() 函数调用
首先进行一些在机器模式下才能进行的机器配置,然后进入 supervisor
模式
机器配置
通过调用 mret 进入supervisor mode
设置寄存器 mstatus 中的 MPP 位为 supervisor mode
设置返回地址为 main(kernel/main.c)
将所有的中断异常处理都转交给 supervisor mode
开启时钟中断
把当前 CPU 的 ID 保存在 tp 寄存器当中((thread pointer)
最后通过调用如下命令进入 supervisor mode
image-20210404123719406
kernel/main.c
main() 函数中首先进行很多属性的配置,然后通过 usetinit()
创建第一个进程
对任意一个 CPU,我们需要配置它一些系统属性
1 2 3 4 5 6 7 8 9 kvminithart(); trapinithart(); plicinithart();
对于 0 号 CPU,因为这是第一个启动的
CPU,我们需要进行一些特殊的初始化配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 consoleinit(); printfinit(); kinit(); kvminit(); kvminithart(); procinit(); trapinit(); trapinithart(); plicinit(); plicinithart(); binit(); iinit(); fileinit(); virtio_disk_init(); userinit(); __sync_synchronize(); started = 1 ;
kernel/proc.c
userinit() 函数执行的逻辑如下
调用 allocproc() 从进程表中找到一个状态为 UNUSED 的进程
找到之后,进行一些初始化配置
找不到返回 0,说明已经达到系统内置的最大进程数量
计算 pid
state 设置为 USED
调用 kalloc() 分配一个 trapframe
trapframe 的作用是在用户态进入内核态的时候保存其所有的寄存器
如果没有分配到 trapframe,那么调用 freeproc() 退出
freeproc():属性值修改为空闲、清空内存区域
调用 proc_pagetable() 分配一个用户态的页表
同时进行页表项的配置等
如果没有分配到页表,那么调用 freeproc() 退出
设置 context 寄存器 ra、sp(进程切换)
把初始化代码放入进程的页表中
一段机器代码,是一个系统调用 exec("/init"),会执行代码
user/initcode.S,开始运行 shell
只是加载,没有运行
设置 trapframe 中的寄存器 epc、sp(异常中断返回用户态)
设置进程名称为 initcode,进程工作目录为
/
设置进程状态为 RUNNABLE
最后返回 kernel/main.c 中执行进程调度程序 scheduler()
之后如果想创建进程的化,都需要通过 shell 调用 exec() 实现
2. 进程与线程
进程
为了满足并发的需求,利用进程模型通过某些机制可以实现多个程序看上去同时运行的状态
进程是程序的一次执行过程,是正在运行程序的抽象,包括程序、数据、控制块集合等
线程
线程的引入是为了解决进程占用空间多、切换开销大的问题,对一个进程实体划分为多个线程
线程是进程中的一个运行实体
基本单位
在线程出现之前,资源分配单位和调度单位都是进程
在线程出现之后,资源分配单位是进程,调度单位是线程
xv6
3. 进程管理的数据结构
xv6
对于 xv6 而言,进程管理的数据结构是 proc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 struct proc { struct spinlock lock ; enum procstate state ; void *chan; int killed; int xstate; int pid; struct proc *parent ; uint64 kstack; uint64 sz; pagetable_t pagetable; struct trapframe *trapframe ; struct context context ; struct file *ofile [NOFILE ]; struct inode *cwd ; char name[16 ]; };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int nextpid = 1 ; struct proc proc [NPROC ];struct spinlock pid_lock ; struct spinlock wait_lock ;void allocproc (void ) {}static void freeproc (struct proc *p) {}
Linux
Linux 中的进程数据结构更加复杂,表示为
task_struct,其中包含更多的控制信息
在组织上,Linux 将所有的进程组织成一个双向链表,而不是 xv6
中的数组,这样子在进程少的时候内存利用率更高,同时也提供了支持更多进程的可能。
4. 进程状态
xv6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 enum procstate { UNUSED, USED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
graph LR;
A[UNUSED];
B[USED];
C[SLEEPING];
D[RUNNABLE];
E[RUNNING];
F[ZOMBIE];
A --->|"allocproc()"| B
B --->|"freeproc()"| A
C --->|"wakeup()/kill()"| D
E --->|"sleep()"| C
B --->|"userinit()/fork()"| D
D --->|"scheduler()"| E
E --->|"yield()"| D
E --->|"exit()"| F
F --->|"wait()"| A
Linux
Linux 的状态如下,如果不算 xv6 的 UNUSED 状态的话,Linux
的状态更多,可以支持更多的操作
在调度算法上可以支持更复杂而又有效的方法
5. 进程调度
进程调度策略
xv6 的进程调度策略非常简单
对整个进程数组循环,遇见可以调度的进程(状态为 RUNNABLE),就让其上
CPU 运行(状态修改为 RUNNING)
由于系统有定时的时钟中断信号,因此这样看起来更像是 RR
轮转调度(但是也并不一致)
sleep and wakeup
1 2 void sleep (void *chan, struct spinlock *lk) {}void wakeup (void *chan) {}
sleep() 会将当前进程状态设置为 SLEEPING,同时设置等待地址为
chan,然后调用 sched() 重新进行进程调度
wakeup() 会把状态为 SLEEPIN 而且等待地址为 chan
的进程唤醒(状态设置为 RUNNABLE)
wait, exit, and kill
这里的逻辑设计很好地反映了为什么要设置这么多个状态
函数原型
1 int wait (uint64 addr) {}
wait() 从进程数组中查找是否有它的子进程正处于 ZOMBIE
状态,如果有则将其回收(状态修改为 UNUSED,将数据结构 proc 的内容归
0,内存区域填入垃圾)
kill() 只是不会讲进程直接杀死,而是将这个进程的 killed 设置为 1
,同时修改其状态
如果是 SLEEPING 状态的话,将其状态设置为 RUNNABLE
其余不做处理,因为它们总会到达 RUNNING 的状态
当一个进程转变为被重新调度的时候,必然会经过 usertrap()
返回用户态,再返回之前检查它的 killed 是否非 0,如果非 0,则调用
exit(-1) 退出
exit() 会回收进程的资源,同时将进程的状态设置为 ZOMBIE
同时如果该进程还有子进程的话,会把所有的子进程转交给 init 进程
以上的设计就很好的解决了问题(资源回收、父子进程间的联系)
6. 进程上下文切换
内核更像是一个多线程的模型,有两个并发的线程
一个是我们的调度程序,始终运行在内核态
另外一个就是常规的可以运行在用户态、以及经过异常中断进入到内核态的程序
调度程序和另一个程序通过 swtch() 实现轮流执行
swtch(&a, &b) 将当前的上下文存入 a,然后从 b
中读出新的上下文,这样的效果就相当于是上下文切换,还是在一个进程里,但是执行的代码区域已经不一样了
通过 swtch 可以实现线程的切换
通过调用 swtch(&c->context, &p->context)
将现在的上下文保存到 c->context 中,然后从 p->context
读出新的上下文,实现了线程的切换
如果想要切换回原来的线程,只需要从 c->context
中读入原来的上下文,把当前上下文保存到 p->context 即可
例子:xv6 启动的时候
启动的时候在调用 allocproc() 的时候,进行了如下的设置
1 2 p->context.ra = (uint64)forkret; p->context.sp = p->kstack + PGSIZE;
当代码执行到 scheduler() 的时候,调用 swtch(&c->context,
&p->context) ,会将上下文切换到
forkret(),也就是从内核态返回到用户态的代码区域,进行用户态代码的执行,也就是执行一开始保存的
exec("./init") 代码
而当用户态程序自己调用 yield() 或者由于时钟信号调用了 yield()
之后,通过调用 swtch(&p->context, &mycpu()->context)
可以实现重新进入 scheduler() 程序,重新进行进程的调度
参考资料
https://pdos.csail.mit.edu/6.828/2019/xv6/book-riscv-rev0.pdf
https://github.com/mit-pdos/xv6-riscv
https://zhuanlan.zhihu.com/p/164394603
课程 PPT